推荐
专栏
教程
课程
飞鹅
本次共找到172条
数据处理
相关的信息
Stella981
•
4年前
Redis 的落地策略
因为之前使用redis一般都只做热数据处理,没有考虑过落地方案,因此,通过很多次不同的交流,发现落地也挺重要的,特来学习一般。落地策略我们知道,redis是纯内存数据库,一旦发生宕机,数据就会丢失,因此,Redis的落地策略其实就是持久化(Persistence),主要有以下2种策略:1.RDB:定时快照方式(snapsho
Stella981
•
4年前
Kafka到底有几个Offset?——Kafka核心之偏移量机制
!(https://oscimg.oschina.net/oscnet/3ea57a5cd288c6bbc24521607f4e0aae21a.jpg) Kafka是由LinkIn开源的实时数据处理框架,目前已经更新到2.3版本。不同于一般的消息中间件,Kafka通过数据持久化和磁盘读写获得了极高的吞吐量,并可以不依赖Storm,SparkSt
混世魔王
•
2年前
我用皕杰报表的一点体会
算起来大概六七年前就接触了皕杰报表,那时我在公司信息部做数据处理小组的负责人,以前我们整理数据的方式,还是用传统的人工通过Excel整理,花费了很多时间做报表。但时效性和正确性都无法保障,做出来的报表几乎没用,根本没法支撑公司经营决策的需求。后来企业开始做
Python进阶者
•
2年前
Python自动化办公之PDF版本发票识别并提取关键信息实战教程(上篇)
大家好,我是皮皮。一、前言前几天在Python白银交流群【上海新年人】问了一个Python自动化办公发票数据处理的问题,一起来看看吧。二、实现过程这个问题在实际工作中还是非常常见的,实用性和通用性都比较强,历史文章中其实也有写过几篇文章,这里继续给大家敲敲
天翼云开发者社区
•
2年前
云服务器怎么搭建:从零到运行的基础指南
随着云计算技术的快速发展,云服务器已经成为企业和个人首选的计算服务。云服务器具有高性能、高可用性、安全可靠、灵活扩展等优势,能够满足各种大规模数据处理、存储、应用部署和管理等需求。本文将详细探讨云服务器的搭建,帮助读者从零开始构建并运行云服务器的基础设施。
京东云开发者
•
1年前
京东零售数据资产能力升级与实践
作者:京东零售韩雷钧开篇京东自营和商家自运营模式,以及伴随的多种运营视角、多种组合计算、多种销售属性等数据维度,相较于行业同等量级,数据处理的难度与复杂度都显著增加。如何从海量的数据模型与数据指标中提升检索数据的效率,降低数据存算的成本,提供更可信的数据内
天翼云开发者社区
•
1年前
高效时代,谁是DeepSeek部署的“最优解”?
在当今数字化浪潮中,随着文字、图像、音频、视频等多元数据处理需求不断涌现,大语言模型已成为推动行业智能化的关键力量。DeepSeek作为一款先进的大语言模型,能够轻松应对从基础问答到复杂数据分析的多种任务,为各行业带来前所未有的智能化体验,但同时也对底层云
京东云开发者
•
11个月前
ClickHouse 的“独孤九剑”:极速查询的终极秘籍
作者:京东零售夏百科引言在大数据时代的江湖,数据量呈爆炸式增长,如何高效地处理和分析海量数据成为了一个关键问题。各路英雄豪杰纷纷亮出自己的绝技,争夺数据处理的巅峰宝座。而在这场激烈的角逐中,ClickHouse以其“独孤九剑”般的绝世武功,横空出世,令群雄
近屿智能
•
9个月前
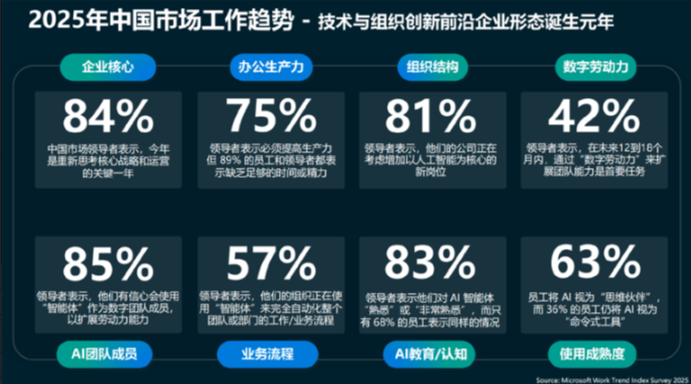
81%企业考虑增设AI岗位,近屿智能带你抢占先机!
微软《2025工作趋势指数》显示,81%中国企业计划增设AI专项岗位,智能体(数字员工)正以“自动化执行者”身份渗透至企业核心流程。从制造业流水线到客服系统,从数据处理到跨部门协作,AI的高效执行能力让不少人担忧:传统岗位会被颠覆吗?一方面,标准化、重复性
helloworld_54277843
•
3年前
大数据建模、分析、挖掘技术应用
时间2022年8月5日—2022年8月9日北京(同时转线上直播)(5日报到,6日9日上课)课程第一天一、大数据概述二、大数据处理架构Hadoop三、分布式文件系统HDFS四、分布式数据库HBase第二天五、MapReduce六、Spark七、IPythonNotebook运行PythonSpark程序八、PythonSpark集成开发环境第三
1
•••
12
13
14
•••
18