大家好,我是皮皮。
一、前言
前几天在Python钻石交流群【空】问了一个Python网络爬虫的问题,一起来看看吧。
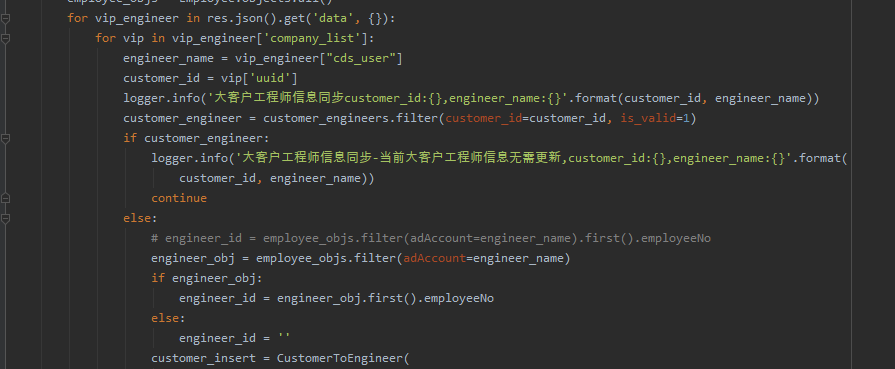
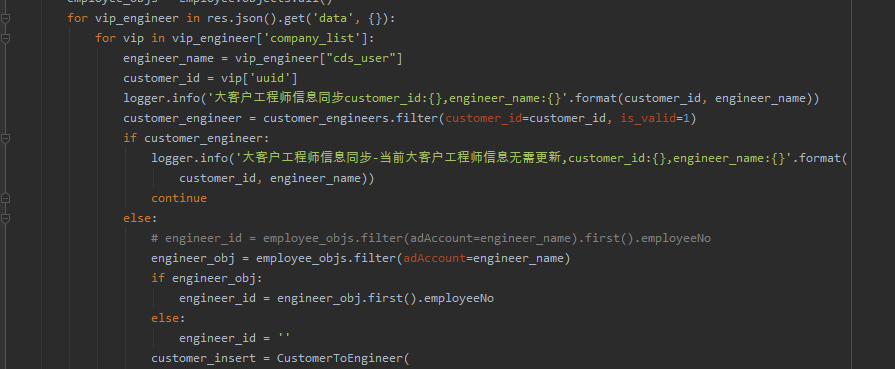
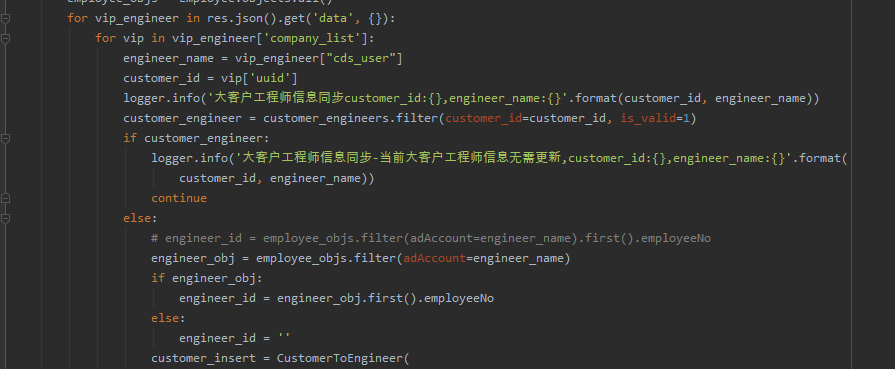
给大家提供一个网站的相关截图,麻烦你们提供一个思路如何爬取网站相关数据,下图这里是数据区。
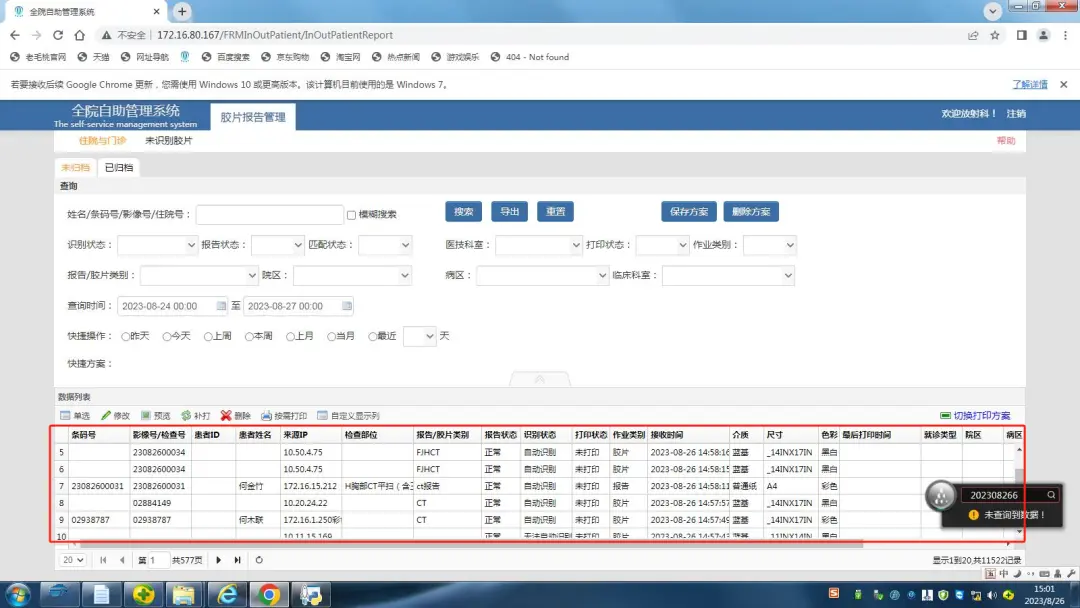
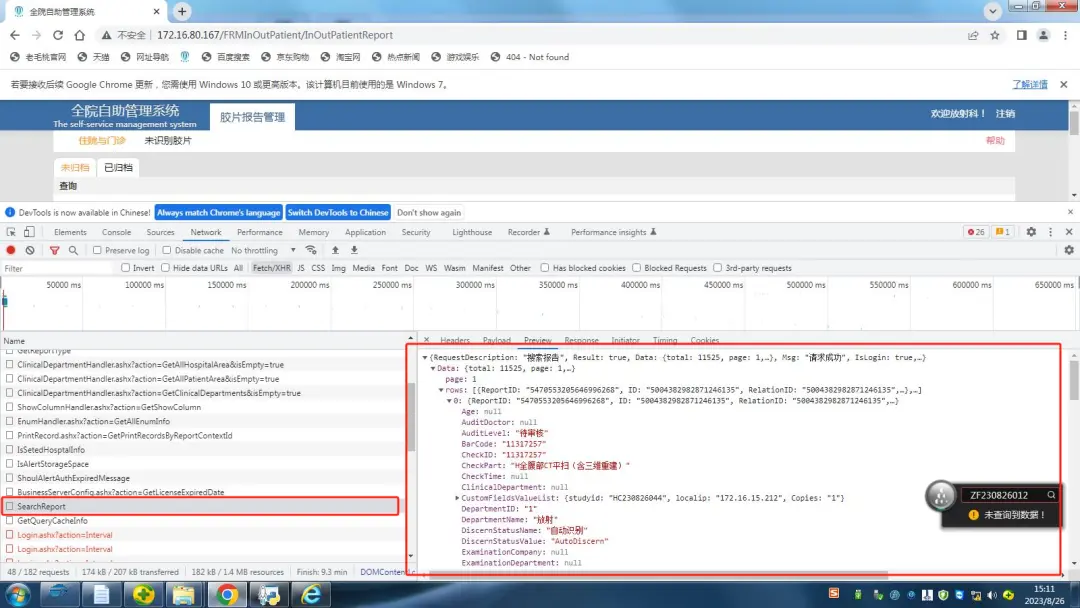
