
前端领域里基于javascript的设计模式和算法有很多,在很多复杂应用中也扮演着很重要的角色,接下来就介绍一下javascript设计模式中的解释器模式,并用它来实现一个获取元素Xpath路径的算法。
上期回顾
正文
1.解释器模式
对于一种语言,我们给出其文法表示形式(一种语言中的语法描述工具,用来定义语言的规则),并定义一种解释器,通过这种解释器来解释语言中定义的句子。
定义听起来可能比较抽象,举个例子比如我们常见的网站多语言,要实现多语言我们首先要预定语言的类型,提前设计不同语言的语料库,然后我们会根据配置和统一的变量规则来映射到不同语言。
2.元素的Xpath路径
XPath 用于在 XML 文档中通过元素和属性进行导航。虽然XPath 是用来查找XML节点,但同样可以用来查找HTML文档中的节点,因为HTML和XML结构类似。这里我们只考虑html,即元素在html页面中所处的路径。
那么如何快速获取元素的Xpath路径呢?其实也很简单,我们打开谷歌调试工具:
 选中某个元素,如下,单机鼠标右键:
选中某个元素,如下,单机鼠标右键:
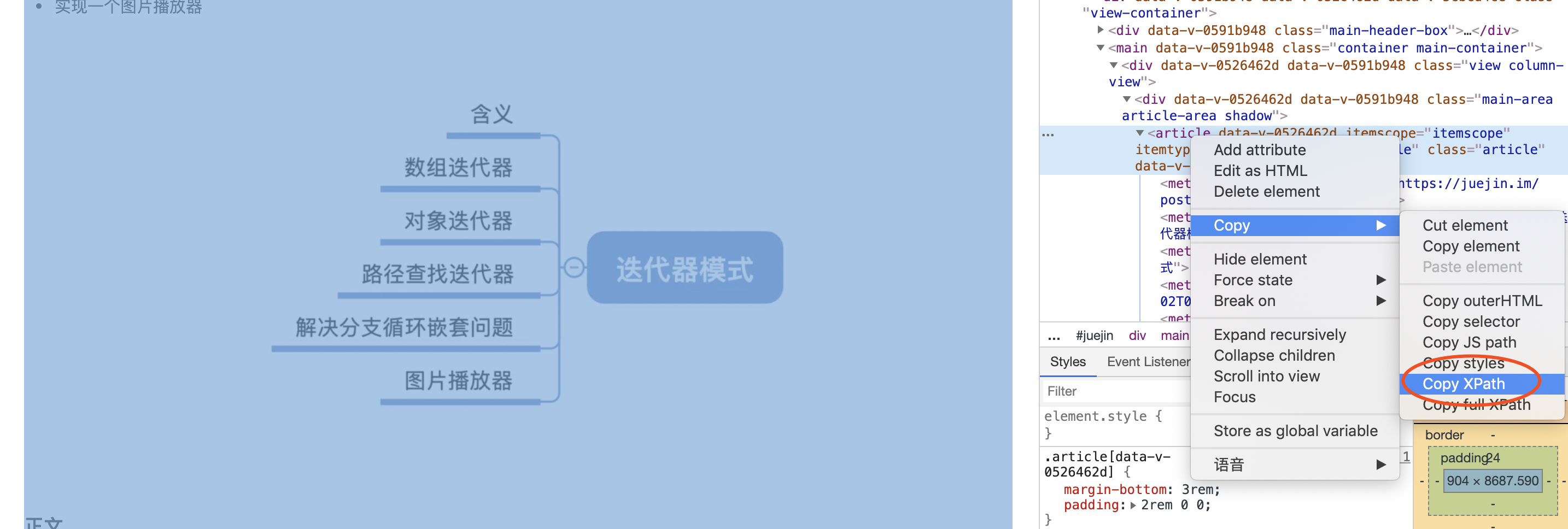 选中Copy XPath即可复制元素的Xpath路径。格式可能长这样:
选中Copy XPath即可复制元素的Xpath路径。格式可能长这样:
//*[@id="juejin"]/div[2]/main/div/div[1]/article/div[1]获取元素Xpath路径的应用场景很多,比如我们经常使用的python爬虫,利用爬虫框架可以通过Xpath路径很方便额控制页面中的某个dom节点,进而获取想要的数据和元素;又比如我们通过发送元素的Xpath路径给后端,后端可以统计某一功能的使用情况和交互数据;又比如分析用户在网站中浏览的热力分布图,路径画像等等。
3.js实现获取元素的Xpath路径
在实现之前,首先我们分析一下Xpath路径的结构,比如我们有一个页面,元素span的结构如下:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<meta http-equiv="X-UA-Compatible" content="ie=edge">
<title>Document</title>
</head>
<body>
<div>
<span>我是徐小夕</span>
</div>
</body>
</html>那么我们的Xpath路径可能长这样:
HTML/BODY|HEAD/DIV/SPAN从上面可以看出,我们的最右边一个元素都是目标元素,而最左边第一个元素都是最外层容器。要完成这个过程首先我们要通过元素的parentNode来获取当前元素的父元素,直到找到最顶层位置。但我们还需要注意的一点是,每找到上一层我们还要遍历该元素前面的兄弟元素previousSibling,如果这个兄弟元素名字和它后面的元素名字相同,则在元素名上+1.
