项目概述
CDN热门分发网络,日志数据分析,日志数据内容包括
aliyun
CN
E
[17/Jul/2018:17:07:50 +0800]
223.104.18.110
v2.go2yd.com
17168
接入的数据类型就是日志
离线:Flume==>HDFS
实时: Kafka==>流处理引擎==>ES==>Kibana
数据查询
接口名
功能描述
汇总统计查询
峰值带宽
总流量
总请求数
项目功能
- 统计一分钟内每个域名访问产生的流量,Flink接收Kafka的数据进行处理
- 统计一分钟内每个用户产生的流量,域名和用户是有对应关系的,Flink接收Kafka的数据进行处理+Flink读取域名和用户的配置数据(在MySQL中)进行处理
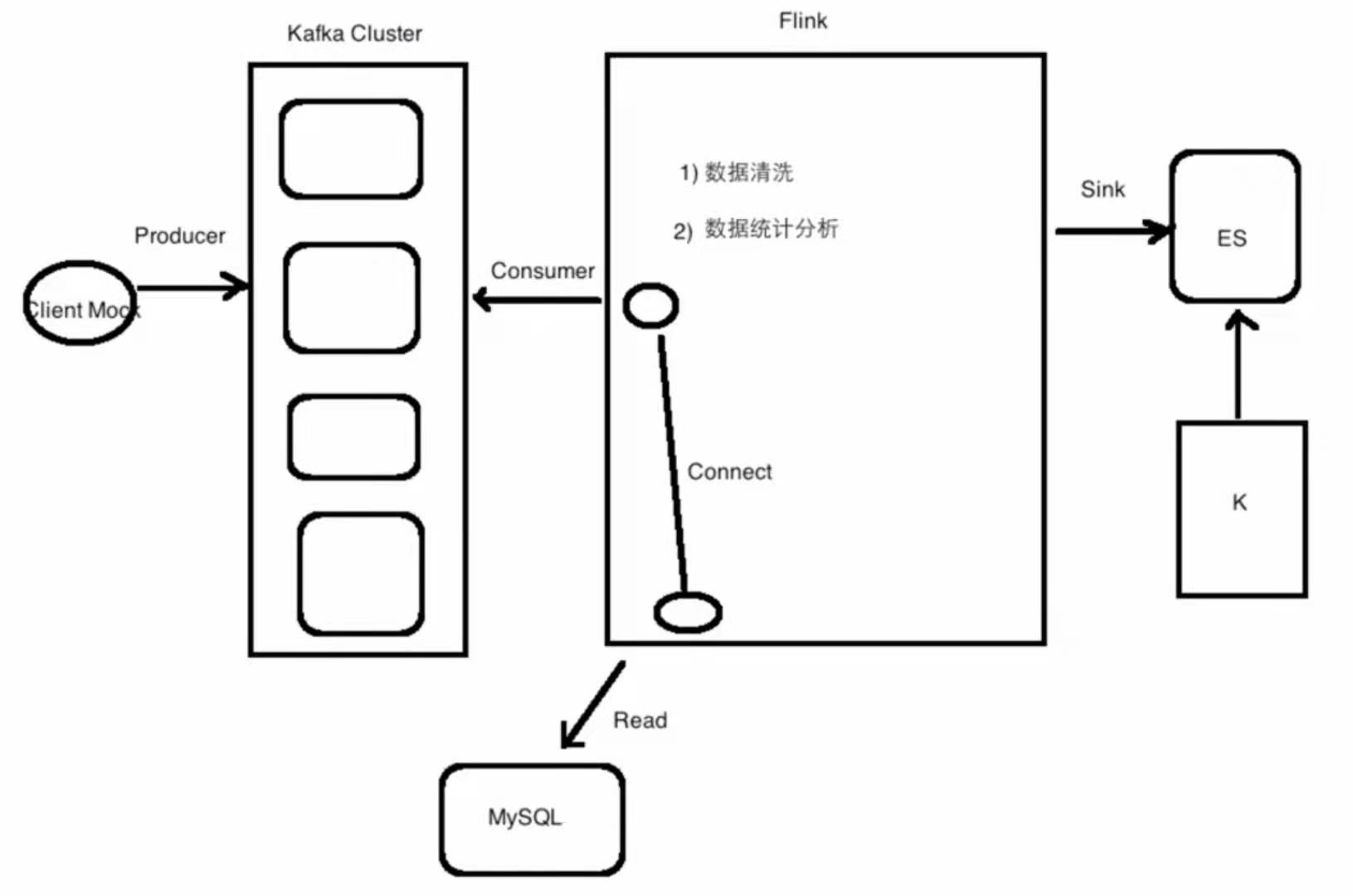
项目架构
Mock数据
@Component @Slf4j public class KafkaProducer { private static final String TOPIC = "pktest"; @Autowired private KafkaTemplate<String,String> kafkaTemplate; @SuppressWarnings("unchecked") public void produce(String message) { try { ListenableFuture future = kafkaTemplate.send(TOPIC, message); SuccessCallback<SendResult<String,String>> successCallback = new SuccessCallback<SendResult<String, String>>() { @Override public void onSuccess(@Nullable SendResult<String, String> result) { log.info("发送消息成功"); } }; FailureCallback failureCallback = new FailureCallback() { @Override public void onFailure(Throwable ex) { log.error("发送消息失败",ex); produce(message); } }; future.addCallback(successCallback,failureCallback); } catch (Exception e) { log.error("发送消息异常",e); } }
@Scheduled(fixedRate \= 1000 \* 2)
public void send() {
StringBuilder builder = new StringBuilder();
builder.append("aliyun").append("\t") .append("CN").append("\t") .append(getLevels()).append("\t") .append(new SimpleDateFormat("yyyy-MM-dd HH:mm:ss") .format(new Date())).append("\t") .append(getIps()).append("\t") .append(getDomains()).append("\t") .append(getTraffic()).append("\t"); log.info(builder.toString()); produce(builder.toString()); }
_/\*\*
_ * 生产Level数据 * _@return
_ _*/
_ private String getLevels() {
List
_/\*\*
_ * 生产IP数据 * _@return
_ _*/
_ private String getIps() {
List
_/\*\*
_ * 生产域名数据 * _@return
_ _*/
_ private String getDomains() {
List
_/\*\*
_ * 生产流量数据 * _@return _ _*/ _ private int getTraffic() { return new Random().nextInt(10000); } }
关于Springboot Kafka其他配置请参考Springboot2整合Kafka
打开Kafka服务器消费者,可以看到
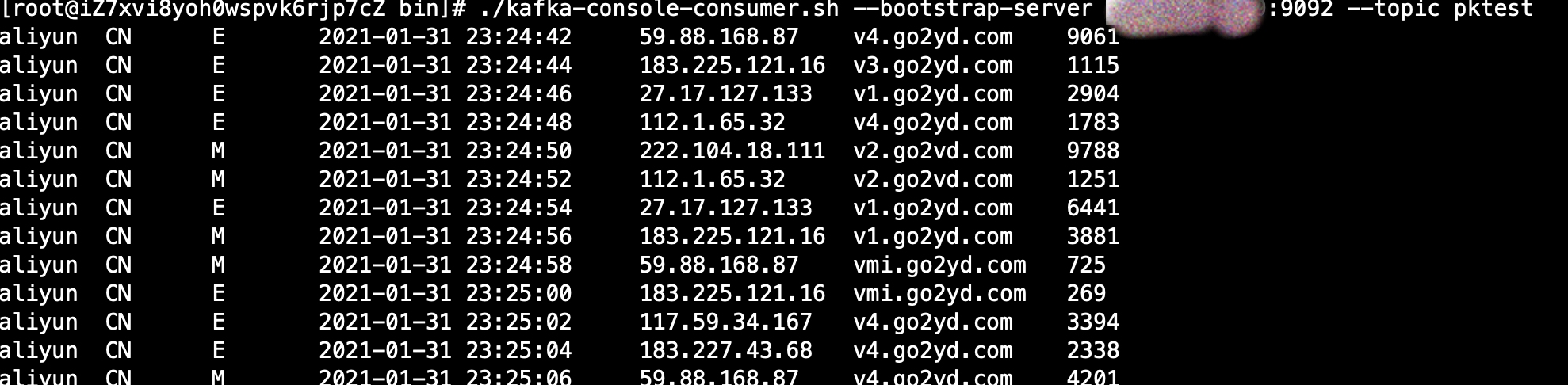
说明Kafka数据发送成功
Flink消费者
public class LogAnalysis {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
String topic = "pktest";
Properties properties = new Properties();
properties.setProperty("bootstrap.servers","外网ip:9092");
properties.setProperty("group.id","test");
DataStreamSource
接收到的消息
aliyun CN M 2021-01-31 23:43:07 222.104.18.111 v1.go2yd.com 4603
aliyun CN E 2021-01-31 23:43:09 222.104.18.111 v4.go2yd.com 6313
aliyun CN E 2021-01-31 23:43:11 222.104.18.111 v2.go2vd.com 4233
aliyun CN E 2021-01-31 23:43:13 222.104.18.111 v4.go2yd.com 2691
aliyun CN E 2021-01-31 23:43:15 183.225.121.16 v1.go2yd.com 212
aliyun CN E 2021-01-31 23:43:17 183.225.121.16 v4.go2yd.com 7744
aliyun CN M 2021-01-31 23:43:19 175.147.222.190 vmi.go2yd.com 1318
数据清洗
数据清洗就是按照我们的业务规则把原始输入的数据进行一定业务规则的处理,使得满足我们业务需求为准
@Slf4j public class LogAnalysis {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); String topic = "pktest";
Properties properties = new Properties();
properties.setProperty("bootstrap.servers","外网ip:9092");
properties.setProperty("group.id","test");
DataStreamSource
运行结果
(1612130315000,v1.go2yd.com,533)
(1612130319000,v4.go2yd.com,8657)
(1612130321000,vmi.go2yd.com,4353)
(1612130327000,v1.go2yd.com,9566)
(1612130329000,v2.go2vd.com,1460)
(1612130331000,vmi.go2yd.com,1444)
(1612130333000,v3.go2yd.com,6955)
(1612130337000,v1.go2yd.com,9612)
(1612130341000,vmi.go2yd.com,1732)
(1612130345000,v3.go2yd.com,694)
Scala代码
import java.text.SimpleDateFormat import java.util.Properties
import org.apache.flink.api.common.serialization.SimpleStringSchema import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer import org.slf4j.LoggerFactory import org.apache.flink.api.scala._
object LogAnalysis { val log = LoggerFactory.getLogger(LogAnalysis.getClass)
