推荐
专栏
教程
课程
飞鹅
本次共找到1442条
量化模型
相关的信息
Easter79
•
4年前
superword开源项目中的定义相似规则
两个词之间的关系有同义、反义、近义(有多近?)、相关(有多相关?)等等。我们如何来判断两个词之间的关系呢?利用计算机能自动找出这种关系吗?当然可以,不仅能找出来,而且还能量化出有多近和有多相关。本文描述了superword(https://www.oschina.net/action/GoToLink?urlhttps%3A%2F%2Fgithub
Stella981
•
4年前
MapReduce编程模型和计算框架架构原理
Hadoop解决大规模数据分布式计算的方案是MapReduce。MapReduce既是一个编程模型,又是一个计算框架。也就是说,开发人员必须基于MapReduce编程模型进行编程开发,然后将程序通过MapReduce计算框架分发到Hadoop集群中运行。我们先看一下作为编程模型的MapReduce。MapReduce编程模型
天翼云开发者社区
•
2年前
大语言模型微调数据竞赛,冠军!
近日,天池FTDataRanker竞赛落下帷幕,天翼云智能边缘事业部AI团队(后称天翼云AI团队)凭借在大语言模型(LLM)训练数据增强方面的卓越研究,荣获大语言模型微调数据竞赛——7B模型赛道冠军。
小万哥
•
2年前
技术写作概述:内容分析、平台和转化追踪以及内容老化
内容分析内容分析是一种技术作家用来解释和量化文本数据的研究方法。它涉及从不同来源的文本中编码和识别主题或模式的系统过程,这些来源包括书籍、博客、文章或其他文档类型。其主要目标是提供主观解释的、但有效且可重复的、从数据中得出的推论。这种技术有助于确定所讨论的
京东云开发者
•
12个月前
业务监控-京东物流Promise实践与探索
作者:京东物流冯志文一、业务监控的意义指标是一个被定义的数值,用来对事实进行量化和抽象。作为技术人员来说,我们需要共同考虑技术指标和业务指标。1)技术指标技术指标定义了服务可用率、性能TP99、调用量等技术指标。这些指标能够帮助开发人员深入了解系统的运行状
近屿智能
•
11个月前
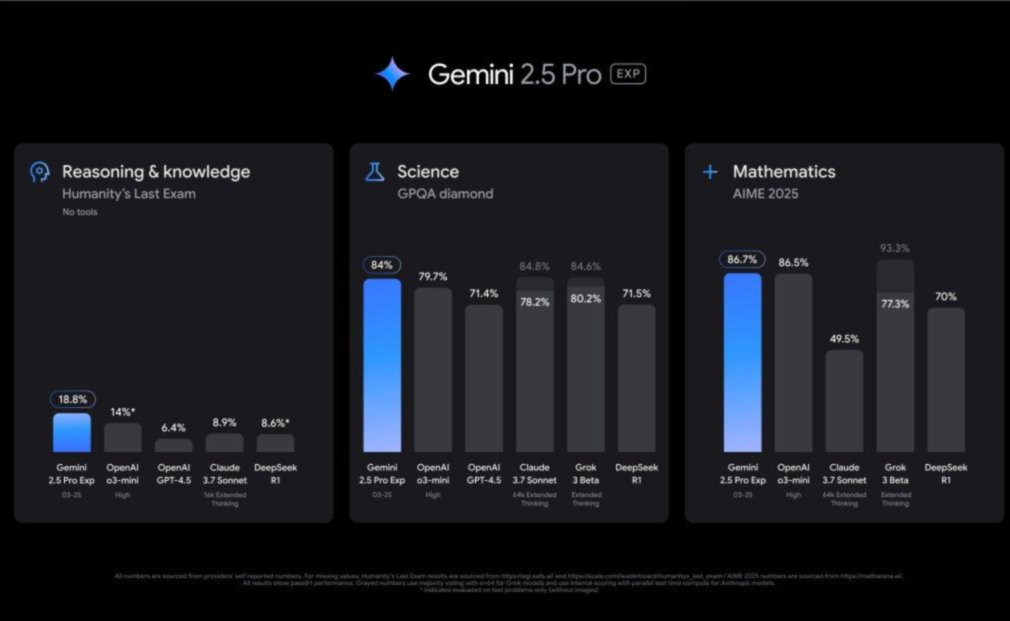
谷歌最强模型 Gemini 2.5 Pro 发布,近屿智能带你学AI大模型
近日,谷歌宣布推出“最智能的AI模型”Gemini2.5系列,实验版Gemini2.5Pro是该系列上线的首款推理模型。这个模型专为复杂任务打造,推理能力强大,一经诞生就横扫各大榜单、拿下各类TOP1,还创下了历史上最大分数飞跃纪录。目前,该模型已在Goo
上海近屿智能
•
4个月前
告别简历“海啸”!AI得贤招聘官AI面试智能体,精准筛选零成本破局
展位成本持续攀升,线下活动耗时耗力,招聘效果却难以量化。传统招聘模式正让HR陷入一场投入与回报极不对等的长期消耗战。海量简历如潮水般涌来,真正合适的人才却寥寥无几。招聘会、猎头费用不断吞噬着招聘预算,而招到的人是否真正胜任,往往要等到入职后才见分晓。在主观
近屿智能
•
3个月前
当 AI 成为招聘第一关,你准备好了吗
当AI成为招聘第一关,你准备好了吗未来招聘格局已悄然改变:AI不会完全取代人工,但招聘第一关必然交给AI。AI负责基础筛选,对知识、技能、性格、态度进行量化评估,触碰红线者直接淘汰;后续由传统人工开展实操性测试,考察团队融合度与匹配度,两者分工明确、高效协
linbojue
•
3星期前
box-sizing: border-box 详解
🎯核心作用boxsizing:borderbox改变了CSS盒模型的计算方式,让元素的宽度和高度包含内边距(padding)和边框(border),而不是仅仅内容区域。📊盒模型对比默认盒模型(contentbox)css体验AI代码助手代码解读复制代码
数据堂
•
2年前
大模型数据集:探索新维度,引领AI变革
一、引言在人工智能(AI)的快速发展中,大型预训练模型如GPT、BERT等已经取得了令人瞩目的成果。这些大模型的背后,离不开规模庞大、质量优良的数据集的支撑。本文将从不同的角度来探讨大模型数据集的新维度,以及它们如何引领AI的变革。二、大模型数据集的新维度
1
•••
13
14
15
•••
145