第一步我们先实现一个遍历同级兄弟元素的方法getSameLevelName:
// 获取兄弟元素名称
function getSameLevelName(node){
// 如果存在兄弟元素
if(node.previousSibling) {
let name = '', // 返回的兄弟元素名称字符串
count = 1, // 紧邻兄弟元素中相同名称元素个数
nodeName = node.nodeName,
sibling = node.previousSibling;
while(sibling){
if(sibling.nodeType == 1 && sibling.nodeType === node.nodeType && sibling.nodeName){
if(nodeName == sibling.nodeName){
name += ++count;
}else {
// 重制相同紧邻节点名称节点个数
count = 1;
// 追加新的节点名称
name += '|' + sibling.nodeName.toUpperCase()
}
}
sibling = sibling.previousSibling;
}
return name
}else {
// 不存在兄弟元素返回''
return ''
}
}第二步,遍历文档树。
// XPath解释器
let Interpreter = (function(){
return function(node, rwrap){
// 路径数组
let path = [],
// 如果不存在容器节点,默认为document
wrap = rwrap || document;
// 如果当前节点等于容器节点
if(node === wrap) {
if(wrap.nodeType == 1) {
path.push(wrap.nodeName.toUpperCase())
}
return path
}
// 如果当前节点的父节点不等于容器节点
if(node.parentNode !== wrap){
// 对当前节点的父节点执行遍历操作
path = arguments.callee(node.parentNode, wrap)
}
// 如果当前节点的父元素节点与容器节点相同
else {
wrap.nodeType == 1 && path.push(wrap.nodeName.toUpperCase())
}
// 获取元素的兄弟元素的名称统计
let siblingsNames = getSameLevelName(node)
if(node.nodeType == 1){
path.push(node.nodeName.toUpperCase() + siblingsNames)
}
// 返回最终的路径数组结果
return path
}
})()有了这两个方法,我们就可以轻松获取元素的XPath路径啦,比如:
let path = Interpreter(document.querySelector('span'))
console.log(path.join('/'))这样会返回开篇的一样的数据结构了.如:HTML/BODY|HEAD/DIV/SPAN
最后
如果想了解更多webpack,node,gulp,css3,javascript,nodeJS,canvas等前端知识和实战,欢迎在公众号《趣谈前端》加入我们一起学习讨论,共同探索前端的边界。

更多推荐
- 《前端实战总结》之使用CSS3实现酷炫的3D旋转透视
- 《前端实战总结》之使用pace.js为你的网站添加加载进度条
- 《前端实战总结》之设计模式的应用——备忘录模式
- 《前端实战总结》之使用postMessage实现可插拔的跨域聊天机器人
- 《前端实战总结》之变量提升,函数声明提升及变量作用域详解
- 《前端实战总结》如何在不刷新页面的情况下改变URL
- 一张图教你快速玩转vue-cli3
- vue高级进阶系列——用typescript玩转vue和vuex
- 基于nodeJS从0到1实现一个CMS全栈项目(上)
- 基于nodeJS从0到1实现一个CMS全栈项目(中)
- 基于nodeJS从0到1实现一个CMS全栈项目(下)
- 5分钟教你用nodeJS手写一个mock数据服务器
- 用css3实现惊艳面试官的背景即背景动画(高级附源码)
- 教你用200行代码写一个爱豆拼拼乐H5小游戏(附源码)
- 笛卡尔乘积的javascript版实现和应用