def main(args: Array[String]): Unit = { val env = StreamExecutionEnvironment._getExecutionEnvironment _ val topic = "pktest" val properties = new Properties properties.setProperty("bootstrap.servers", "外网ip:9092") properties.setProperty("group.id","test") val data = env.addSource(new FlinkKafkaConsumer[String](topic, **new** SimpleStringSchema, properties)) data.map(x => { val splits = x.split("\t") val level = splits(2) val timeStr = splits(3) var time: Long = 0l try { time = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss").parse(timeStr).getTime }catch { case e: Exception => { log.error(s"time转换错误: **$**timeStr",e.getMessage) } } val domain = splits(5) val traffic = splits(6) (level,time,domain,traffic) }).filter(_._2 != 0) .filter(_._1 == "E") .map(x => (x._2,x._3,x._4.toLong)) .print().setParallelism(1) env.execute("LogAnalysis") } }
数据分析
现在我们要分析的是在一分钟内的域名流量
@Slf4j public class LogAnalysis {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);
String topic = "pktest";
Properties properties = new Properties();
properties.setProperty("bootstrap.servers","外网ip:9092");
properties.setProperty("group.id","test");
DataStreamSource
@Override
public long extractTimestamp(Tuple3<Long, String, Long> element, long previousElementTimestamp) { Long timestamp = element.getField(0); currentMaxTimestamp = Math.max(timestamp,currentMaxTimestamp); return timestamp; } }).keyBy(x -> (String) x.getField(1)) .timeWindow(Time.minutes(1)) //输出格式:一分钟的时间间隔,域名,该域名在一分钟内的总流量 .apply(new WindowFunction<Tuple3<Long,String,Long>, Tuple3<String,String,Long>, String, TimeWindow>() { @Override public void apply(String s, TimeWindow window, Iterable<Tuple3<Long, String, Long>> input, Collector<Tuple3<String, String, Long>> out) throws Exception { List<Tuple3<Long,String,Long>> list = (List) input; Long sum = list.stream().map(x -> (Long) x.getField(2)).reduce((x, y) -> x + y).get(); SimpleDateFormat format = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss"); out.collect(new Tuple3<>(format.format(window.getStart()) + " - " + format.format(window.getEnd()),s,sum)); } }) .print().setParallelism(1); env.execute("LogAnalysis"); } }
运行结果
(2021-02-01 07:14:00 - 2021-02-01 07:15:00,vmi.go2yd.com,6307)
(2021-02-01 07:15:00 - 2021-02-01 07:16:00,v4.go2yd.com,15474)
(2021-02-01 07:15:00 - 2021-02-01 07:16:00,v2.go2vd.com,9210)
(2021-02-01 07:15:00 - 2021-02-01 07:16:00,v3.go2yd.com,190)
(2021-02-01 07:15:00 - 2021-02-01 07:16:00,v1.go2yd.com,12787)
(2021-02-01 07:15:00 - 2021-02-01 07:16:00,vmi.go2yd.com,14250)
(2021-02-01 07:16:00 - 2021-02-01 07:17:00,v4.go2yd.com,33298)
(2021-02-01 07:16:00 - 2021-02-01 07:17:00,v1.go2yd.com,37140)
Scala代码
import java.text.SimpleDateFormat import java.util.Properties
import org.apache.flink.api.common.serialization.SimpleStringSchema import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer import org.slf4j.LoggerFactory import org.apache.flink.api.scala._ import org.apache.flink.streaming.api.TimeCharacteristic import org.apache.flink.streaming.api.functions.AssignerWithPeriodicWatermarks import org.apache.flink.streaming.api.scala.function.WindowFunction import org.apache.flink.streaming.api.watermark.Watermark import org.apache.flink.streaming.api.windowing.time.Time import org.apache.flink.streaming.api.windowing.windows.TimeWindow import org.apache.flink.util.Collector
object LogAnalysis { val log = LoggerFactory.getLogger(LogAnalysis.getClass)
def main(args: Array[String]): Unit = { val env = StreamExecutionEnvironment._getExecutionEnvironment _ env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime) val topic = "pktest" val properties = new Properties properties.setProperty("bootstrap.servers", "外网ip:9092") properties.setProperty("group.id","test") val data = env.addSource(new FlinkKafkaConsumer[String](topic, **new** SimpleStringSchema, properties)) data.map(x => { val splits = x.split("\t") val level = splits(2) val timeStr = splits(3) var time: Long = 0l try { time = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss").parse(timeStr).getTime }catch { case e: Exception => { log.error(s"time转换错误: **$**timeStr",e.getMessage) } } val domain = splits(5) val traffic = splits(6) (level,time,domain,traffic) }).filter(_._2 != 0) .filter(_._1 == "E") .map(x => (x._2,x._3,x._4.toLong)) .setParallelism(1).assignTimestampsAndWatermarks(new AssignerWithPeriodicWatermarks[(Long, String, Long)] { var maxOutOfOrderness: Long = 10000l var currentMaxTimestamp: Long = _
