推荐
专栏
教程
课程
飞鹅
本次共找到2376条
网络爬虫
相关的信息
Wesley13
•
4年前
java爬虫进阶 —— ip池使用,iframe嵌套,异步访问破解
写之前稍微说一下我对爬与反爬关系的理解一、什么是爬虫 爬虫英文是splider,也就是蜘蛛的意思,web网络爬虫系统的功能是下载网页数据,进行所需数据的采集。主体也就是根据开始的超链接,下载解析目标页面,这时有两件事,一是把相关超链接继续往容器内添加,二是解析页面目标数据,不断循环,直到没有url解析为止。举个栗子:我现在要爬取苏宁手机价
Stella981
•
4年前
Python3 网络爬虫:下载小说的正确姿势
点击上方“Python爬虫与数据挖掘”,进行关注回复“书籍”即可获赠Python从入门到进阶共10本电子书今日鸡汤少年心事当拂云。!(https://oscimg.oschina.net/oscnet/09902b71501b9e8c3cb656b5dfbbb0552e0.jpg)1
爬虫程序大魔王
•
3年前
rogerbot 爬虫介绍
Rogerbot是MozProCampaign网站审核的Moz爬虫。它与Dotbot不同,Dotbot是为链接索引提供支持的网络爬虫。访问您网站的代码以将报告发送回您的MozProCampaign。这可以帮助您了解您的网站并教您如何解决可能影响您的排名的问题。Rogerbot为您的站点抓取报告、按需抓取、页面优化报告和页面评分器
Python进阶者
•
3年前
盘点一个哔哩哔哩弹幕抓取并词云可视化的项目
大家好,我是皮皮。一、前言前几天在Python白银交流群【肉丸胡辣汤】问了一个Python网络爬虫和可视化的问题,提问截图如下:!(https://uploadimages.jianshu.io/upload_images/262
Python进阶者
•
3年前
盘点一个Python网络爬虫+正则表达式处理案例
大家好,我是Python进阶者。一、前言前几天在Python白银交流群【鑫】问了一个Python网络爬虫的问题,提问截图如下:!(https://uploadimages.jianshu.io/upload_images/2623
Python进阶者
•
3年前
盘点一个高德地图Python网络爬虫中前端数据和获取数据不一致问题
大家好,我是皮皮。一、前言前几天在Python钻石交流群【心田有垢生荒草】问了一个Python网络爬虫的问题,下图是截图:!(https://uploadimages.jianshu.io/upload_images/26
小白学大数据
•
2年前
python HTML文件标题解析问题的挑战
引言在网络爬虫中,HTML文件标题解析扮演着至关重要的角色。正确地解析HTML文件标题可以帮助爬虫准确地获取所需信息,但是在实际操作中,我们常常会面临一些挑战和问题。本文将探讨在Scrapy中解析HTML文件标题时可能遇到的问题,并提供解决方案。问题背景在
京东云开发者
•
2年前
《中国人民银行业务领域数据安全管理办法》与个人信息保护关键技术研究 | 京东云技术团队
在大数据环境下,通过个人用户网络活动产生的数据,可以清晰地分析出用户的年龄、职业、行为规律和兴趣爱好。特别是随着电子商务和移动网络的应用和普及,个人用户的地址、联系方式和银行账户信息也可以通过大数据挖掘或网络爬虫等手段获取。因此,个人信息安全管理压力增大,
小白学大数据
•
1年前
Scrapy爬虫:利用代理服务器爬取热门网站数据
在当今数字化时代,互联网上充斥着大量宝贵的数据资源,而爬虫技术作为一种高效获取网络数据的方式,受到了广泛的关注和应用。本文将介绍如何使用Scrapy爬虫框架,结合代理服务器,实现对热门网站数据的高效爬取,以抖音为案例进行说明。1.简介Scrapy是一个强大
Python进阶者
•
3年前
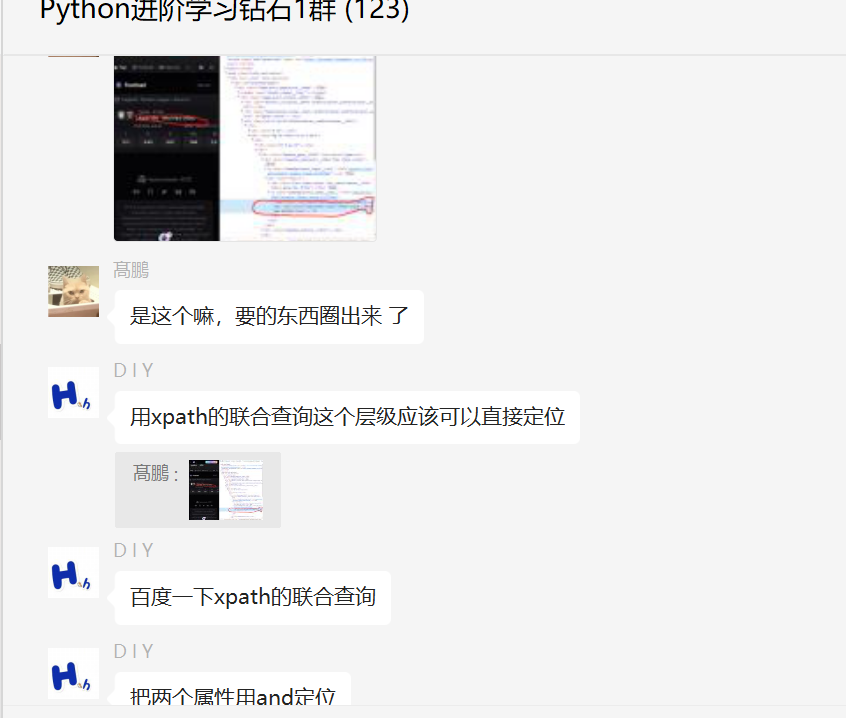
盘点Python网络爬虫过程中xpath的联合查询定位一个案例
大家好,我是皮皮。一、前言前几天在Python钻石交流群【髙鵬】问了一个Python网络爬虫的问题,提问截图如下:原始代码如下:importtimefromseleniumimportwebdriverfromselenium.webdriver.common.byimportBydriverwebdriver.Chrome()drive
1
•••
6
7
8
•••
238