

Kafka是由LinkIn开源的实时数据处理框架,目前已经更新到2.3版本。不同于一般的消息中间件,Kafka通过数据持久化和磁盘读写获得了极高的吞吐量,并可以不依赖Storm,SparkStreaming的流处理平台,自己进行实时的流处理。
Kakfa的Offset机制是其最核心机制之一,由于API对于部分功能的实现,我们有时并没有手动去设置Offset,那么Kafka到底有几个Offset呢?
一、生产者Offset
首先,我们先来看生产者的offset,我们知道Kafka是通过生产者将消息发送给某一个topic,消费者再消费这个topic的消息,当然可能有多个生产者,多个消费者,还可能有消费者组的概念,这个稍后在讨论。
当生产者将消息发送给某一个topic时,要看有多少个分区,因为kafka是通过分区机制实现分布式的。
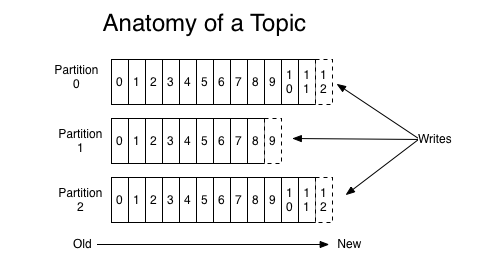
图 生产者offset
通过此图可以清晰的看到生产者的offset原理,不管是多少个生产者,还是我们规定了他们会写入哪一个分区,但只要他们写入的时候,一定是每一个分区都有一个offset,这个offset就是生产者的offset,同时也是这个分区的最新最大的offset。
有些时候我们在开发生产者代码时并没有指定某一个分区的offset,可能是我们使用的单分区,或者默认均匀的写入多个分区,这个工作kafka帮我们完成了。
二、消费者Offset
再来看消费者端offset,要稍微复杂一些。
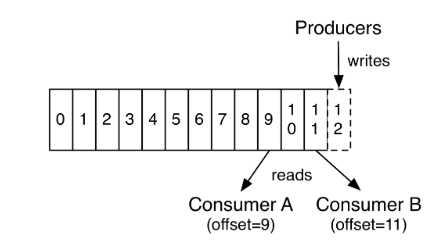
图 消费者offset
这是某一个分区的offset情况,我们已经知道生产者写入的offset是最新最大的值也就是12,而当Consumer A进行消费时,他从0开始消费,一直消费到了9,他的offset就记录在了9,Consumer B就纪录在了11。等下一次他们再来消费时,他们可以选择接着上一次的位置消费,当然也可以选择从头消费,或者跳到最近的记录并从“现在”开始消费。
这样即使有多个分区,消费者也能灵活使用。
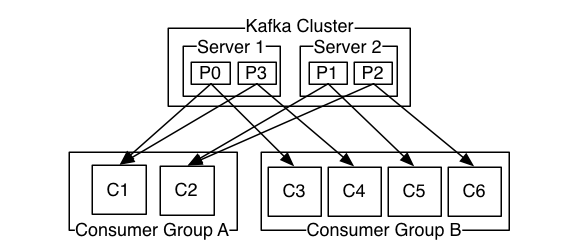
图 消费者组
消费者组的概念其实并不影响对offset的理解,上面的情况Consumer A,Consumer B如果是同组就不能同时消费一个分区的消息,不同组的消费者可以同时消费一个分区的消息。
还有一种offset的说法,就是consumer消费未提交时,本地是有另外一个offset的,这个offset不一定与集群中记录的offset一致。
所以,kafka每一个topic分区和生产者,消费者不同,是有多个offset的。
总结如下:
offset是指某一个分区的偏移量。
topic partition offset 这三个唯一确定一条消息。
生产者的offset其实就是最新的offset。
消费者的offset是他自己维护的,他可以选择分区最开始,最新,也可以记住他消费到哪了。
消费者组是为了不同组的消费者可以同时消费一个分区的消息。
更多Kafka相关技术文章:
什么是Kafka?
Kafka监控工具汇总
Kafka快速入门
Kafka核心之Consumer
Kafka核心之Producer
更多实时计算,Flink,Kafka等相关技术博文,欢迎关注实时流式计算

本文分享自微信公众号 - 实时流式计算(RealtimeBigdata)。
如有侵权,请联系 support@oschina.cn 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。