**override def** getCurrentWatermark: Watermark = {
**new** Watermark(_currentMaxTimestamp_ \- _maxOutOfOrderness_)
}
**override def** extractTimestamp(element: (Long, String, Long), previousElementTimestamp: Long): Long \= {
**val** timestamp = element.\_1
_currentMaxTimestamp_ \= Math._max_(timestamp,_currentMaxTimestamp_)
timestamp
}
}).keyBy(\_.\_2)
.timeWindow(Time._minutes_(1))
.apply(**new** WindowFunction\[(Long,String,Long),(String,String,Long),String,TimeWindow\] {
**override def** apply(key: String, window: TimeWindow, input: Iterable\[(Long, String, Long)\], out: Collector\[(String, String, Long)\]): Unit \= {
**val** list = input.toList
**val** sum = list.map(\_.\_3).sum
**val** format = **new** SimpleDateFormat("yyyy-MM-dd HH:mm:ss")
out.collect((format.format(window.getStart) + " - " \+ format.format(window.getEnd),key,sum))
}
})
.print().setParallelism(1)
env.execute("LogAnalysis")
} }
Sink到Elasticsearch
安装ES
我们这里使用的版本为6.2.4
wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-6.2.4.tar.gz
解压缩后进入config目录,编辑elasticsearch.yml,修改
network.host: 0.0.0.0
增加一个非root用户
useradd es
将ES目录下的所有文件更改为es所有者
chown -R es:es elasticsearch-6.2.4
修改/etc/security/limits.conf,将最下方的内容改为
es soft nofile 65536
es hard nofile 65536
修改/etc/sysctl.conf,增加
vm.max_map_count=655360
执行命令
sysctl -p
进入es的bin文件夹,并切换用户es
su es
在es用户下执行
./elasticsearch -d
此时可以在Web界面中看到ES的信息(外网ip:9200)

给Flink添加ES Sink,先添加依赖
@Slf4j public class LogAnalysis {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);
String topic = "pktest";
Properties properties = new Properties();
properties.setProperty("bootstrap.servers","外网ip:9092");
properties.setProperty("group.id","test");
List
@Override
public long extractTimestamp(Tuple3<Long, String, Long> element, long previousElementTimestamp) { Long timestamp = element.getField(0); currentMaxTimestamp = Math.max(timestamp,currentMaxTimestamp); return timestamp; } }).keyBy(x -> (String) x.getField(1)) .timeWindow(Time.minutes(1)) //输出格式:一分钟的时间间隔,域名,该域名在一分钟内的总流量 .apply(new WindowFunction<Tuple3<Long,String,Long>, Tuple3<String,String,Long>, String, TimeWindow>() { @Override public void apply(String s, TimeWindow window, Iterable<Tuple3<Long, String, Long>> input, Collector<Tuple3<String, String, Long>> out) throws Exception { List<Tuple3<Long,String,Long>> list = (List) input; Long sum = list.stream().map(x -> (Long) x.getField(2)).reduce((x, y) -> x + y).get(); SimpleDateFormat format = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss"); out.collect(new Tuple3<>(format.format(window.getStart()) + " - " + format.format(window.getEnd()),s,sum)); } }) .addSink(builder.build()); env.execute("LogAnalysis"); } }
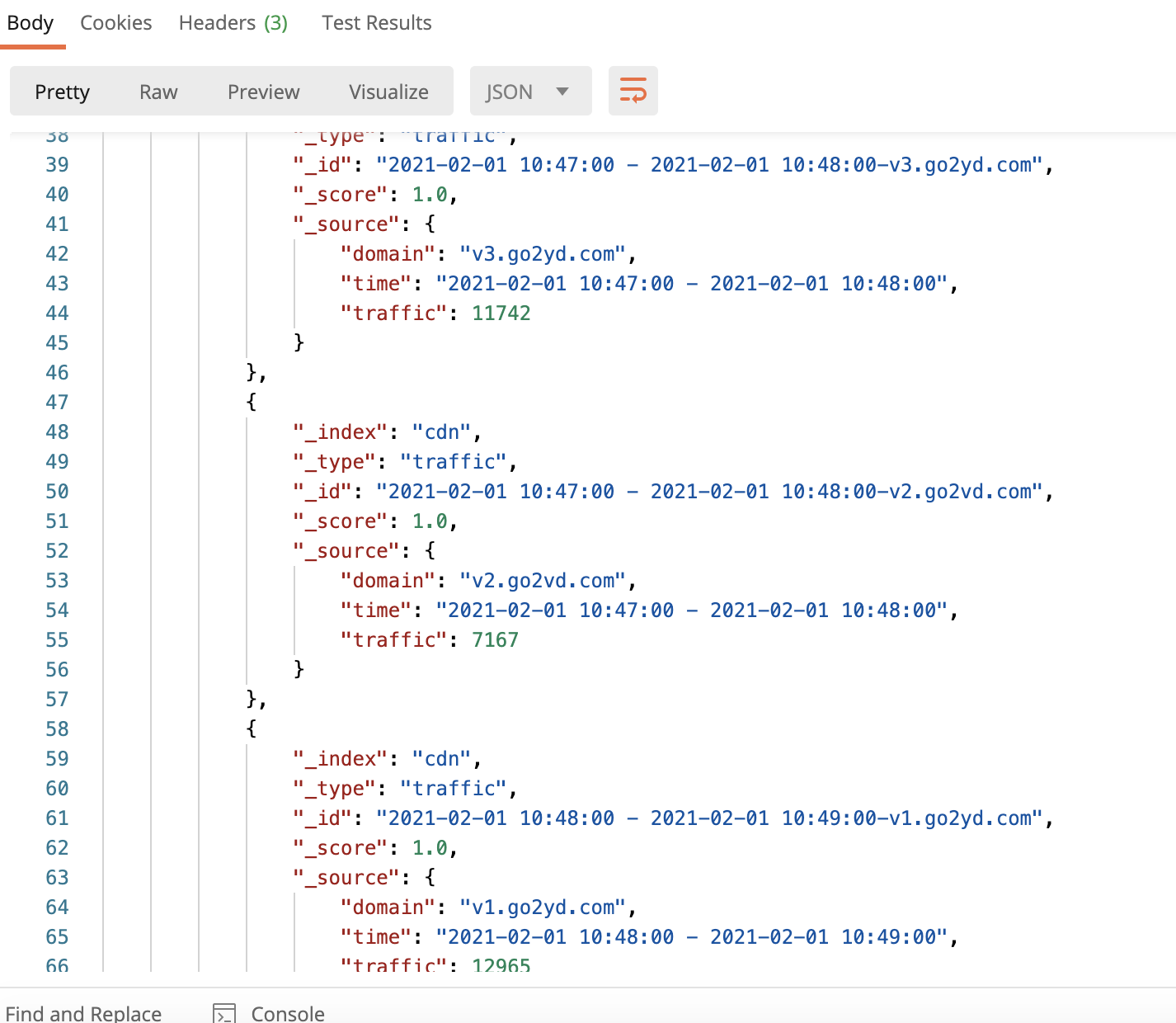
执行后可以在ES中查询到数据
http://外网ip:9200/cdn/traffic/_search

Scala代码
import java.text.SimpleDateFormat import java.util import java.util.Properties
import org.apache.flink.api.common.functions.RuntimeContext import org.apache.flink.api.common.serialization.SimpleStringSchema import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer import org.slf4j.LoggerFactory import org.apache.flink.api.scala._ import org.apache.flink.streaming.api.TimeCharacteristic import org.apache.flink.streaming.api.functions.AssignerWithPeriodicWatermarks import org.apache.flink.streaming.api.scala.function.WindowFunction import org.apache.flink.streaming.api.watermark.Watermark import org.apache.flink.streaming.api.windowing.time.Time import org.apache.flink.streaming.api.windowing.windows.TimeWindow import org.apache.flink.streaming.connectors.elasticsearch.{ElasticsearchSinkFunction, RequestIndexer} import org.apache.flink.streaming.connectors.elasticsearch6.ElasticsearchSink import org.apache.flink.util.Collector import org.apache.http.HttpHost import org.elasticsearch.client.Requests
object LogAnalysis { val log = LoggerFactory.getLogger(LogAnalysis.getClass)
