大家好,我是皮皮。
一、前言
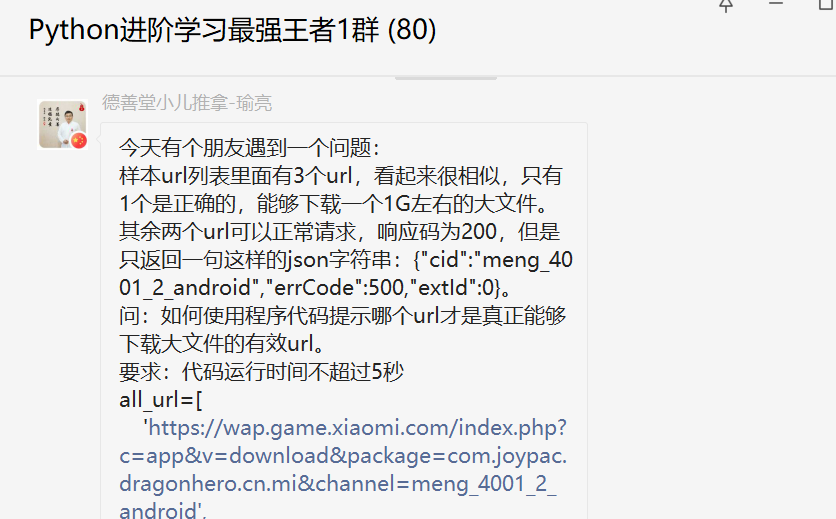
前几天在Python白银群【厚德载物】问了一个Python网络爬虫的问题,这里拿出来给大家分享下。

二、实现过程
这个问题其实for循环就可以搞定了,看上去粉丝的代码没有带请求头那些,导致获取不到数据。后来【瑜亮老师】、【小王子】给了具体思路,可以帮助粉丝解决问题。
后来他自己在运行的时候,还遇到了一个异常,报错如下:

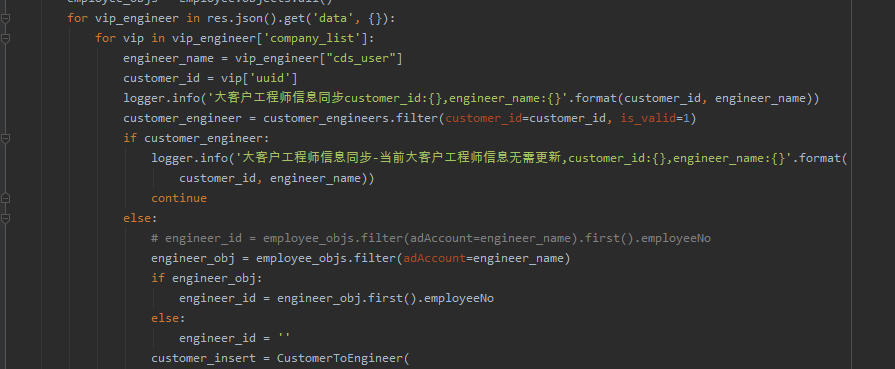
这个问题看上去应该是没获取到数据,后来【魏哥】针对该问题,给了一个异常处理方案,如下所示:
res = response.json()
try:
data = res["data"]
symbol1 = data["quote"]["symbol"]
name = data["quote"]["name"]
current = data["quote"]["current"]
chg = data["quote"]["chg"]
percent = data["quote"]["percent"]
print(symbol1, name, current, chg, percent)
with open('股票.csv', 'a+', encoding='utf-8') as f:
f.write('{},{},{},{},{}\n'.format(symbol1, name, current, chg, percent))
except:
print("该股票url无具体信息: ", symbol

不过后来这个异常处理,不被看好。这里【瑜亮老师】给优化了下程序,代码如下:
if res['data']['tags'] is not None:
data = res["data"]
symbol1 = data["quote"]["symbol"]
name = data["quote"]["name"]
current = data["quote"]["current"]
chg = data["quote"]["chg"]
percent = data["quote"]["percent"]
print(symbol1, name, current, chg, percent, " ==> 数据下载成功!")
with open('股票.csv', 'a+', encoding='utf-8') as f:
f.write('{},{},{},{},{}\n'.format(symbol1, name, current, chg, percent))
else:
print(f"{symbol}无具体信息: ", res)
time.sleep(1)后来测试发现,其实把if res['data']['tags'] is not None:中的 is not None可以去除,只不过加上的话,对新手比较友好。另外的话,用【瑜亮老师】代码中的if res['data']['tags']也是可以的,将判断中的标签改为if res['data']['quote']:,这样打印的时候,会更加直观一些。
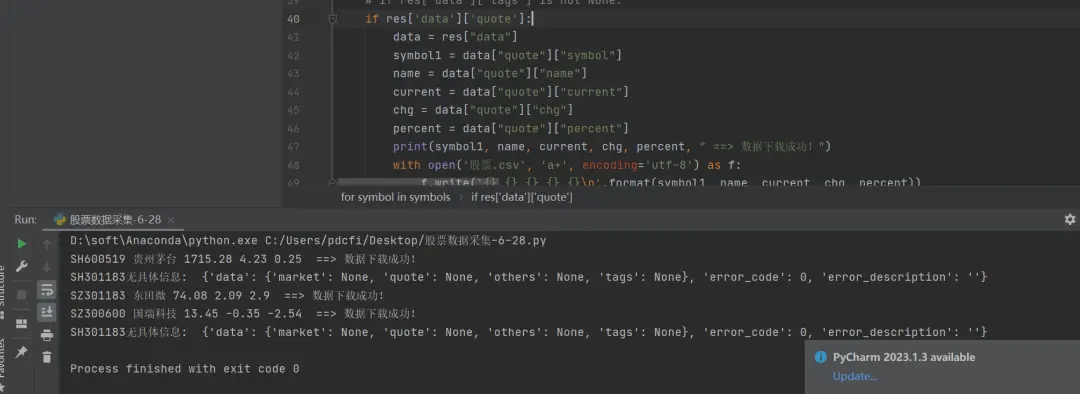
顺利地解决了粉丝的问题。方法很多,条条大路通罗马,能解决问题就好。
最后【kim】还分享了一个知识点,常见的类型报错原因,希望对大家的学习有帮助。

三、总结
大家好,我是皮皮。这篇文章主要盘点了一个Python网络爬虫的问题,文中针对该问题,给出了具体的解析和代码实现,帮助粉丝顺利解决了问题。
最后感谢粉丝【此类生物】提问,感谢【瑜亮老师】、【魏哥】、【kim】、【巭孬嫑勥烎】给出的思路和代码解析,感谢【冫马讠成】、【Ineverleft】等人参与学习交流。
【提问补充】温馨提示,大家在群里提问的时候。可以注意下面几点:如果涉及到大文件数据,可以数据脱敏后,发点demo数据来(小文件的意思),然后贴点代码(可以复制的那种),记得发报错截图(截全)。代码不多的话,直接发代码文字即可,代码超过50行这样的话,发个.py文件就行。