大家好,我是皮皮。
一、前言
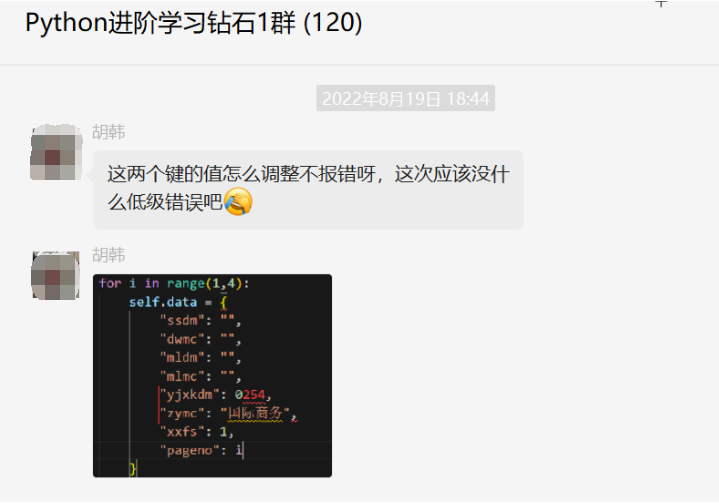
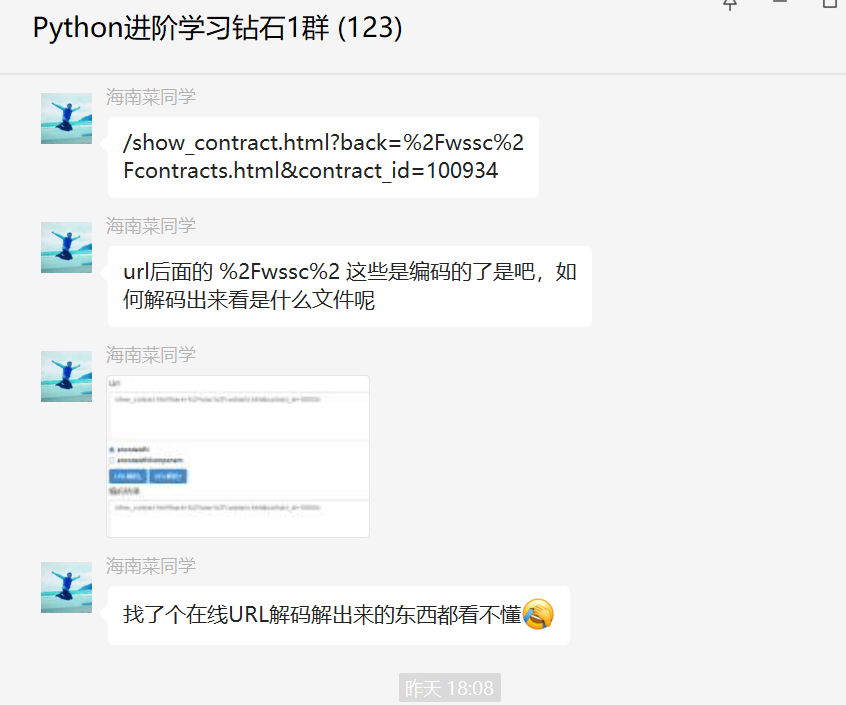
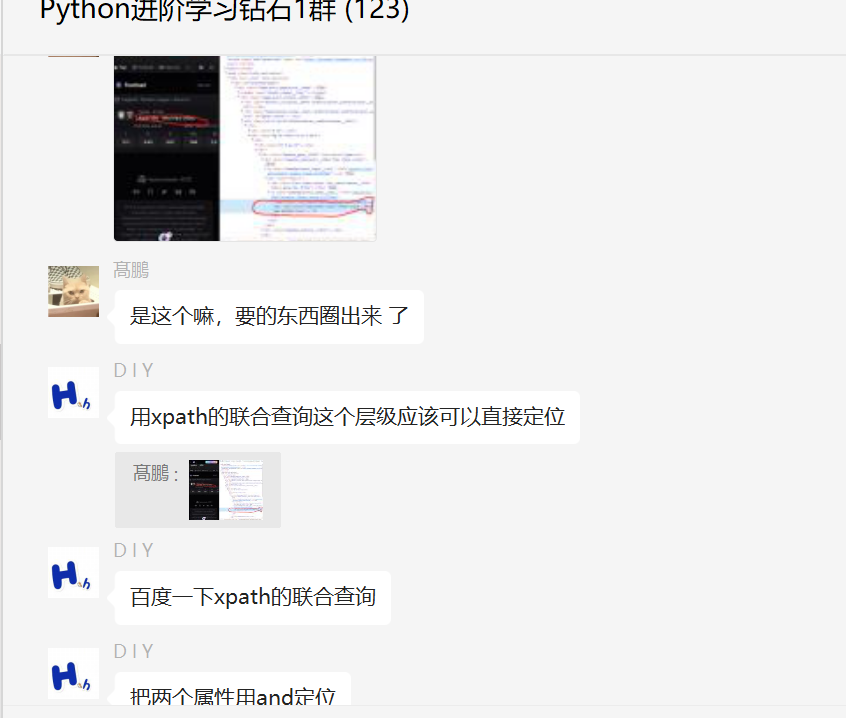
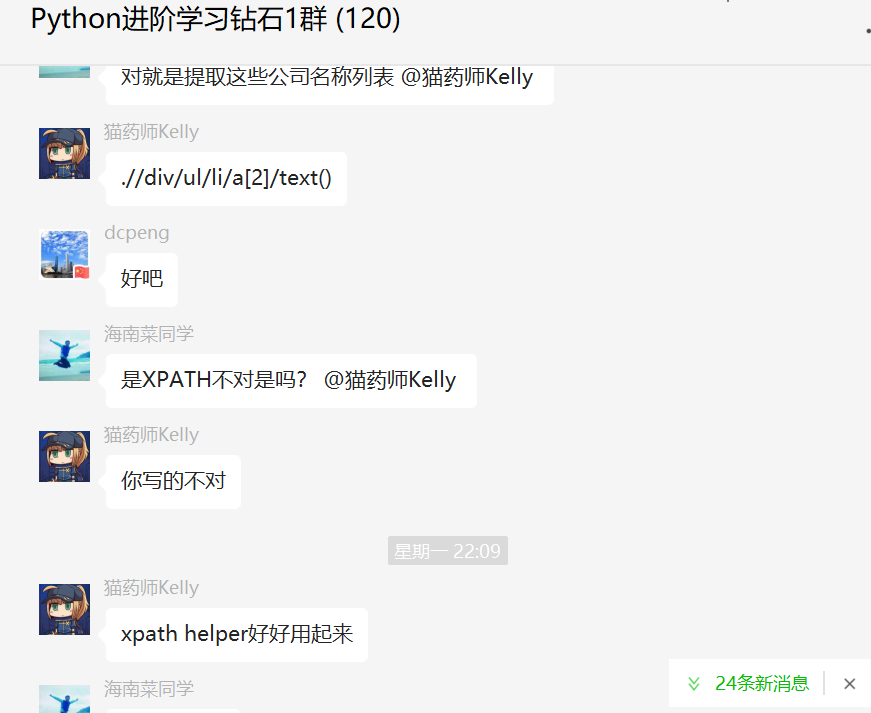
前几天在Python钻石交流群【海南菜同学】问了一个Python网络爬虫的选择器提取问题,下图是截图:
代码初步看上去好像没啥问题,但是结果就是不对。
from lxml import etree
import requests
url = "http://zw.hainan.gov.cn/wssc/emalls.html"
