推荐
专栏
教程
课程
飞鹅
本次共找到2382条
网络爬虫
相关的信息
Wesley13
•
4年前
java爬虫入门
通用网络爬虫又称全网爬虫(ScalableWebCrawler),爬行对象从一些种子URL扩充到整个Web,主要为门户站点搜索引擎和大型Web服务提供商采集数据。今天我写的主要是一些皮毛入门现在来看下我们的pom依赖<projectxmlns"http://maven.apache.org/POM/4.0.0"xmln
Karen110
•
4年前
使用Scrapy网络爬虫框架小试牛刀
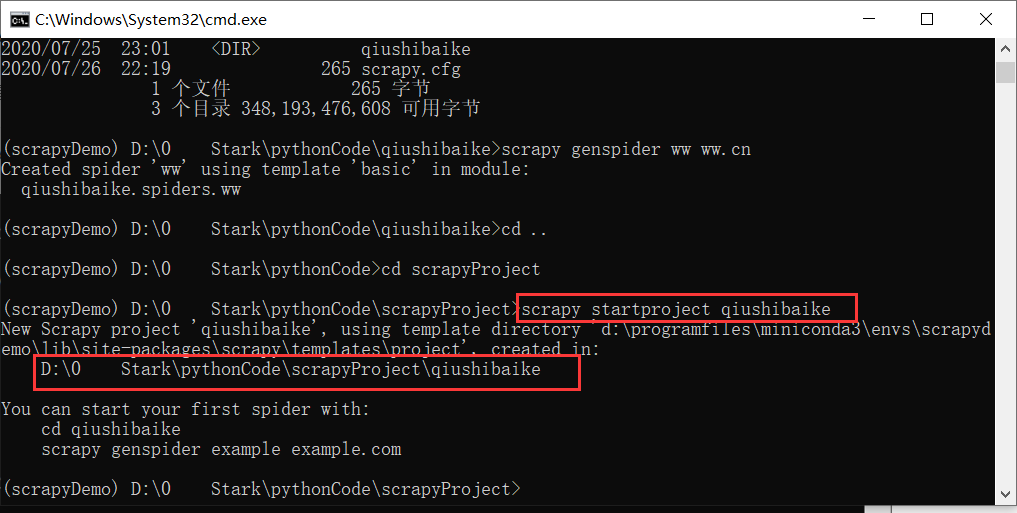
前言这次咱们来玩一个在Python中很牛叉的爬虫框架——Scrapy。scrapy介绍标准介绍Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架,非常出名,非常强悍。所谓的框架就是一个已经被集成了各种功能(高性能异步下载,队列,分布式,解析,持久化等)的具有很强通用性的项目模板。对于框架的学习,重点是要学习其框架的特性、各个功能的
Stella981
•
4年前
Python基础练习(一)中国大学定向排名爬取
说好的要从练习中学习爬虫的基础操作,所以就先从容易爬取的静态网页开始吧!今天要爬取的是最好大学网上的2018年中国大学排名。我个人认为这个是刚接触爬虫时用来练习的一个很不错的网页了。在说这个练习之前,给新着手学习爬虫的同学提供一个中国MOOC上北京理工大学嵩天老师的视频,Python网络爬虫与信息提取(https://www.oschina.n
Stella981
•
4年前
Python网络爬虫与文本数据分析
!(https://oscimg.oschina.net/oscnet/713b3c2bfee647209be73d544df565cf.jpg)课程介绍在过去的两年间,Python一路高歌猛进,成功窜上“最火编程语言”的宝座。惊奇的是使用Python最多的人群其实不是程序员,而是数据科学家,尤其是社会科学家,涵盖的学科有经
小白学大数据
•
1年前
错误处理在网络爬虫开发中的重要性:Perl示例 引言
错误处理的必要性在网络爬虫的开发过程中,可能会遇到多种错误,包括但不限于:网络连接问题服务器错误(如404或500错误)目标网站结构变化超时问题权限问题错误处理机制可以确保在遇到这些问题时,爬虫能够优雅地处理异常情况,记录错误信息,并在可能的情况下恢复执行
小白学大数据
•
1年前
Python爬虫教程:Selenium可视化爬虫的快速入门
网络爬虫作为获取数据的一种手段,其重要性日益凸显。Python语言以其简洁明了的语法和强大的库支持,成为编写爬虫的首选语言之一。Selenium是一个用于Web应用程序测试的工具,它能够模拟用户在浏览器中的操作,非常适合用来开发可视化爬虫。本文将带你快速入
小白学大数据
•
5个月前
应对反爬:使用Selenium模拟浏览器抓取12306动态旅游产品
在当今数据驱动的时代,网络爬虫已成为获取互联网信息的重要手段。然而,许多网站如12306都实施了严格的反爬虫机制,特别是对于动态加载的内容。本文将详细介绍如何使用Selenium模拟真实浏览器行为,有效绕过这些限制,成功抓取12306旅游产品数据。1230
Python进阶者
•
2年前
盘点一个Python网络爬虫问题
大家好,我是皮皮。一、前言前几天在Python最强王者群【刘桓鸣】问了一个Python网络爬虫的问题,这里拿出来给大家分享下。他自己的代码如下:importrequestskeyinput("请输入关键字")resrequests.post(url"htt
小白学大数据
•
2年前
使用asyncio库和多线程实现高并发的异步IO操作的爬虫
摘要:本文介绍了如何使用Python的asyncio库和多线程实现高并发的异步IO操作,以提升爬虫的效率和性能。通过使用asyncio的协程和事件循环,结合多线程,我们可以同时处理多个IO任务,并实现对腾讯新闻网站的高并发访问。正文:在网络爬虫中,IO操作
Python进阶者
•
1年前
这个网络爬虫代码,拿到数据之后如何存到csv文件中去?
大家好,我是皮皮。一、前言还是昨天的那个网络爬虫问题,那个粉丝说自己不熟悉pandas,用pandas做的爬虫,虽然简洁,但是自己不习惯,想要在他自己的代码基础上进行修改,获取数据的代码已经写好了,就差存储到csv中去了。他的原始代码如下:pythonim
1
•••
4
5
6
•••
239