大家好,我是皮皮。
一、前言
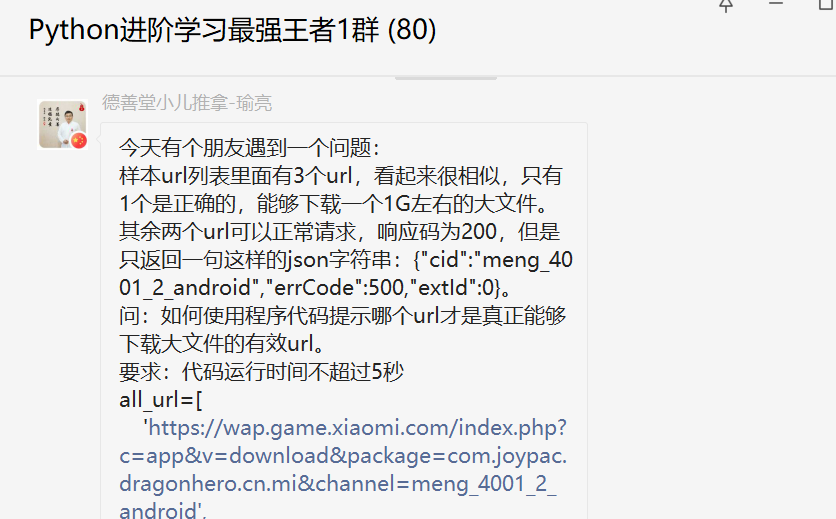
前几天在Python白银群【厚德载物】问了一个Python网络爬虫的问题,这里拿出来给大家分享下。
二、实现过程
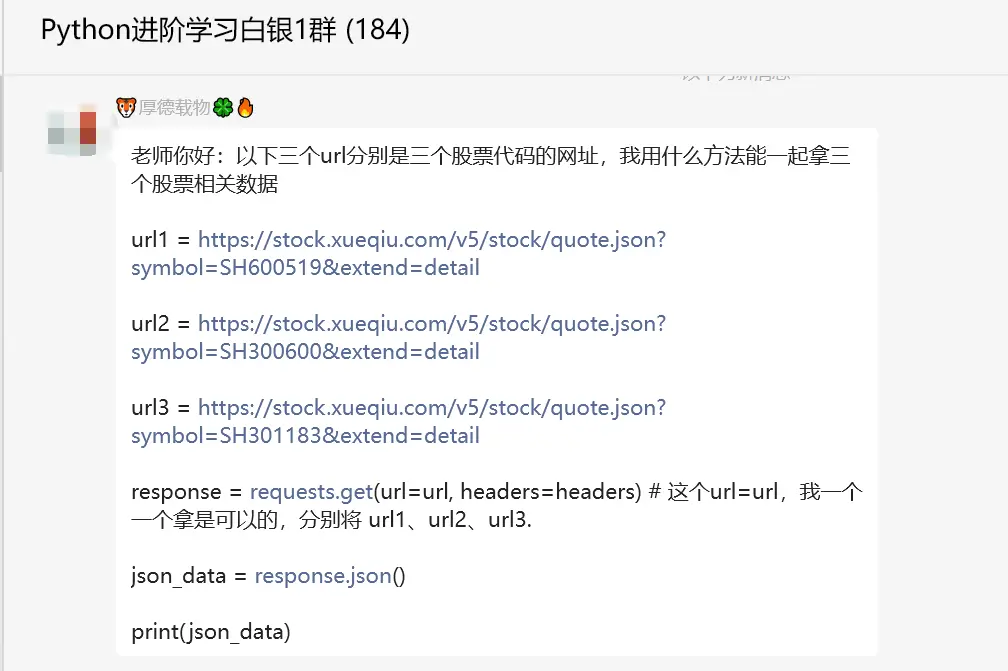
这个问题其实for循环就可以搞定了,看上去粉丝的代码没有带请求头那些,导致获取不到数据。后来【瑜亮老师】、【小王子】给了具体思路,代码如下图所示:
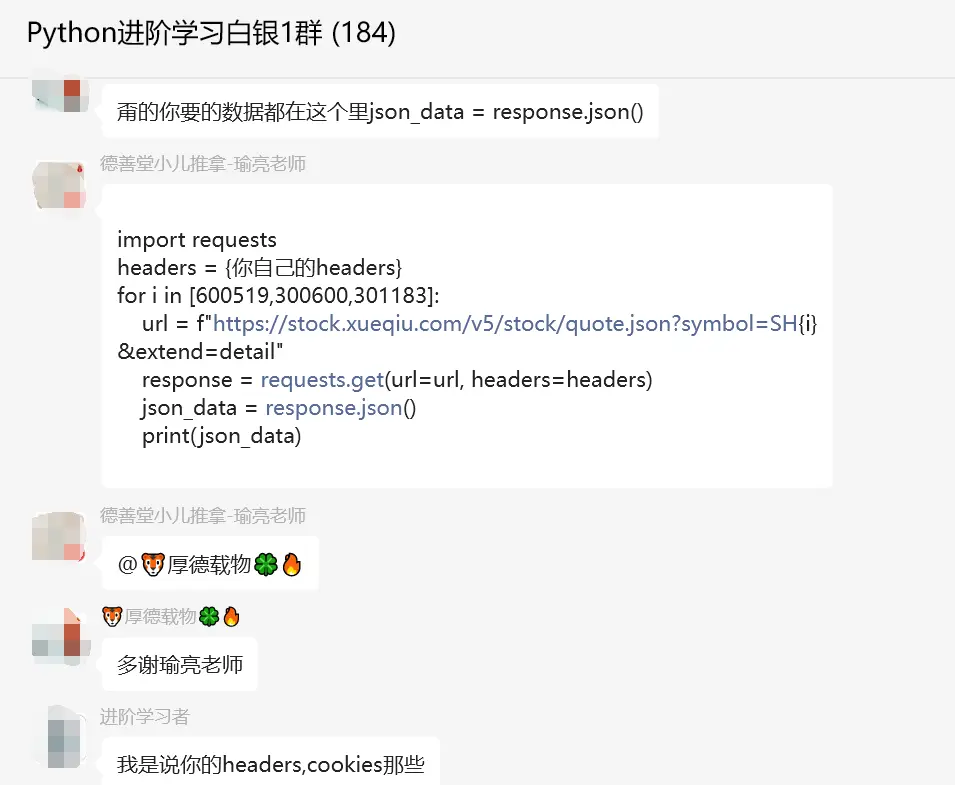
后来【小王子】也给了一个具体代码,如下:
import requests
import time
headers = {
"authority": "stock.xueqiu.com",
"accept": "*/*",
"accept-language": "zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6",
"origin": "https://xueqiu.com",
"referer": "https://xueqiu.com/S/SH600600",
"sec-ch-ua": "\"Not.A/Brand\";v=\"8\", \"Chromium\";v=\"114\", \"Microsoft Edge\";v=\"114\"",
"sec-ch-ua-mobile": "?0",
"sec-ch-ua-platform": "\"Windows\"",
"sec-fetch-dest": "empty",
"sec-fetch-mode": "cors",
"sec-fetch-site": "same-site",
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36 Edg/114.0.1823.51"
}
cookies = {
"xq_a_token": "57b2a0b86ca3e943ee1ffc69509952639be342b9",
