大家好,我是皮皮。
一、前言
前几天在Python钻石交流群【髙鵬】问了一个Python网络爬虫的问题,提问截图如下:
原始代码如下:
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
driver = webdriver.Chrome()
driver.get("https://bookmaker.xyz/")
time.sleep(5)
# print(driver.page_source) # 网页原码
click1 = driver.find_element(By.XPATH, '//*[@id="games-navbar"]/div/div/div/div[1]/div/div/a[2]/div/span')
time.sleep(3)
click1.click()
# click2 = driver.find_element(By.XPATH, '//span[@class="Text_label-medium__uChzZ Text_c-white___3mSz" & '
# '@data-testid="opponents-title"]')
text = driver.find_element(By.LINK_TEXT, '//*Aston Villa - West Ham United')
time.sleep(5)
text.click()
# driver.close()
这里【D I Y】给了一个思路,如下图所示。
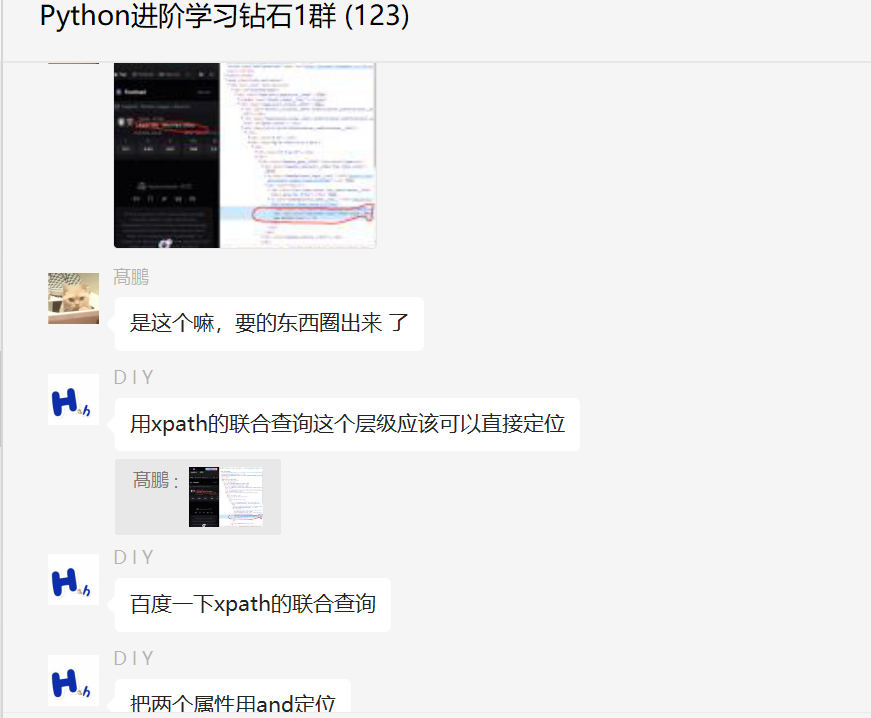
二、实现过程
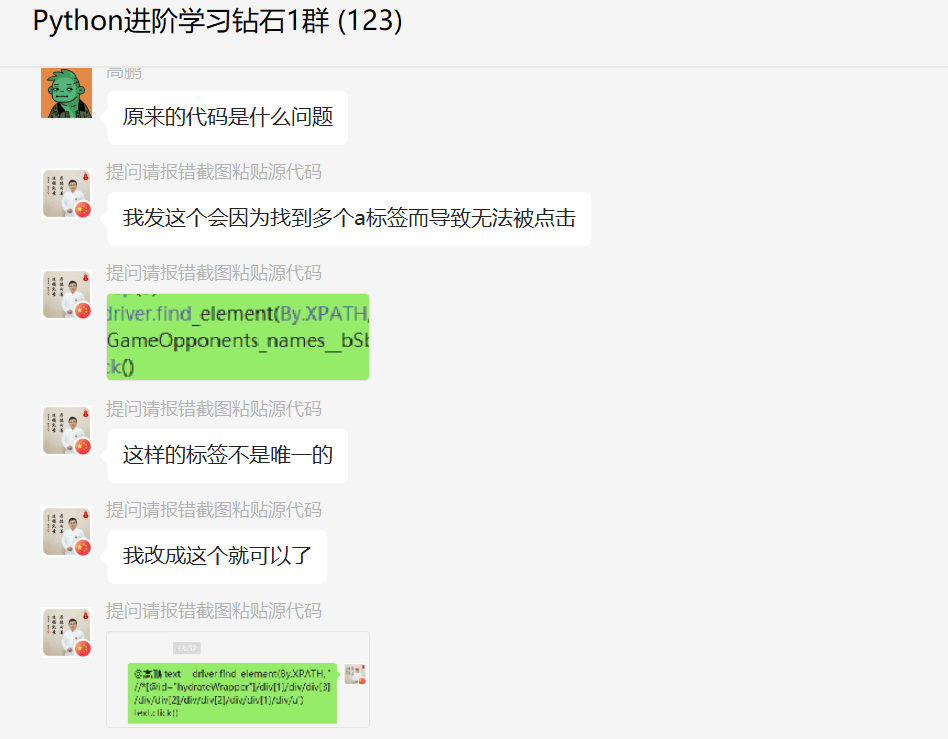
这里【瑜亮老师】给出了具体的思路,看上去方法还是很多的,如下所示。

最后给了一份代码如下所示:
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
driver = webdriver.Chrome()
driver.get("https://bookmaker.xyz/")
time.sleep(3)
text = driver.find_element(By.XPATH, '//a[@class="GameOpponents_names__bSbc_"]')
text.click()
顺利地解决了粉丝的问题。
三、总结
大家好,我是皮皮。这篇文章主要盘点了一个Python网络爬虫的问题,文中针对该问题给出了具体的解析和代码实现,帮助粉丝顺利解决了问题。
最后感谢粉丝【髙鵬】提问,感谢【瑜亮老师】、【D I Y】、【甯同学】、【此类生物】给出的思路和代码解析,感谢【dcpeng】、【冫马讠成】等人参与学习交流。