def main(args: Array[String]): Unit = { val env = StreamExecutionEnvironment._getExecutionEnvironment _ env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime) val topic = "pktest" val properties = new Properties properties.setProperty("bootstrap.servers", "外网ip:9092") properties.setProperty("group.id","test") val httpHosts = new util.ArrayList[HttpHost] httpHosts.add(new HttpHost("外网ip",9200,"http")) val builder = new ElasticsearchSink.Builder[(String,String,Long)](httpHosts,**new** ElasticsearchSinkFunction[(String, String, Long)] { override def process(t: (String, String, Long), runtimeContext: RuntimeContext, indexer: RequestIndexer): Unit = { val json = new util.HashMap[String,Any] json.put("time",t._1) json.put("domain",t._2) json.put("traffic",t._3) val id = t._1 + "-" + t._2 indexer.add(Requests.indexRequest() .index("cdn") .`type`("traffic") .id(id) .source(json)) } }) builder.setBulkFlushMaxActions(1) val data = env.addSource(new FlinkKafkaConsumer[String](topic, **new** SimpleStringSchema, properties)) data.map(x => { val splits = x.split("\t") val level = splits(2) val timeStr = splits(3) var time: Long = 0l try { time = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss").parse(timeStr).getTime }catch { case e: Exception => { log.error(s"time转换错误: **$**timeStr",e.getMessage) } } val domain = splits(5) val traffic = splits(6) (level,time,domain,traffic) }).filter(_._2 != 0) .filter(_._1 == "E") .map(x => (x._2,x._3,x._4.toLong)) .setParallelism(1).assignTimestampsAndWatermarks(new AssignerWithPeriodicWatermarks[(Long, String, Long)] { var maxOutOfOrderness: Long = 10000l var currentMaxTimestamp: Long = _
**override def** getCurrentWatermark: Watermark = {
**new** Watermark(_currentMaxTimestamp_ \- _maxOutOfOrderness_)
}
**override def** extractTimestamp(element: (Long, String, Long), previousElementTimestamp: Long): Long \= {
**val** timestamp = element.\_1
_currentMaxTimestamp_ \= Math._max_(timestamp,_currentMaxTimestamp_)
timestamp
}
}).keyBy(\_.\_2)
.timeWindow(Time._minutes_(1))
.apply(**new** WindowFunction\[(Long,String,Long),(String,String,Long),String,TimeWindow\] {
**override def** apply(key: String, window: TimeWindow, input: Iterable\[(Long, String, Long)\], out: Collector\[(String, String, Long)\]): Unit \= {
**val** list = input.toList
**val** sum = list.map(\_.\_3).sum
**val** format = **new** SimpleDateFormat("yyyy-MM-dd HH:mm:ss")
out.collect((format.format(window.getStart) + " - " \+ format.format(window.getEnd),key,sum))
}
})
.addSink(builder.build)
env.execute("LogAnalysis")
} }
Kibana图形展示
安装kibana
wget https://artifacts.elastic.co/downloads/kibana/kibana-6.2.4-linux-x86_64.tar.gz
kibana要跟ES保持版本相同,解压缩后进入config目录,编辑kibana.yml
server.host: "host2"
elasticsearch.url: "http://host2:9200"
这里面的内容会根据版本不同会有一些不同,保存后,进入bin目录
切换es用户,执行
./kibana &
访问Web页面,外网ip:5601
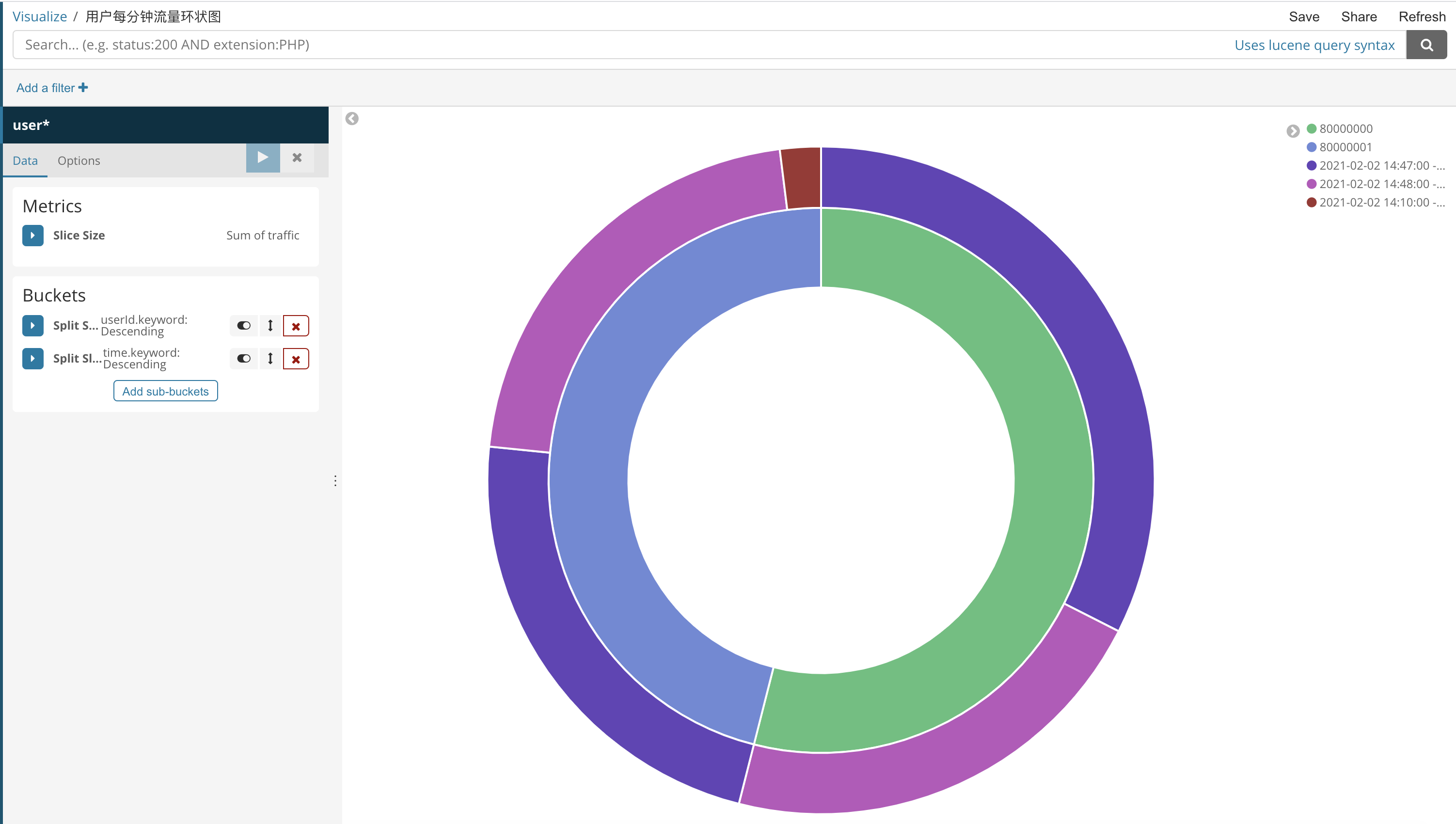
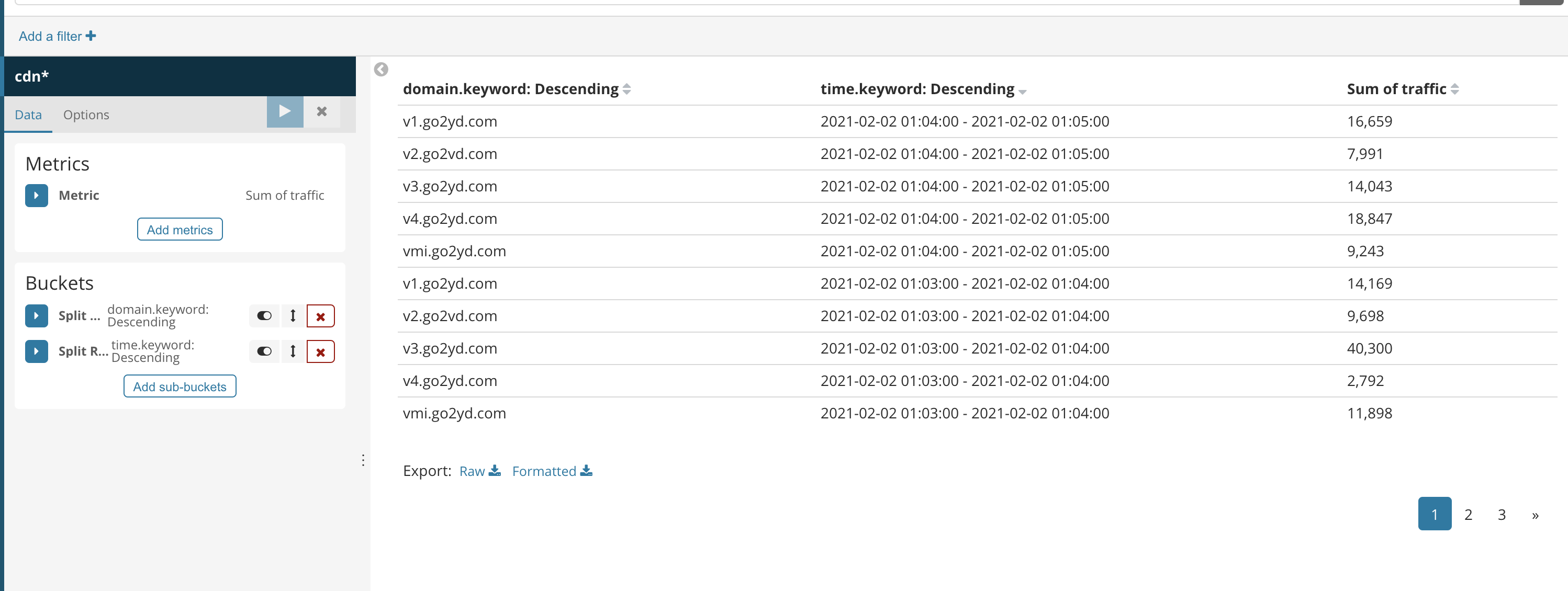
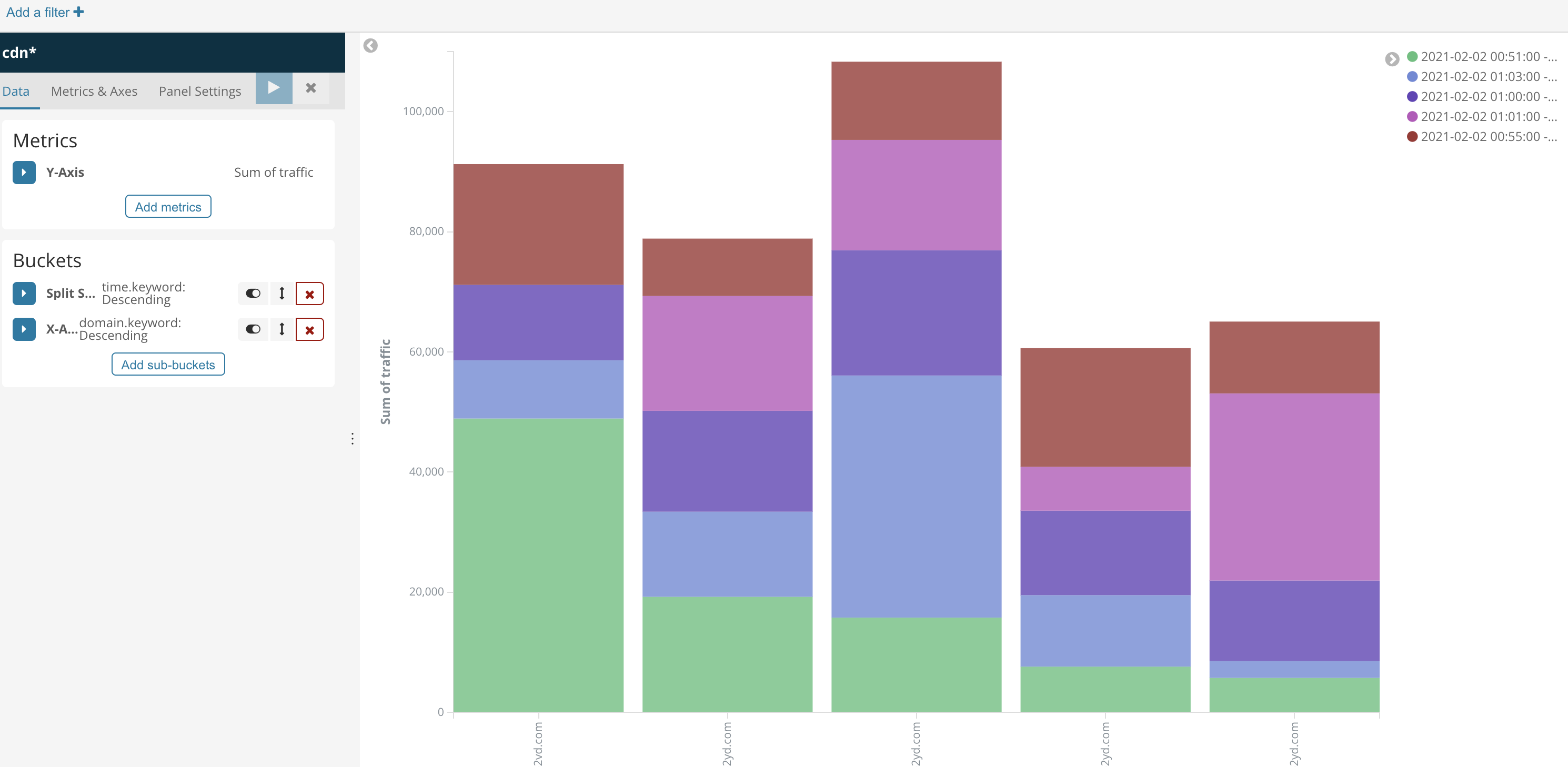
这里我做了一个表,一个柱状图
第二个需求,统计一分钟内每个用户产生的流量
在MySQL数据库中新增一张表user_domain_config,字段如下
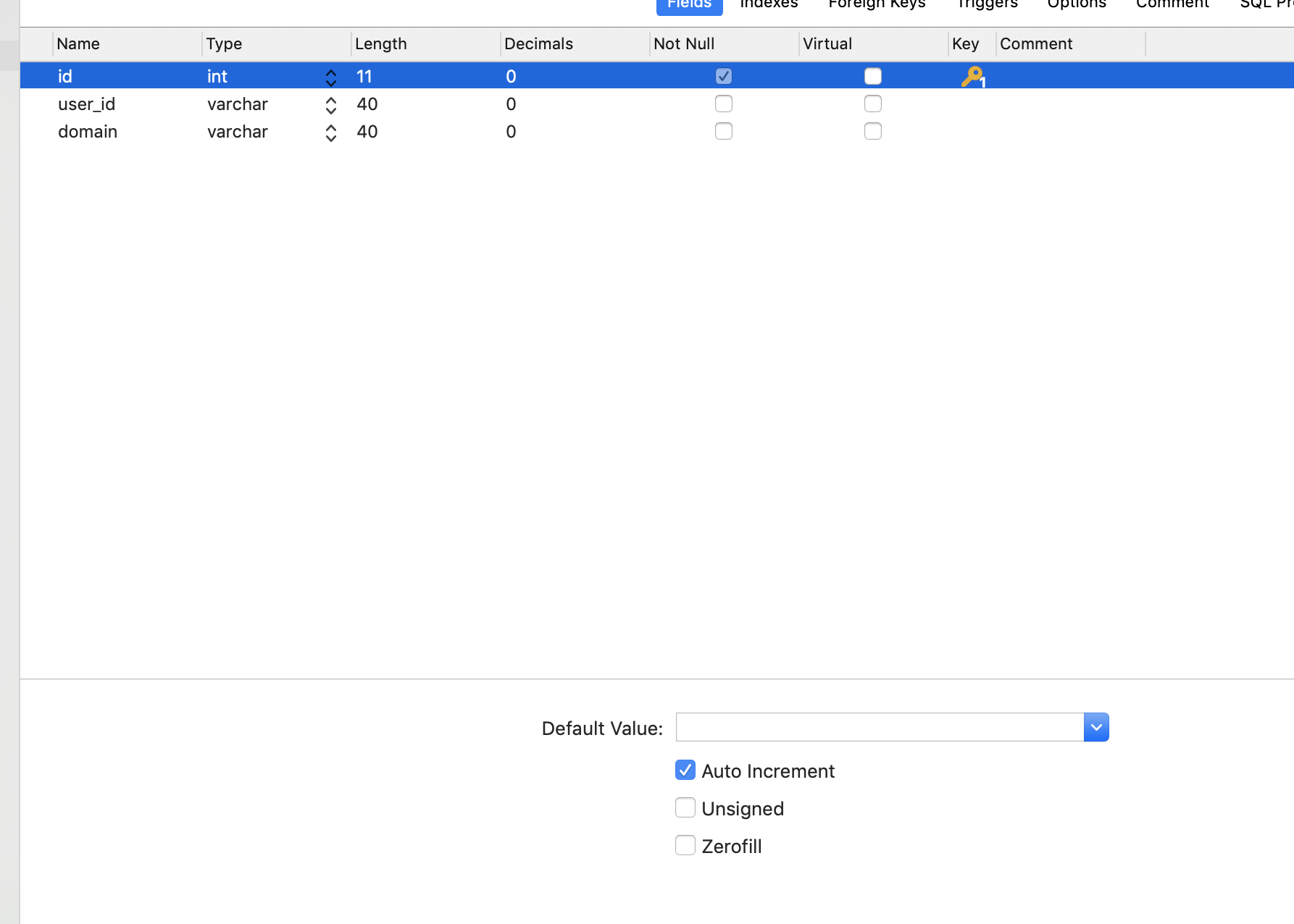
表中内容如下
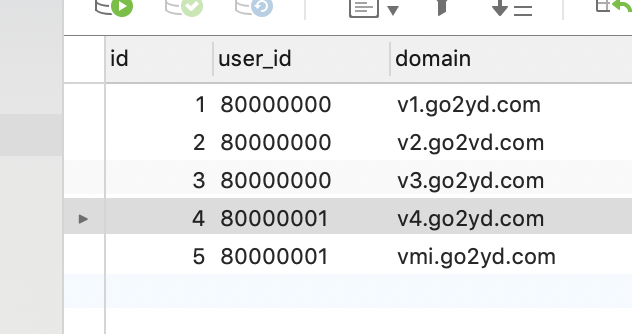
数据清洗
_/** _ * 自定义MySQL数据源 */ public class MySQLSource extends RichParallelSourceFunction<Tuple2<String,String>> { private Connection connection; private PreparedStatement pstmt; private Connection getConnection() { Connection conn = null; try { Class.forName("com.mysql.cj.jdbc.Driver"); String url = "jdbc:mysql://外网ip:3306/flink"; conn = DriverManager.getConnection(url,"root","******"); }catch (Exception e) { e.printStackTrace(); } return conn; }
@Override
public void open(Configuration parameters) throws Exception { super.open(parameters); connection = getConnection(); String sql = "select user_id,domain from user_domain_config"; pstmt = connection.prepareStatement(sql); }
@Override
@SuppressWarnings("unchecked") public void run(SourceContext<Tuple2<String,String>> ctx) throws Exception { ResultSet rs = pstmt.executeQuery(); while (rs.next()) { Tuple2 tuple2 = new Tuple2(rs.getString("domain"),rs.getString("user_id")); ctx.collect(tuple2); } pstmt.close(); }
@Override
public void cancel() {
}
@Override
public void close() throws Exception { super.close(); if (pstmt != null) { pstmt.close(); } if (connection != null) { connection.close(); } } }