"xqat": "57b2a0b86ca3e943ee1ffc69509952639be342b9",
"xq_r_token": "59c1392434fb1959820e4323bb26fa31dd012ea4",
"xq_id_token": "eyJ0eXAiOiJKV1QiLCJhbGciOiJSUzI1NiJ9.eyJ1aWQiOi0xLCJpc3MiOiJ1YyIsImV4cCI6MTY5MDMzMTY5OCwiY3RtIjoxNjg3ODcxOTQxNTM1LCJjaWQiOiJkOWQwbjRBWnVwIn0.KI3paq6_r2IZuM5AemhFqy5l1vVFsxf7ICELsem_rwAd0yYo_8bfOs1aP_5BBO3_rJuP9r6CJslCg1S_icefsPgqgtWZwVzfcIwvoLlZaag4a9IjqBxc2G6Ug50F9_UMLifzbNDrN4u8kwjm0sXHFUYnT_I89pwr0CeEgC4-jo9ExazlXJFZk_tA40C6L3npCVkKk8cOfl5JnvVUADXdef8G54jAsL_N5Sjx30YKxU1_2aUKRJZhRlN6bXqcXIP466odbBSBrMp52FFdB1knI2IN4dQJ5Hg4PRQyCsyFtgp-h_s_Rru4nwFqN6aiXPgLue1pGFGg25qBvTVr2m_9cQ",
"u": "561687871945884",
"device_id": "27b6ec56b772ea40c8582168f00a7604",
"Hm_lvt_1db88642e346389874251b5a1eded6e3": "1687871949",
"s": "ci1eygzbit",
"is_overseas": "0",
"Hm_lpvt_1db88642e346389874251b5a1eded6e3": "1687872001"
}
url = "https://stock.xueqiu.com/v5/stock/quote.json"
symbols = ['SH600600', 'SH600519', 'SH301183']