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36"
}
html = requests.get(url,headers=headers)
html = html.content.decode('utf-8')
doc = etree.HTML(html)
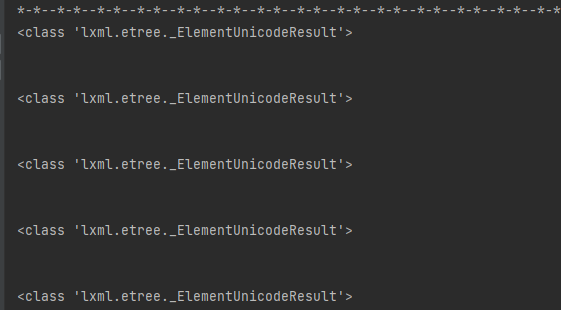
res = doc.xpath('/html/body/div[5]/ul/text()')
print('*-*--'*20)
for item in res:
print(type(item))
print(item[0])
print('*-*--'*20)初步判断是xpath写得有问题。
二、实现过程
这里【猫药师Kelly】确认了需求,如下所示:
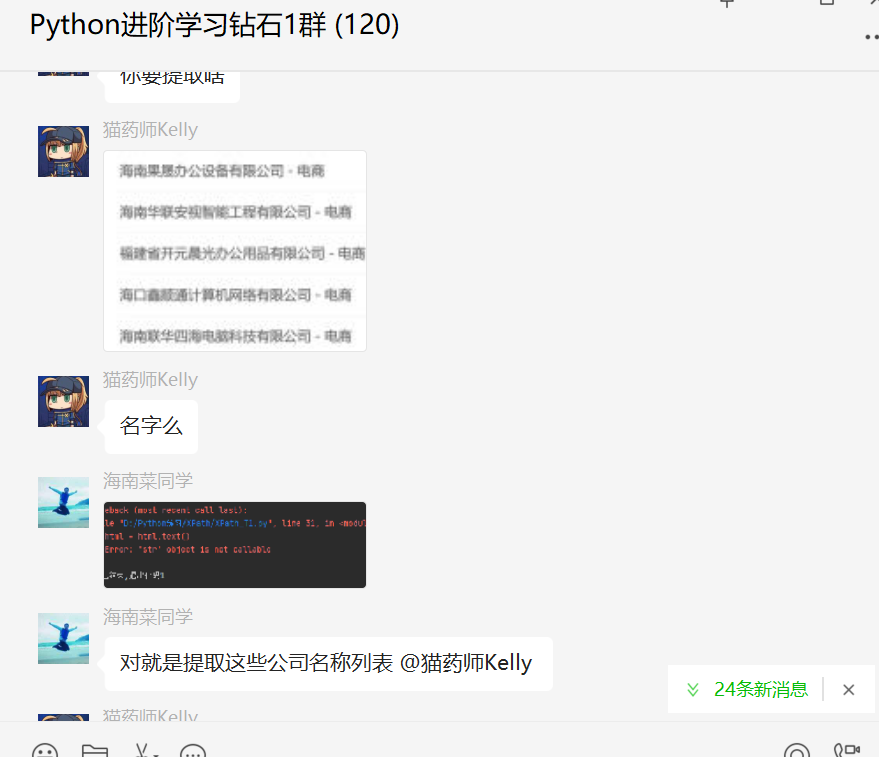
修改提取规则,运行之后可以顺利得到预期的文本:
运行之后,可以得到想要的结果:
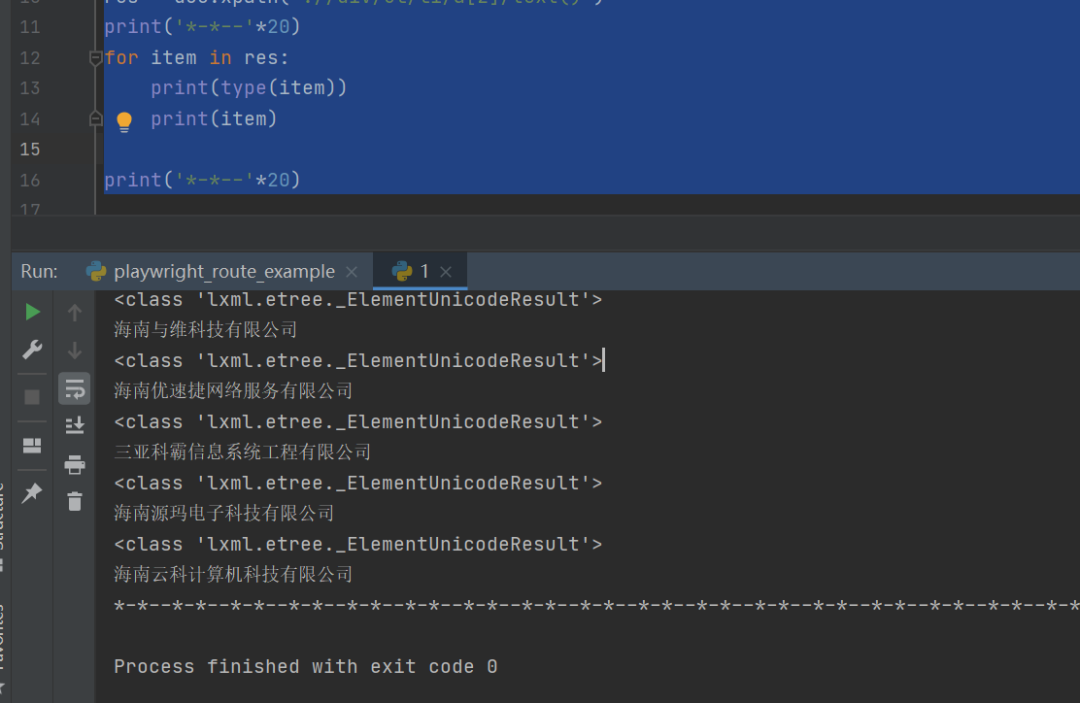
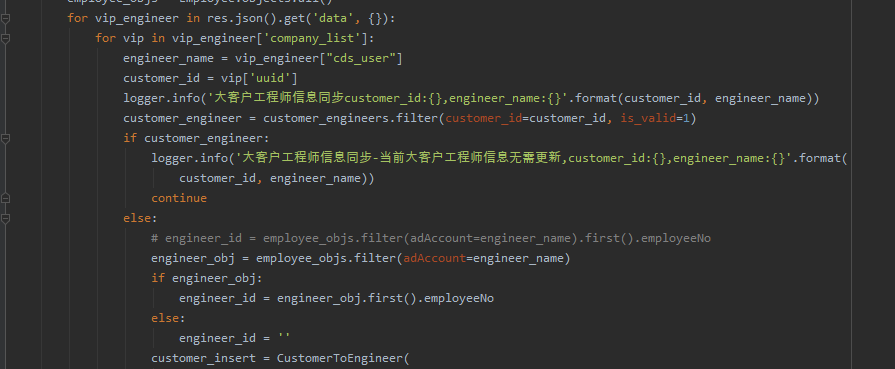
后来粉丝就顺利地解决了,代码如下所示:
import requests
url = "http://zw.hainan.gov.cn/wssc/emalls.html"
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36"
}
html = requests.get(url,headers=headers)
html = html.content.decode('utf-8')
doc = etree.HTML(html)
res = doc.xpath('.//div/ul/li/a[2]/text()')
print('*-*--'*20)
for item in res:
print(type(item))
print(item)
print('*-*--'*20)网络爬虫的时候,记得养成好习惯,加请求头啊!
三、总结
大家好,我是皮皮。这篇文章主要盘点了一个Python网络爬虫的问题,文中针对该问题给出了具体的解析和代码实现,帮助粉丝顺利解决了问题。
最后感谢粉丝【海南菜同学】提问,感谢【dcpeng】、【猫药师Kelly】、【薄荷味的鱼】给出的思路和代码解析,感谢【人间欢喜】、【此类生物】、【甯同学】等人参与学习交流。