@Slf4j public class LogAnalysisWithMySQL {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
String topic = "pktest";
Properties properties = new Properties();
properties.setProperty("bootstrap.servers","外网ip:9092");
properties.setProperty("group.id","test");
DataStreamSource
@Override
public void flatMap2(Tuple2<String, String> value, Collector<Tuple4<Long,String,Long,String>> out) throws Exception { userDomainMap.put(value.getField(0),value.getField(1)); } }).print().setParallelism(1); env.execute("LogAnalysisWithMySQL"); } }
运行结果
(1612239325000,vmi.go2yd.com,7115,80000001)
(1612239633000,v4.go2yd.com,8412,80000001)
(1612239635000,v3.go2yd.com,3527,80000000)
(1612239639000,v1.go2yd.com,7385,80000000)
(1612239643000,vmi.go2yd.com,8650,80000001)
(1612239645000,vmi.go2yd.com,2642,80000001)
(1612239647000,vmi.go2yd.com,1525,80000001)
(1612239649000,v2.go2vd.com,8832,80000000)
Scala代码
import java.sql.{Connection, DriverManager, PreparedStatement}
import org.apache.flink.configuration.Configuration import org.apache.flink.streaming.api.functions.source.{RichParallelSourceFunction, SourceFunction}
class MySQLSource extends RichParallelSourceFunction[(String,String)]{ var connection: Connection = **null ** var pstmt: PreparedStatement = null def getConnection:Connection = { var conn: Connection = **null ** Class.forName("com.mysql.cj.jdbc.Driver") val url = "jdbc:mysql://外网ip:3306/flink" conn = DriverManager.getConnection(url, "root", "******") conn }
override def open(parameters: Configuration): Unit = { connection = getConnection val sql = "select user_id,domain from user_domain_config" pstmt = connection.prepareStatement(sql) }
override def cancel() = {}
override def run(ctx: SourceFunction.SourceContext[(String, String)]) = { val rs = pstmt.executeQuery() while (rs.next) { val tuple2 = (rs.getString("domain"),rs.getString("user_id")) ctx.collect(tuple2) } pstmt.close() }
override def close(): Unit = { if (pstmt != null) { pstmt.close() } if (connection != null) { connection.close() } } }
import java.text.SimpleDateFormat import java.util.Properties
import com.guanjian.flink.scala.until.MySQLSource import org.apache.flink.api.common.serialization.SimpleStringSchema import org.apache.flink.api.scala._ import org.apache.flink.streaming.api.functions.co.CoFlatMapFunction import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer import org.apache.flink.util.Collector import org.slf4j.LoggerFactory
import scala.collection.mutable
object LogAnalysisWithMySQL { val log = LoggerFactory.getLogger(LogAnalysisWithMySQL.getClass)
def main(args: Array[String]): Unit = { val env = StreamExecutionEnvironment._getExecutionEnvironment _ val topic = "pktest" val properties = new Properties properties.setProperty("bootstrap.servers", "外网ip:9092") properties.setProperty("group.id","test") val data = env.addSource(new FlinkKafkaConsumer[String](topic, **new** SimpleStringSchema, properties)) val logData = data.map(x => { val splits = x.split("\t") val level = splits(2) val timeStr = splits(3) var time: Long = 0l try { time = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss").parse(timeStr).getTime }catch { case e: Exception => { log.error(s"time转换错误: **$**timeStr",e.getMessage) } } val domain = splits(5) val traffic = splits(6) (level,time,domain,traffic) }).filter(_._2 != 0) .filter(_._1 == "E") .map(x => (x._2,x._3,x._4.toLong)) val mysqlData = env.addSource(new MySQLSource) logData.connect(mysqlData).flatMap(new CoFlatMapFunction[(Long,String,Long),(String,String),(Long,String,Long,String)] { var userDomainMap = mutable.HashMap[String,String]()
**override def** flatMap1(value: (Long, String, Long), out: Collector\[(Long, String, Long, String)\]) = {
**val** domain = value.\_2
**val** userId = _userDomainMap_.getOrElse(domain,"")
out.collect((value.\_1,value.\_2,value.\_3,userId))
}
**override def** flatMap2(value: (String, String), out: Collector\[(Long, String, Long, String)\]) = {
_userDomainMap_ += value.\_1 -> value.\_2
}
}).print().setParallelism(1)
env.execute("LogAnalysisWithMySQL")
} }
数据分析
@Slf4j public class LogAnalysisWithMySQL {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);