页面数据存储在这里的json里。
二、实现过程
常规来说,这个都返回json了,解析json就可以取数据了。但是json数据所对应的网址不能访问(内网,外边也无法访问),没有权限,估计是没有权限解析json数据。
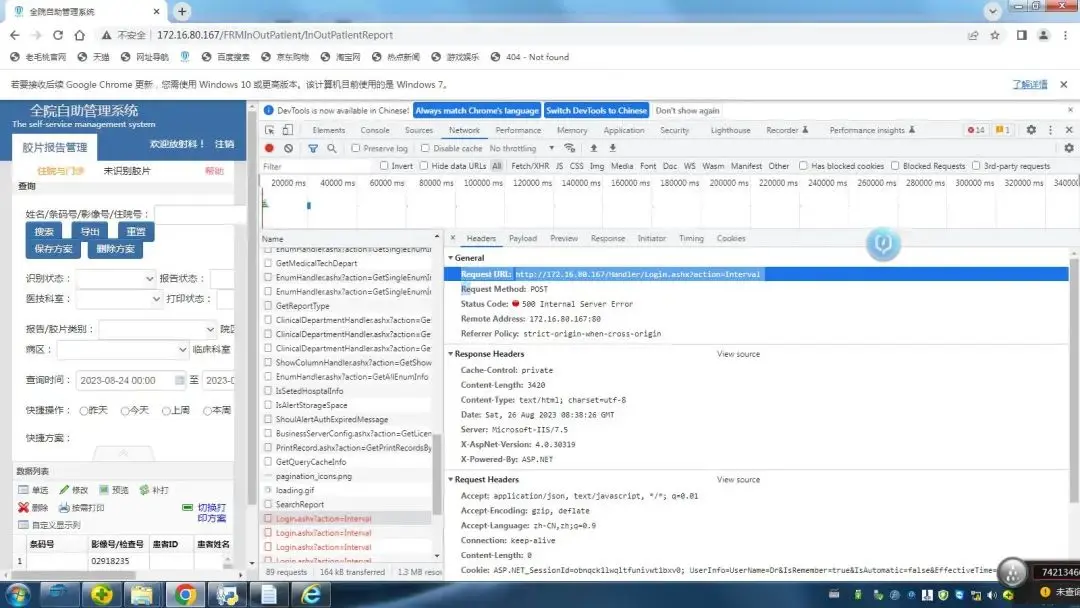
其它的数据里没有相关信息,都找了,页面全部都是用ajax加载数据。但是从页面数据找不到图的真实url,后来分析图的真实url,是页面的json数据通过拼接得到。这里的页面是不是需要登录才能获取相关权限,才能访问数据?这里【甯同学】给了一个可行的思路,如下所示:
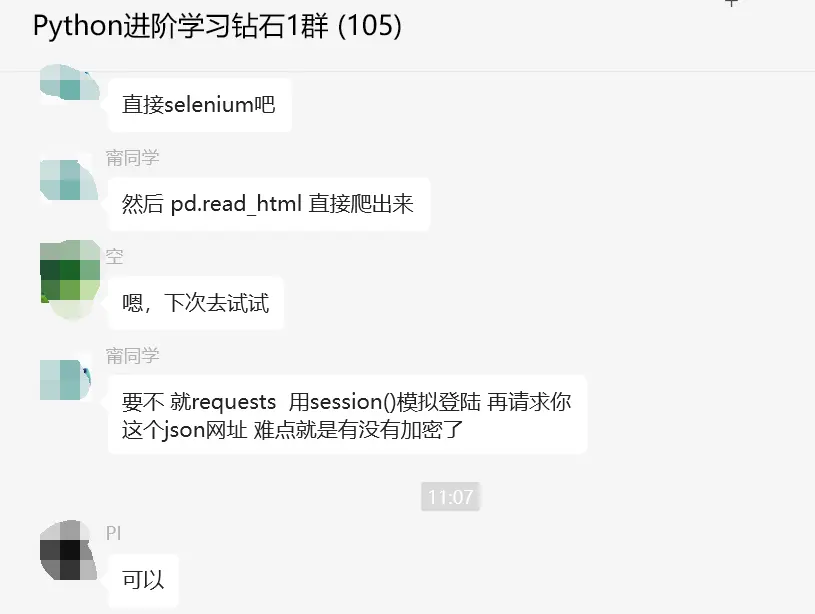
顺利地解决了粉丝的问题。
三、总结
大家好,我是皮皮。这篇文章主要盘点了一个Python网络爬虫处理的问题,文中针对该问题,给出了具体的解析和代码实现,帮助粉丝顺利解决了问题。
最后感谢粉丝【空】提问,感谢【甯同学】给出的思路和代码解析,感谢【莫生气】等人参与学习交流。
【提问补充】温馨提示,大家在群里提问的时候。可以注意下面几点:如果涉及到大文件数据,可以数据脱敏后,发点demo数据来(小文件的意思),然后贴点代码(可以复制的那种),记得发报错截图(截全)。代码不多的话,直接发代码文字即可,代码超过50行这样的话,发个.py文件就行。