推荐
专栏
教程
课程
飞鹅
本次共找到10000条
数据分析
相关的信息
黎明之道
•
4年前
Pandas数据载入与预处理(详细的数据Python处理方法)
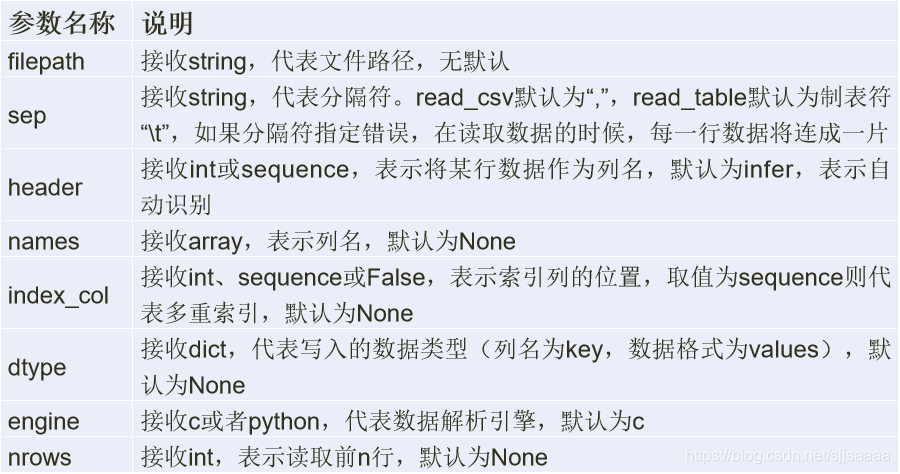
Pandas数据载入与预处理对于数据分析而言,数据大部分来源于外部数据,如常用的CSV文件、Excel文件和数据库文件等。Pandas库将外部数据转换为DataFrame数据格式,处理完成后再存储到相应的外部文件
Aidan075
•
4年前
说实话,数据分析师真不用先学Python!
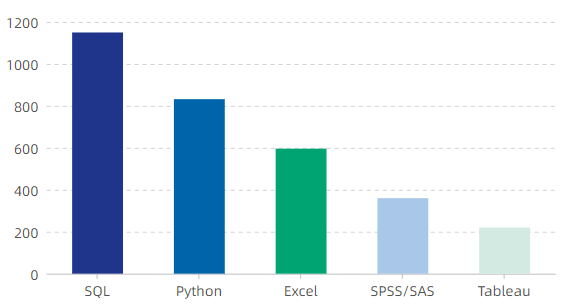
大家好,我是小五🚀经常有朋友问我一个问题,转行数据分析师应该先学什么呀?抛开统计学、业务方法论,单拿出技能工具来说的话,我更希望大家先学习SQL。为了证实我的看法,我爬取了招聘网站,并做了一张柱状图来展示互联网公司对数据分析师的技能要求。可以看到对于一名(准)数据分析师来说,SQL确实是最需要掌握的技能。当然,大家对于各种工具也不必追求全部掌握,它们的目的都
Aidan075
•
4年前
分享5个高效的pandas函数!
熟练掌握pandas函数都能帮我们在数据分析过程中节省时间。pandas还有很多让人舒适的用法,这次就为大家介绍5个pandas函数!本文来源towardsdatascience,作者SonerYıldırım,由Python大数据分析编译。1\.explodeexplode用于将一行数据展开成多行。比如说dataframe中某一行其中一个元素包含多个同
Wesley13
•
4年前
TIMER做免疫浸润分析(临床意义)
生信论文的套路1.ONCOMINE从全景、亚型两个维度做表达差异分析;2.临床标本从蛋白水平确认(或HPA数据库),很重要;3.KaplanMeierPlotter从临床意义的角度阐明其重要性;4.cBioportal数据库做基因组学的分析(机制一);5.STRING互作和
Wesley13
•
4年前
TIMER做差异分析散点图
生信论文的套路1.ONCOMINE从全景、亚型两个维度做表达差异分析;2.临床标本从蛋白水平确认(或HPA数据库),很重要;3.KaplanMeierPlotter从临床意义的角度阐明其重要性;4.cBioportal数据库做基因组学的分析(机制一);5.STRING互作和
Stella981
•
4年前
KM plotter生存分析和相关性分析(临床意义)
生信论文的套路1.ONCOMINE从全景、亚型两个维度做表达差异分析;2.临床标本从蛋白水平确认(或HPA数据库),很重要;3.KaplanMeierPlotter从临床意义的角度阐明其重要性;4.cBioportal数据库做基因组学的分析(机制一);5.STRING互作和
Stella981
•
4年前
Flink简单项目整体流程
项目概述CDN热门分发网络,日志数据分析,日志数据内容包括aliyunCNE17/Jul/2018:17:07:500800223.104.18.110v2.go2yd.com17168接入的数据类型就是日志离线:FlumeHDFS实时: Kafka
Stella981
•
4年前
KM plotter绘制生存曲线(临床意义)
生信论文的套路1.ONCOMINE从全景、亚型两个维度做表达差异分析;2.临床标本从蛋白水平确认(或HPA数据库),很重要;3.KaplanMeierPlotter从临床意义的角度阐明其重要性;4.cBioportal数据库做基因组学的分析(机制一);5.STRING互作和
子桓
•
2年前
Java性能分析软件分享
Java性能分析软件分享JProfiler13mac激活啦,适用于Java开发人员和企业用户,可帮助他们识别和解决Java应用程序中的性能问题,提高应用程序的性能和稳定性。JDBC,JPA和NOSQL的数据库分析数据库调用是业务应用程序中性能问题的主要原因
京东云开发者
•
5个月前
如何秒级实现接口间“幂等”补偿:一款轻量级仿幂等数据校正处理辅助工具
导语本文分析了在网络超时场景下,RPC服务调用数据一致性的问题,对于接口无幂等、接口幂等失效情况下,对异常数据快速处理做了分析思考和尝试,开发了一款轻量级仿幂等数据校正处理辅助工具。该工具可以MOCK或SPY服务调用,不限于RPC接口,进程内的方法调用也支
1
•••
14
15
16
•••
1000