String topic = "pktest";
Properties properties = new Properties();
properties.setProperty("bootstrap.servers","外网ip:9092");
properties.setProperty("group.id","test");
DataStreamSource
@Override
public void flatMap2(Tuple2<String, String> value, Collector<Tuple4<Long,String,Long,String>> out) throws Exception { userDomainMap.put(value.getField(0),value.getField(1)); } }).setParallelism(1).assignTimestampsAndWatermarks(new AssignerWithPeriodicWatermarks<Tuple4<Long, String, Long,String>>() { private Long maxOutOfOrderness = 10000L; private Long currentMaxTimestamp = 0L; @Nullable @Override public Watermark getCurrentWatermark() { return new Watermark(currentMaxTimestamp - maxOutOfOrderness); }
@Override
public long extractTimestamp(Tuple4<Long, String, Long,String> element, long previousElementTimestamp) { Long timestamp = element.getField(0); currentMaxTimestamp = Math.max(timestamp,currentMaxTimestamp); return timestamp; } }).keyBy(x -> (String) x.getField(3)) .timeWindow(Time.minutes(1)) //输出格式:一分钟的时间间隔,用户,该用户在一分钟内的总流量 .apply(new WindowFunction<Tuple4<Long,String,Long,String>, Tuple3<String,String,Long>, String, TimeWindow>() { @Override public void apply(String s, TimeWindow window, Iterable<Tuple4<Long, String, Long, String>> input, Collector<Tuple3<String, String, Long>> out) throws Exception { List<Tuple4<Long, String, Long,String>> list = (List) input; Long sum = list.stream().map(x -> (Long) x.getField(2)).reduce((x, y) -> x + y).get(); SimpleDateFormat format = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss"); out.collect(new Tuple3<>(format.format(window.getStart()) + " - " + format.format(window.getEnd()), s, sum)); } }).print().setParallelism(1); env.execute("LogAnalysisWithMySQL"); } }
运行结果
(2021-02-02 13:58:00 - 2021-02-02 13:59:00,80000000,20933)
(2021-02-02 13:58:00 - 2021-02-02 13:59:00,80000001,6928)
(2021-02-02 13:59:00 - 2021-02-02 14:00:00,80000001,38202)
(2021-02-02 13:59:00 - 2021-02-02 14:00:00,80000000,39394)
(2021-02-02 14:00:00 - 2021-02-02 14:01:00,80000001,23070)
(2021-02-02 14:00:00 - 2021-02-02 14:01:00,80000000,41701)
Scala代码
import java.text.SimpleDateFormat import java.util.Properties
import com.guanjian.flink.scala.until.MySQLSource import org.apache.flink.api.common.serialization.SimpleStringSchema import org.apache.flink.api.scala._ import org.apache.flink.streaming.api.TimeCharacteristic import org.apache.flink.streaming.api.functions.AssignerWithPeriodicWatermarks import org.apache.flink.streaming.api.functions.co.CoFlatMapFunction import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment import org.apache.flink.streaming.api.scala.function.WindowFunction import org.apache.flink.streaming.api.watermark.Watermark import org.apache.flink.streaming.api.windowing.time.Time import org.apache.flink.streaming.api.windowing.windows.TimeWindow import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer import org.apache.flink.util.Collector import org.slf4j.LoggerFactory
import scala.collection.mutable
object LogAnalysisWithMySQL { val log = LoggerFactory.getLogger(LogAnalysisWithMySQL.getClass)
def main(args: Array[String]): Unit = { val env = StreamExecutionEnvironment._getExecutionEnvironment _ env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime) val topic = "pktest" val properties = new Properties properties.setProperty("bootstrap.servers", "外网ip:9092") properties.setProperty("group.id","test") val data = env.addSource(new FlinkKafkaConsumer[String](topic, **new** SimpleStringSchema, properties)) val logData = data.map(x => { val splits = x.split("\t") val level = splits(2) val timeStr = splits(3) var time: Long = 0l try { time = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss").parse(timeStr).getTime }catch { case e: Exception => { log.error(s"time转换错误: **$**timeStr",e.getMessage) } } val domain = splits(5) val traffic = splits(6) (level,time,domain,traffic) }).filter(_._2 != 0) .filter(_._1 == "E") .map(x => (x._2,x._3,x._4.toLong)) val mysqlData = env.addSource(new MySQLSource) logData.connect(mysqlData).flatMap(new CoFlatMapFunction[(Long,String,Long),(String,String),(Long,String,Long,String)] { var userDomainMap = mutable.HashMap[String,String]()
