大家好,我是皮皮。
一、前言
前几天在Python白银群【大侠】问了一个Python网络爬虫的问题,这里拿出来给大家分享下。
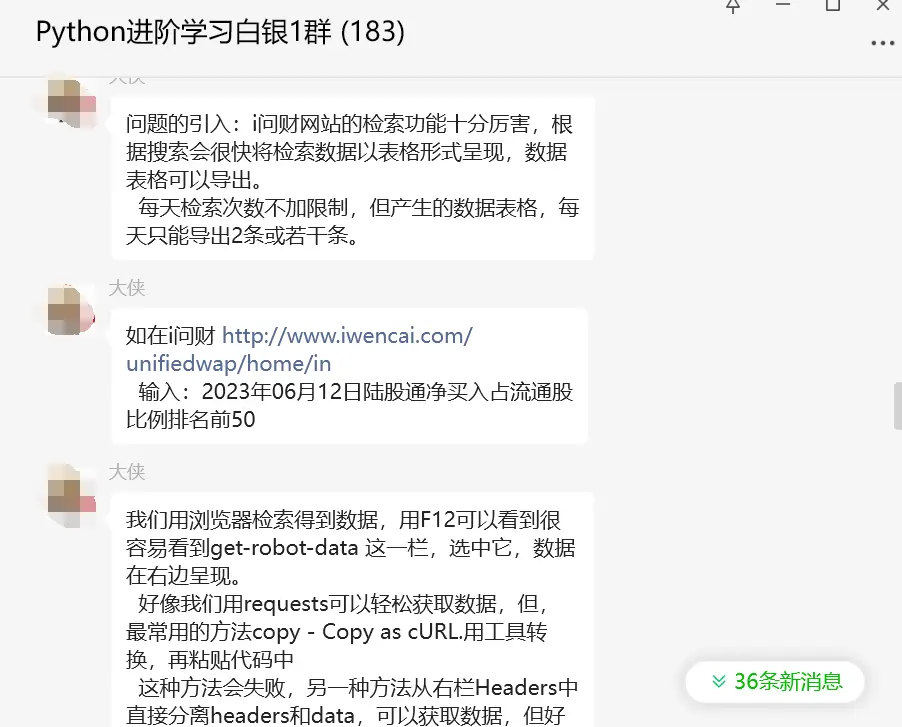
问题的引入:i问财网站的检索功能十分厉害,根据搜索会很快将检索数据以表格形式呈现,数据表格可以导出。
每天检索次数不加限制,但产生的数据表格,每天只能导出2条或若干条。
我们用浏览器检索得到数据,用F12可以看到很容易看到get-robot-data 这一栏,选中它,数据在右边呈现。
好像我们用requests可以轻松获取数据,但最常用的方法copy - Copy as cURL.用工具转换,再粘贴代码中。 这种方法会失败,另一种方法从右栏Headers中直接分离headers和data,可以获取数据,但好像运行2次后会报错。
看了君子协议,需要的信息是可以让抓的。
二、实现过程
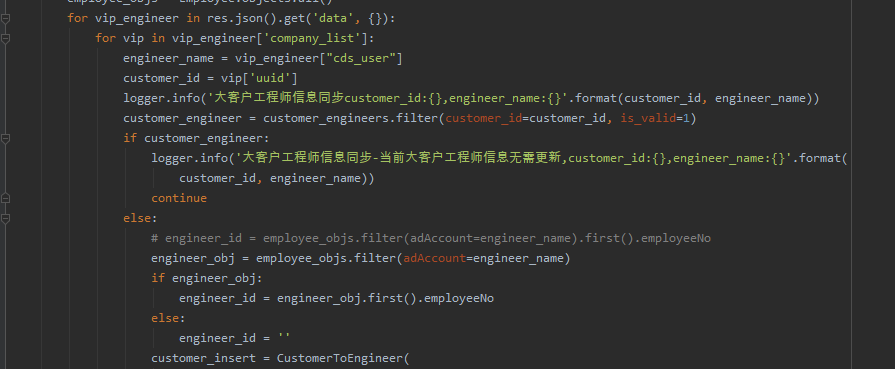
后来【瑜亮老师】给他搞定了,代码私发给了他。
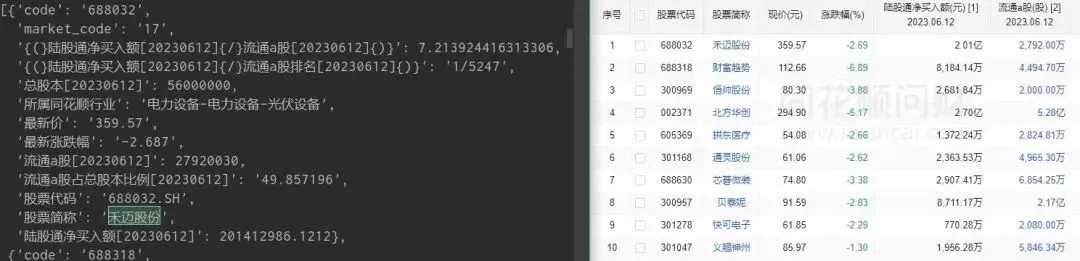
顺利地解决了粉丝的问题。
三、总结
大家好,我是皮皮。这篇文章主要盘点了一个Python网络爬虫的问题,文中针对该问题,给出了具体的解析和代码实现,帮助粉丝顺利解决了问题。
最后感谢粉丝【大侠】提问,感谢【瑜亮老师】给出的思路和代码解析,感谢【Ineverleft】等人参与学习交流。
【提问补充】温馨提示,大家在群里提问的时候。可以注意下面几点:如果涉及到大文件数据,可以数据脱敏后,发点demo数据来(小文件的意思),然后贴点代码(可以复制的那种),记得发报错截图(截全)。代码不多的话,直接发代码文字即可,代码超过50行这样的话,发个.py文件就行。