推荐
专栏
教程
课程
飞鹅
本次共找到40条
xpath
相关的信息
徐小夕
•
5年前
《前端实战总结》之使用解释器模式实现获取元素Xpath路径的算法
前端领域里基于javascript的设计模式和算法有很多,在很多复杂应用中也扮演着很重要的角色,接下来就介绍一下javascript设计模式中的解释器模式,并用它来实现一个获取元素Xpath路径的算法。上期回顾《前端实战总结》之迭代器模式的N1种应用场景(https://juejin.im/post/6844904008616771591)
Wesley13
•
4年前
java程序实现JSON格式的报文转换成XPATH格式
注意:需要引入额外的jar包来支持这个程序“fastjson”。importcom.alibaba.fastjson.JSON;importcom.alibaba.fastjson.JSONObject;importjava.io.;publicclassTest{publicstaticvoidmain(String
公众号:码农乐园
•
4年前
基于Xposed自动化框架XposedAppium
基于Xposed做的一款自动化点击,滑动框架(基于安卓原生的事件分发)。可以模拟手指的一切操作,基于Xpath表达式获取View。此框架在virjar大佬的框架基础上进行的修改的,修复了部分Bug,添加常用方法等.在登入页面输入账号密码后,跳转到第二个Activity并点击对话框确定按钮。Xposed模块:很简单,添加对应的Activity,需要实Page
Wesley13
•
4年前
lxml简明教程
from:https://www.cnblogs.com/ospider/p/5911339.html最近要做下微信爬虫,之前写个小东西都是直接用正则提取数据就算了,如果需要更稳定的提取数据,还是使用xpath定位元素比较可靠。周末没事,从爬虫的角度研究了一下pythonxml相关的库。Python标准库中自带了xml模块,但是性能不
Stella981
•
4年前
Python网络爬虫四大选择器(正则表达式、BS4、Xpath、CSS)总结
前几天小编连续写了四篇关于Python选择器的文章,分别用正则表达式(https://www.oschina.net/action/GoToLink?urlhttps%3A%2F%2Fwww.toutiao.com%2Fi6511646916554523143%2F)、BeautifulSoup(https://www.oschina.net/ac
小白学大数据
•
7个月前
Python爬虫案例:Scrapy+XPath解析当当网网页结构
引言在当今大数据时代,网络爬虫已成为获取互联网信息的重要工具。作为Python生态中最强大的爬虫框架之一,Scrapy凭借其高性能、易扩展的特性受到开发者广泛青睐。本文将详细介绍如何利用Scrapy框架结合XPath技术解析当当网的商品页面结构,实现一个完
Python进阶者
•
3年前
数据提取之JSON与JsonPATH
大家好,我是Python进阶者。背景介绍我们知道再爬虫的过程中我们对于爬取到的网页数据需要进行解析,因为大多数数据是不需要的,所以我们需要进行数据解析,常用的数据解析方式有正则表达式,xpath,bs4,这次我们来介绍一下另一个数据解析库jsonpath,在此之前我们需要先了解一下什么是json。一、初识JsonJSON(JavaScriptObjec
Python进阶者
•
3年前
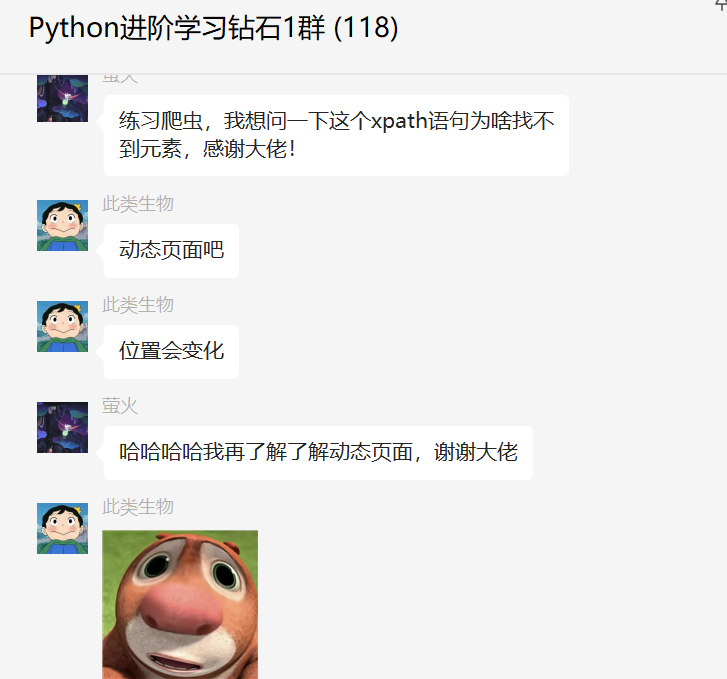
练习爬虫,我想问一下这个xpath语句为啥找不到元素,感谢大佬!