**override def** flatMap1(value: (Long, String, Long), out: Collector\[(Long, String, Long, String)\]) = {
**val** domain = value.\_2
**val** userId = _userDomainMap_.getOrElse(domain,"")
out.collect((value.\_1,value.\_2,value.\_3,userId))
}
**override def** flatMap2(value: (String, String), out: Collector\[(Long, String, Long, String)\]) = {
_userDomainMap_ += value.\_1 -> value.\_2
}
}).setParallelism(1).assignTimestampsAndWatermarks(**new** AssignerWithPeriodicWatermarks\[(Long, String, Long, String)\] {
**var** _maxOutOfOrderness_: Long \= 10000l
var currentMaxTimestamp: Long = _
**override def** getCurrentWatermark: Watermark = {
**new** Watermark(_currentMaxTimestamp_ \- _maxOutOfOrderness_)
}
**override def** extractTimestamp(element: (Long, String, Long, String), previousElementTimestamp: Long): Long \= {
**val** timestamp = element.\_1
_currentMaxTimestamp_ \= Math._max_(timestamp,_currentMaxTimestamp_)
timestamp
}
}).keyBy(\_.\_4)
.timeWindow(Time._minutes_(1))
.apply(**new** WindowFunction\[(Long,String,Long,String),(String,String,Long),String,TimeWindow\] {
**override def** apply(key: String, window: TimeWindow, input: Iterable\[(Long, String, Long, String)\], out: Collector\[(String, String, Long)\]): Unit \= {
**val** list = input.toList
**val** sum = list.map(\_.\_3).sum
**val** format = **new** SimpleDateFormat("yyyy-MM-dd HH:mm:ss")
out.collect((format.format(window.getStart) + " - " \+ format.format(window.getEnd),key,sum))
}
}).print().setParallelism(1)
env.execute("LogAnalysisWithMySQL")
} }
Sink到ES
@Slf4j public class LogAnalysisWithMySQL {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);
String topic = "pktest";
Properties properties = new Properties();
properties.setProperty("bootstrap.servers","外网ip:9092");
properties.setProperty("group.id","test");
List
@Override
public void flatMap2(Tuple2<String, String> value, Collector<Tuple4<Long,String,Long,String>> out) throws Exception { userDomainMap.put(value.getField(0),value.getField(1)); } }).setParallelism(1).assignTimestampsAndWatermarks(new AssignerWithPeriodicWatermarks<Tuple4<Long, String, Long,String>>() { private Long maxOutOfOrderness = 10000L; private Long currentMaxTimestamp = 0L; @Nullable @Override public Watermark getCurrentWatermark() { return new Watermark(currentMaxTimestamp - maxOutOfOrderness); }
@Override
public long extractTimestamp(Tuple4<Long, String, Long,String> element, long previousElementTimestamp) { Long timestamp = element.getField(0); currentMaxTimestamp = Math.max(timestamp,currentMaxTimestamp); return timestamp; } }).keyBy(x -> (String) x.getField(3)) .timeWindow(Time.minutes(1)) //输出格式:一分钟的时间间隔,用户,该用户在一分钟内的总流量 .apply(new WindowFunction<Tuple4<Long,String,Long,String>, Tuple3<String,String,Long>, String, TimeWindow>() { @Override public void apply(String s, TimeWindow window, Iterable<Tuple4<Long, String, Long, String>> input, Collector<Tuple3<String, String, Long>> out) throws Exception { List<Tuple4<Long, String, Long,String>> list = (List) input; Long sum = list.stream().map(x -> (Long) x.getField(2)).reduce((x, y) -> x + y).get(); SimpleDateFormat format = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss"); out.collect(new Tuple3<>(format.format(window.getStart()) + " - " + format.format(window.getEnd()), s, sum)); } }).addSink(builder.build()); env.execute("LogAnalysisWithMySQL"); } }
运行结果
访问http://外网ip:9200/user/traffic/_search
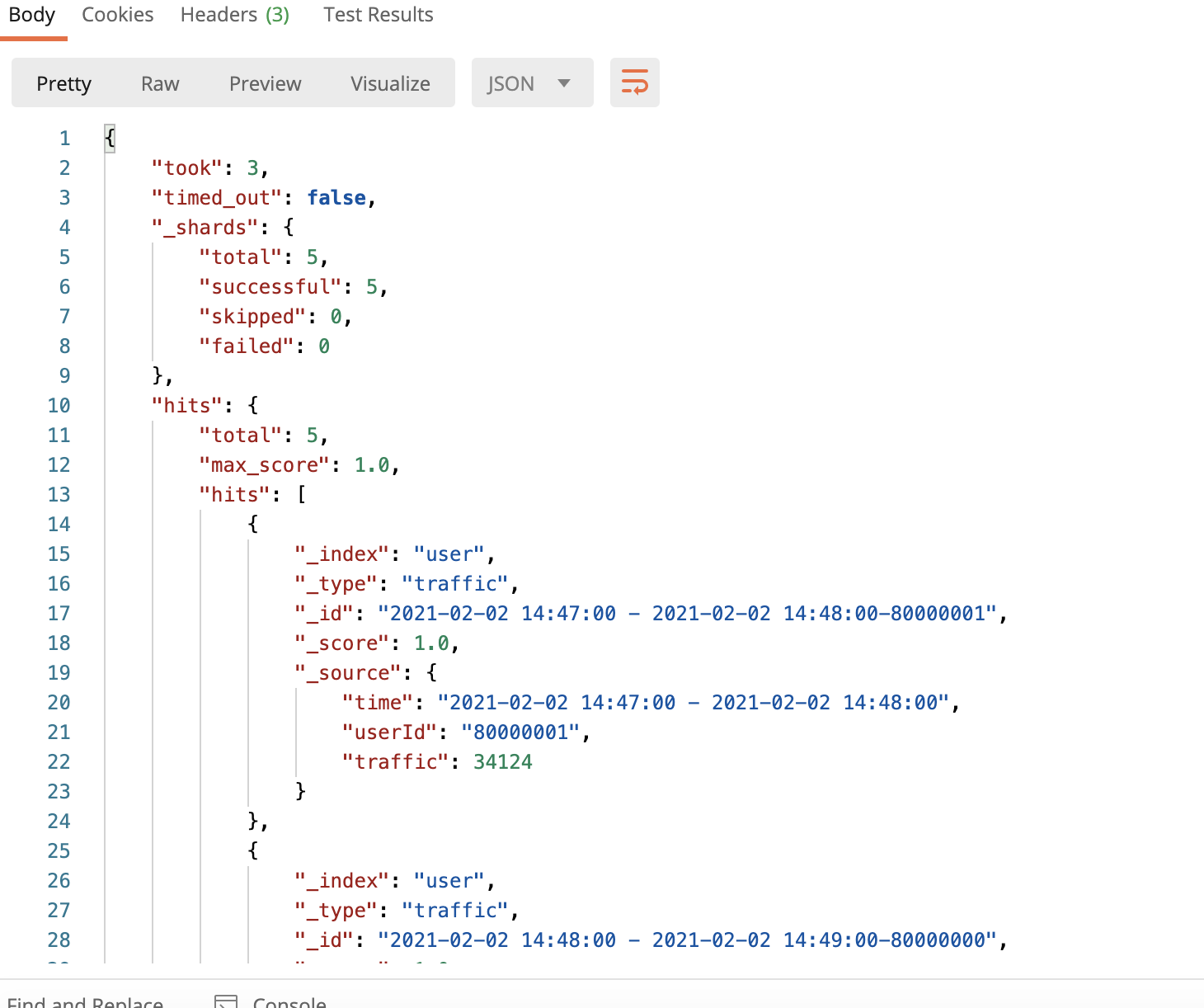
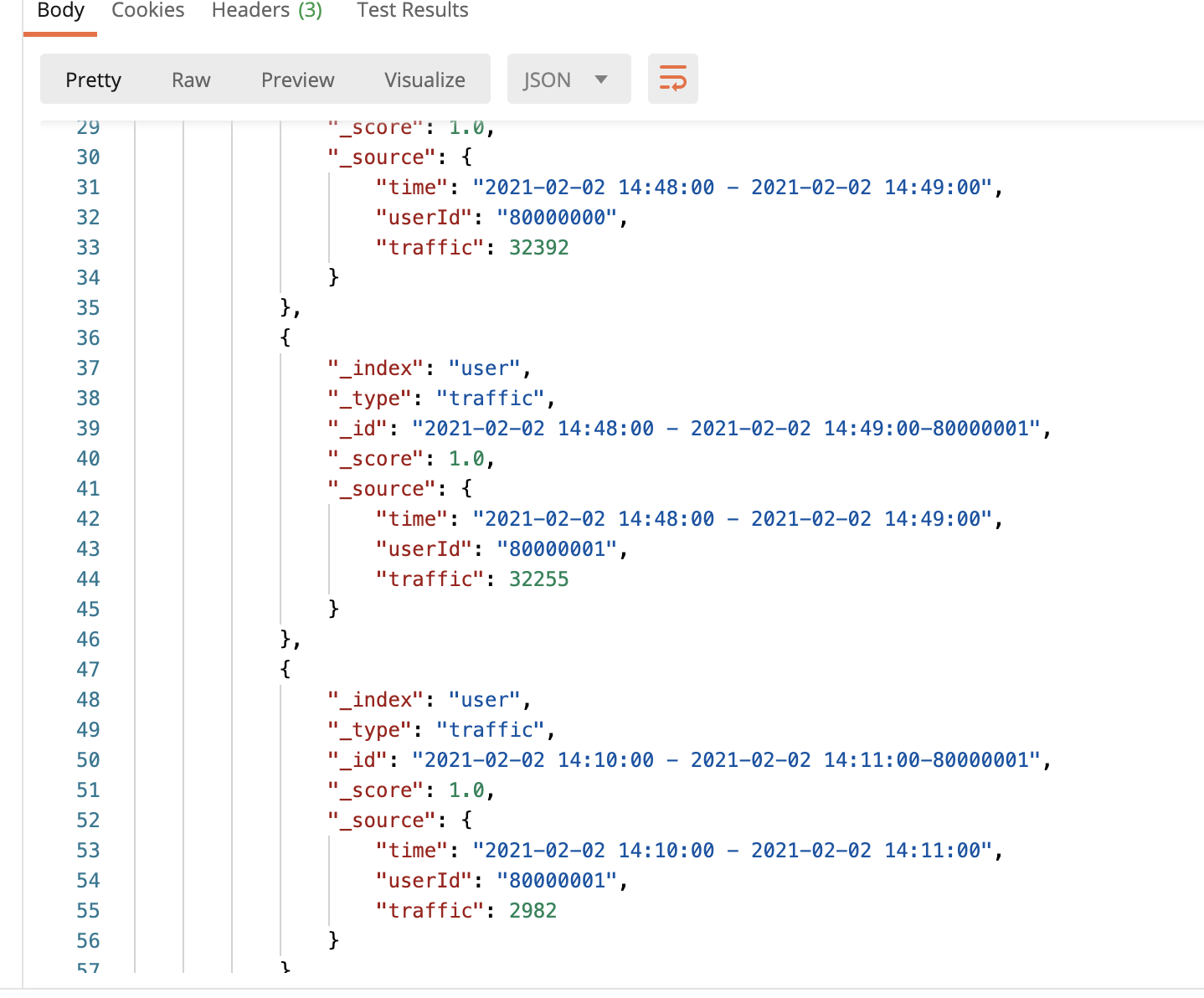
Scala代码
port java.text.SimpleDateFormat import java.util import java.util.Properties
