
生信论文的套路
ONCOMINE从全景、亚型两个维度做表达差异分析;
临床标本从蛋白水平确认(或HPA数据库),很重要;
Kaplan-Meier Plotter从临床意义的角度阐明其重要性;
cBio-portal数据库做基因组学的分析(机制一);
STRING互作和GO/KEGG分析探讨可能的信号通路(机制二);
TISIDB/TIMER分析肿瘤免疫特征(机制三)。
TIMER (Tumor Immune Estimation Resource)数据库也是用高通量测序(RNA-Seq表达谱)数据分析肿瘤组织中免疫细胞的浸润情况,主要提供B cells, CD4+ T cells, CD8+ T cells, Neutrphils, Macrophages and Dendritic cells等六种免疫细胞的浸润情况。界面友好,简单易学又方便。网址:https://cistrome.shinyapps.io/timer/。
TIMER网站分7个模块,其中前6个模块是对TCGA数据库的分析展示,第7个模块是对免疫细胞浸润比例进行评估。

基因模块,输入基因、肿瘤类型后,submit即可。
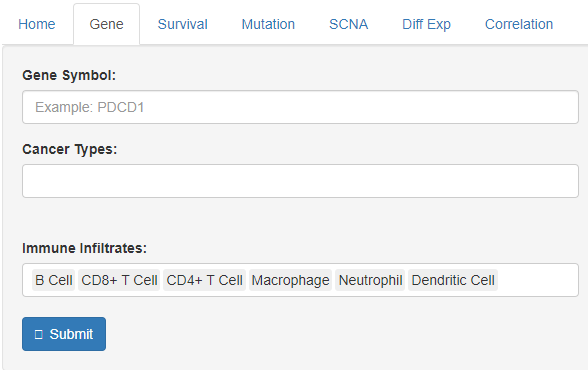
存活率模块。设定肿瘤类型,临床参数,免疫细胞类型和基因,还可以设定患者比例,存活时间,各种组合在一起,可以出很多图和表。功能强大。
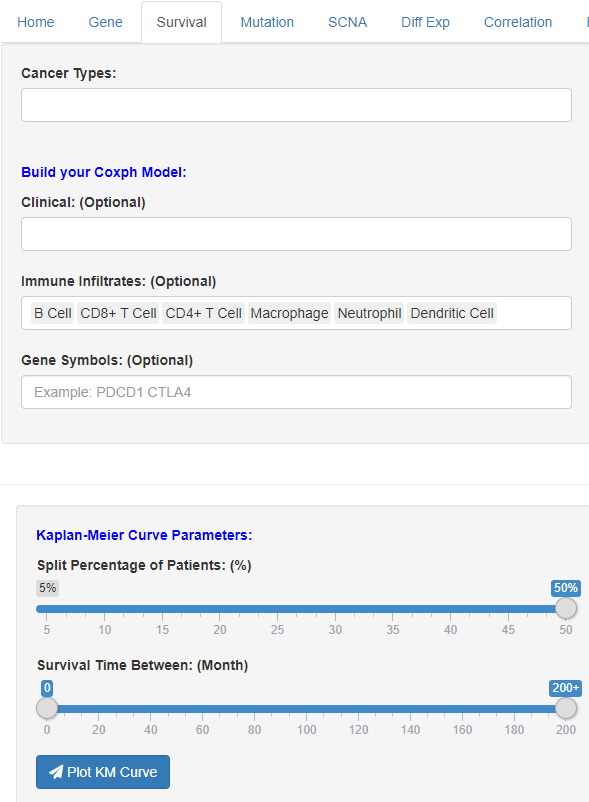
突变模块,此部分内容相对局限,只有部分常见的突变基因列出。
