推荐
专栏
教程
课程
飞鹅
本次共找到2376条
网络爬虫
相关的信息
python知道
•
4年前
《Python3网络爬虫开发实战》
提取码:1028内容简介······本书介绍了如何利用Python3开发网络爬虫,书中首先介绍了环境配置和基础知识,然后讨论了urllib、requests、正则表达式、BeautifulSoup、XPath、pyquery、数据存储、Ajax数据爬取等内容,接着通过多个案例介绍了不同场景下如何实现数据爬取,后介绍了pyspider框架、S
Stella981
•
4年前
Python网络爬虫与如何爬取段子的项目实例
一、网络爬虫Python爬虫开发(https://www.oschina.net/action/GoToLink?urlhttp%3A%2F%2Fwww.shsxt.com%2Fpython)工程师,从网站某一个页面(通常是首页)开始,读取网页的内容,找到在网页中的其它链接地址,然后通过这些链接地址寻找下一个网页,这样
Python进阶者
•
2年前
盘点一个Python网络爬虫的问题
大家好,我是皮皮。一、前言前几天在Python白银群【大侠】问了一个Python网络爬虫的问题,这里拿出来给大家分享下。问题的引入:i问财网站的检索功能十分厉害,根据搜索会很快将检索数据以表格形式呈现,数据表格可以导出。每天检索次数不加限制,但产生的数据表
小白学大数据
•
2年前
Request 爬虫的 SSL 连接问题深度解析
SSL连接简介SSL(SecureSocketsLayer)是一种用于确保网络通信安全性的加密协议,广泛应用于互联网上的数据传输。在数据爬取过程中,爬虫需要与使用HTTPS协议的网站进行通信,这就牵涉到了SSL连接。本文将深入研究Request爬虫中的SS
Python进阶者
•
1年前
Python网络爬虫要清理cookies 才能再爬,有啥解决方法嘛?
大家好,我是Python进阶者。一、前言前几天在Python钻石交流群【大写一个Y】问了一个Python基网络爬虫的问题,问题如下:大佬们请教个问题我做了个在某眼查抓地址数据的爬虫,程序中做了随机25秒的循环延时,现在大概爬800多个地址,就会查不出数据,
小白学大数据
•
1年前
Rust中的数据抓取:代理和scraper的协同工作
一、数据抓取的基本概念数据抓取,又称网络爬虫或网页爬虫,是一种自动从互联网上提取信息的程序。这些信息可以是文本、图片、音频、视频等,用于数据分析、市场研究或内容聚合。为什么选择Rust进行数据抓取?●性能:Rust的编译速度和运行效率极高。●内存安全:Ru
小白学大数据
•
1年前
使用Panther进行爬虫时,如何优雅地处理登录和Cookies?
前言在互联网数据采集领域,网络爬虫扮演着至关重要的角色。它们能够自动化地从网站获取数据,为数据分析、内容聚合、市场研究等提供原材料。然而,许多网站通过登录和Cookies机制来保护其数据,这为爬虫开发者提出了新的挑战。SymfonyPanther作为一个现
小白学大数据
•
6个月前
优化 Python 爬虫性能:异步爬取新浪财经大数据
一、同步爬虫的瓶颈传统的同步爬虫(如requestsBeautifulSoup)在请求网页时,必须等待服务器返回响应后才能继续下一个请求。这种阻塞式I/O操作在面对大量数据时存在以下问题:速度慢:每个请求必须串行执行,无法充分利用网络带宽。易被封禁:高频
小白学大数据
•
5个月前
Python爬虫案例:Scrapy+XPath解析当当网网页结构
引言在当今大数据时代,网络爬虫已成为获取互联网信息的重要工具。作为Python生态中最强大的爬虫框架之一,Scrapy凭借其高性能、易扩展的特性受到开发者广泛青睐。本文将详细介绍如何利用Scrapy框架结合XPath技术解析当当网的商品页面结构,实现一个完
Python进阶者
•
3年前
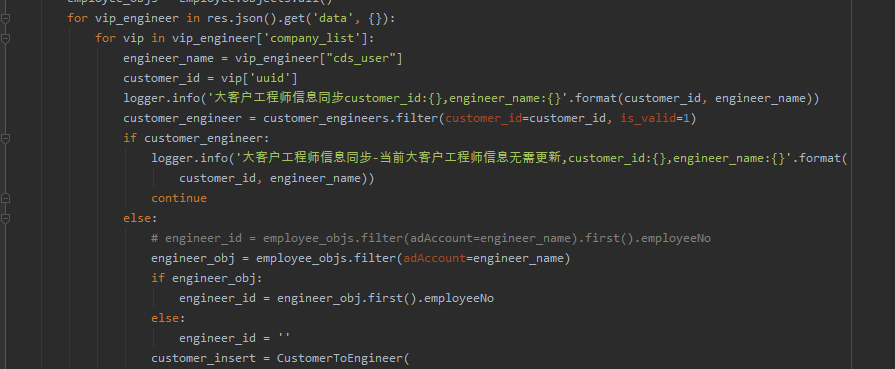
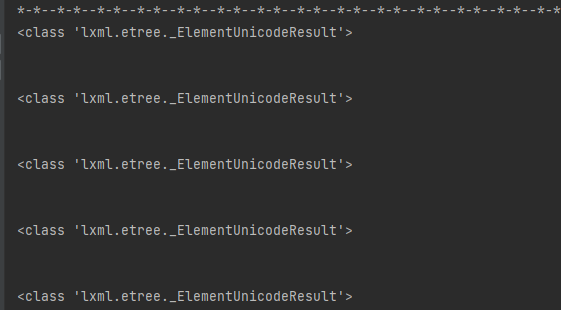
盘点一个Python网络爬虫实战问题
大家好,我是皮皮。一、前言前几天在Python钻石交流群【海南菜同学】问了一个Python网络爬虫的选择器提取问题,下图是截图:代码初步看上去好像没啥问题,但是结果就是不对。fromlxmlimportetreeimportrequestsurl"http://zw.hainan.gov.cn/wssc/emalls.html"headers
1
•••
5
6
7
•••
238