import com.guanjian.flink.scala.until.MySQLSource import org.apache.flink.api.common.functions.RuntimeContext import org.apache.flink.api.common.serialization.SimpleStringSchema import org.apache.flink.api.scala._ import org.apache.flink.streaming.api.TimeCharacteristic import org.apache.flink.streaming.api.functions.AssignerWithPeriodicWatermarks import org.apache.flink.streaming.api.functions.co.CoFlatMapFunction import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment import org.apache.flink.streaming.api.scala.function.WindowFunction import org.apache.flink.streaming.api.watermark.Watermark import org.apache.flink.streaming.api.windowing.time.Time import org.apache.flink.streaming.api.windowing.windows.TimeWindow import org.apache.flink.streaming.connectors.elasticsearch.{ElasticsearchSinkFunction, RequestIndexer} import org.apache.flink.streaming.connectors.elasticsearch6.ElasticsearchSink import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer import org.apache.flink.util.Collector import org.apache.http.HttpHost import org.elasticsearch.client.Requests import org.slf4j.LoggerFactory
import scala.collection.mutable
object LogAnalysisWithMySQL { val log = LoggerFactory.getLogger(LogAnalysisWithMySQL.getClass)
def main(args: Array[String]): Unit = { val env = StreamExecutionEnvironment._getExecutionEnvironment _ env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime) val topic = "pktest" val properties = new Properties properties.setProperty("bootstrap.servers", "外网ip:9092") properties.setProperty("group.id","test") val httpHosts = new util.ArrayList[HttpHost] httpHosts.add(new HttpHost("外网ip",9200,"http")) val builder = new ElasticsearchSink.Builder[(String,String,Long)](httpHosts,**new** ElasticsearchSinkFunction[(String, String, Long)] { override def process(t: (String, String, Long), runtimeContext: RuntimeContext, indexer: RequestIndexer): Unit = { val json = new util.HashMap[String,Any] json.put("time",t._1) json.put("userId",t._2) json.put("traffic",t._3) val id = t._1 + "-" + t._2 indexer.add(Requests.indexRequest() .index("user") .`type`("traffic") .id(id) .source(json)) } }) builder.setBulkFlushMaxActions(1) val data = env.addSource(new FlinkKafkaConsumer[String](topic, **new** SimpleStringSchema, properties)) val logData = data.map(x => { val splits = x.split("\t") val level = splits(2) val timeStr = splits(3) var time: Long = 0l try { time = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss").parse(timeStr).getTime }catch { case e: Exception => { log.error(s"time转换错误: **$**timeStr",e.getMessage) } } val domain = splits(5) val traffic = splits(6) (level,time,domain,traffic) }).filter(_._2 != 0) .filter(_._1 == "E") .map(x => (x._2,x._3,x._4.toLong)) val mysqlData = env.addSource(new MySQLSource) logData.connect(mysqlData).flatMap(new CoFlatMapFunction[(Long,String,Long),(String,String),(Long,String,Long,String)] { var userDomainMap = mutable.HashMap[String,String]()
**override def** flatMap1(value: (Long, String, Long), out: Collector\[(Long, String, Long, String)\]) = {
**val** domain = value.\_2
**val** userId = _userDomainMap_.getOrElse(domain,"")
out.collect((value.\_1,value.\_2,value.\_3,userId))
}
**override def** flatMap2(value: (String, String), out: Collector\[(Long, String, Long, String)\]) = {
_userDomainMap_ += value.\_1 -> value.\_2
}
}).setParallelism(1).assignTimestampsAndWatermarks(**new** AssignerWithPeriodicWatermarks\[(Long, String, Long, String)\] {
**var** _maxOutOfOrderness_: Long \= 10000l
var currentMaxTimestamp: Long = _
**override def** getCurrentWatermark: Watermark = {
**new** Watermark(_currentMaxTimestamp_ \- _maxOutOfOrderness_)
}
**override def** extractTimestamp(element: (Long, String, Long, String), previousElementTimestamp: Long): Long \= {
**val** timestamp = element.\_1
_currentMaxTimestamp_ \= Math._max_(timestamp,_currentMaxTimestamp_)
timestamp
}
}).keyBy(\_.\_4)
.timeWindow(Time._minutes_(1))
.apply(**new** WindowFunction\[(Long,String,Long,String),(String,String,Long),String,TimeWindow\] {
**override def** apply(key: String, window: TimeWindow, input: Iterable\[(Long, String, Long, String)\], out: Collector\[(String, String, Long)\]): Unit \= {
**val** list = input.toList
**val** sum = list.map(\_.\_3).sum
**val** format = **new** SimpleDateFormat("yyyy-MM-dd HH:mm:ss")
out.collect((format.format(window.getStart) + " - " \+ format.format(window.getEnd),key,sum))
}
}).addSink(builder.build)
env.execute("LogAnalysisWithMySQL")
} }
Kibana图表展示
这里我们就画一个环状图吧