for symbol in symbols:
params = {
"symbol": f"{symbol}",
"extend": "detail"
}
response = requests.get(url, headers=headers, cookies=cookies, params=params)
time.sleep(3)
print(response.text)
print(response)代码运行之后,可以得到具体的结果,如下图所示:
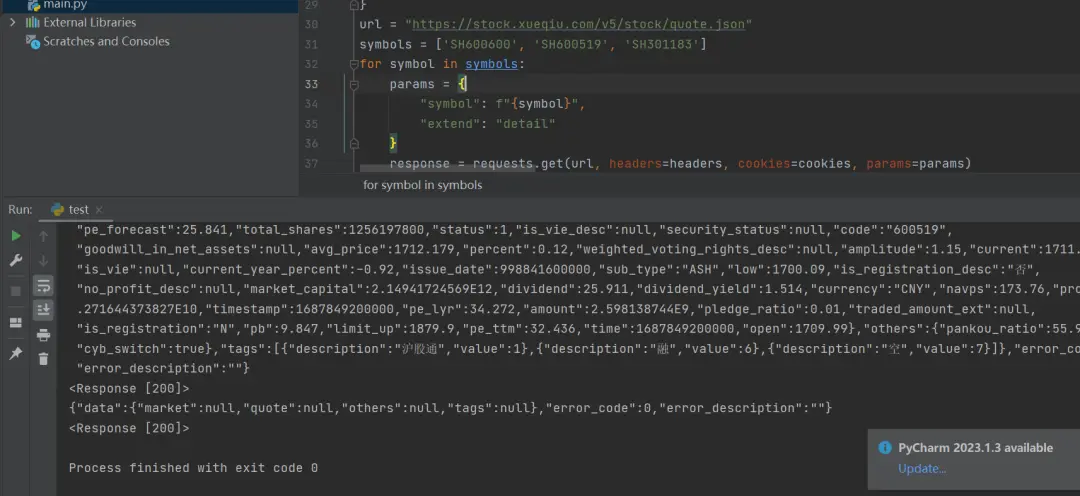
【瑜亮老师】后面还补充了一个代码,如下所示:
for i in ['SH600519','SZ300600','SZ301183']:
url = f"https://stock.xueqiu.com/v5/stock/quote.json?symbol={i}&extend=detail"
response = requests.get(url=url, headers=headers,cookies=cookies)
json_data = response.json()
print(json_data)顺利地解决了粉丝的问题。方法很多,条条大路通罗马,能解决问题就好。
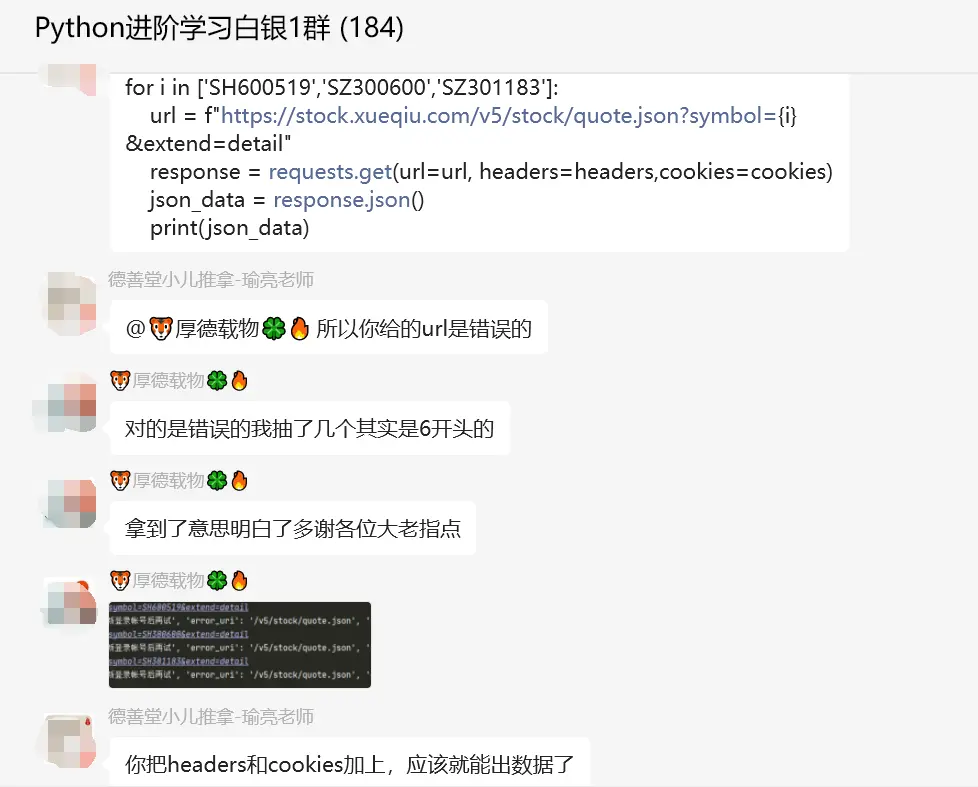
三、总结
大家好,我是皮皮。这篇文章主要盘点了一个Python网络爬虫的问题,文中针对该问题,给出了具体的解析和代码实现,帮助粉丝顺利解决了问题。
最后感谢粉丝【厚德载物】提问,感谢【瑜亮老师】、【魏哥】、【kim】、【巭孬嫑勥烎】给出的思路和代码解析,感谢【冫马讠成】、【Ineverleft】等人参与学习交流。
【提问补充】温馨提示,大家在群里提问的时候。可以注意下面几点:如果涉及到大文件数据,可以数据脱敏后,发点demo数据来(小文件的意思),然后贴点代码(可以复制的那种),记得发报错截图(截全)。代码不多的话,直接发代码文字即可,代码超过50行这样的话,发个.py文件就行。