大家好,我是皮皮。一、前言前几天在Python钻石交流群【萤火】问了一个Python网络爬虫的问题,下图是截图:下图是报错截图:二、实现过程这里【error】给了一个代码,如下所示,满足粉丝的需求:用selenium没找到的话,大概率是网页还没渲染出来,代码就运行到了抓取规则,所以抓不到。其实他的匹配规则是可以拿到数据的,只不过用jupyter运行sel
Python进阶者
•
3年前
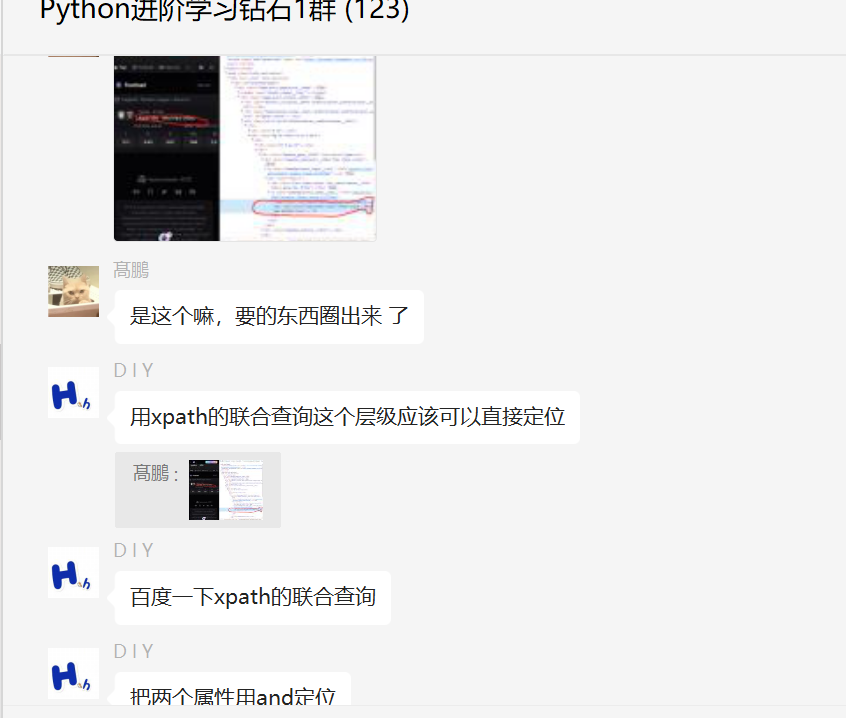
盘点Python网络爬虫过程中xpath的联合查询定位一个案例
大家好,我是皮皮。一、前言前几天在Python钻石交流群【髙鵬】问了一个Python网络爬虫的问题,提问截图如下:原始代码如下:importtimefromseleniumimportwebdriverfromselenium.webdriver.common.byimportBydriverwebdriver.Chrome()drive
Python进阶者
•
2年前
xpath的一次性同时获取a标签和p标签的内容?(下篇)
大家好,我是皮皮。一、前言前几天在Python白银交流群【上海新年人】问了一个Python网络爬虫数据提取的问题,一起来看看吧。他的需求就是:xpath的一次性同时获取a标签和p标签的内容。上一篇文章中,大佬们已经给出了一个答案,可是数据获取下来后发现和网
1
2
3
4