SCNA模块,肿瘤和基因输入,submit即可。
差异表达分析。
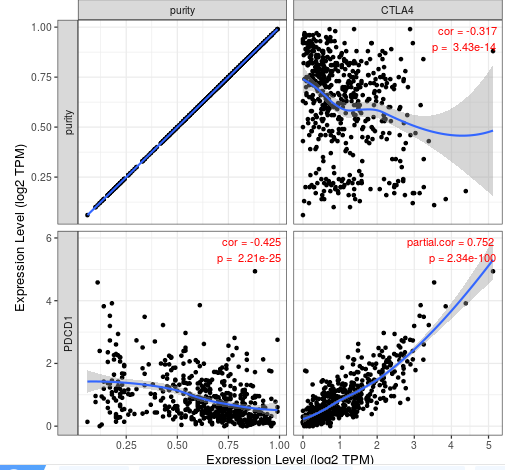
相关性分析。
最后的评估模块其实是该数据库的特色。在掌握下载TCGA数据路数据的条件下,结合该数据库的这种功能,接近更高层次的论文。
比较起来,其实TIMER比TISIDB更简单,因为TISIDB的数据需要判断后选择可用的数据。在进行肿瘤免疫浸润分析时,最好能多角度分析。但是,不要被方法所束缚,要用科研思维来引导生信技能,而不是生信技能引导科研思维。技能很多很多,数据库也很多很多,还有新的不断出现,有时让人眼花缭乱。但是,只要套路在心,就能气定神定,始终不乱。
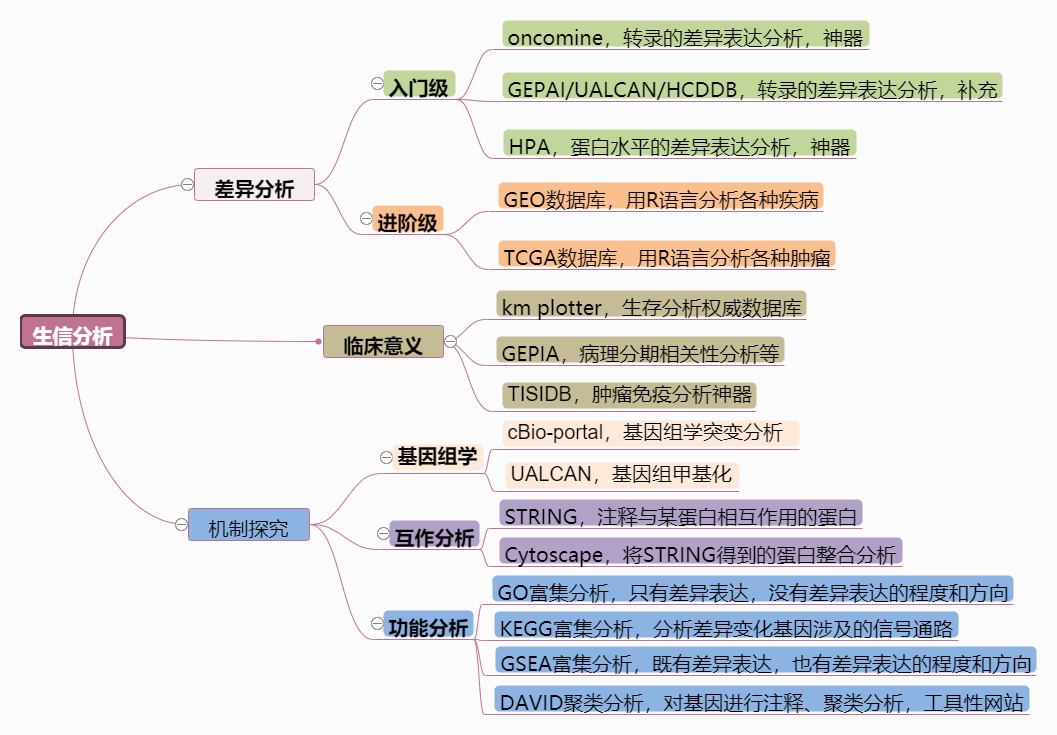
我们总结的生信论文套路,本身就是一种科研思维。
ONCOMINE从全景、亚型两个维度做表达差异分析;
临床标本从蛋白水平确认(或HPA数据库),很重要;
Kaplan-Meier Plotter从临床意义的角度阐明其重要性;
cBio-portal数据库做基因组学的分析(机制一);
STRING互作和GO/KEGG分析探讨可能的信号通路(机制二);
TISIDB/TIMER分析肿瘤免疫特征(机制三)。
本文分享自微信公众号 - 芒果先生聊生信(from2019to2020)。
如有侵权,请联系 support@oschina.cn 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。







