推荐
专栏
教程
课程
飞鹅
本次共找到40条
xpath
相关的信息
python知道
•
4年前
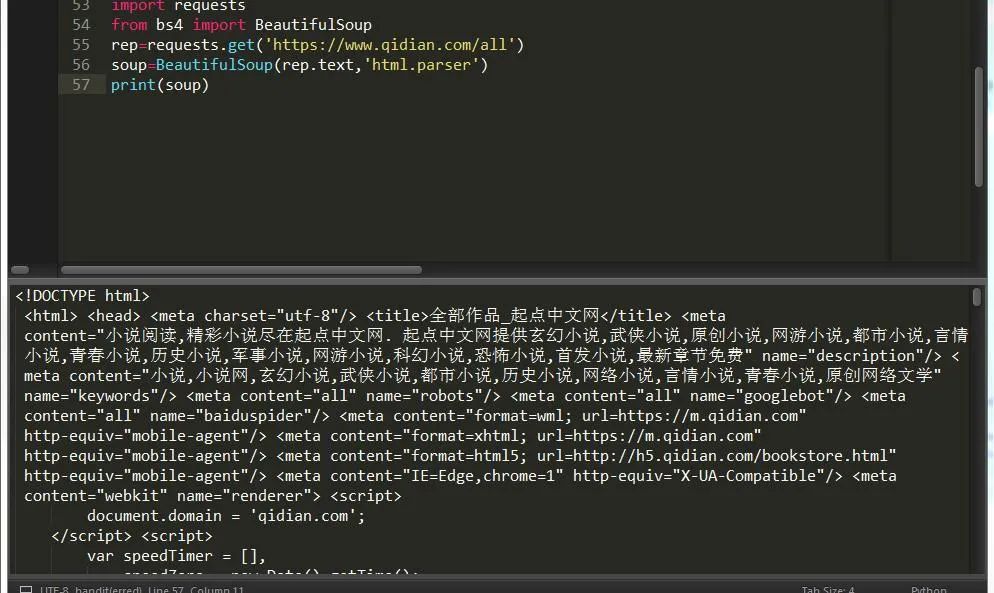
《Python3网络爬虫开发实战》
提取码:1028内容简介······本书介绍了如何利用Python3开发网络爬虫,书中首先介绍了环境配置和基础知识,然后讨论了urllib、requests、正则表达式、BeautifulSoup、XPath、pyquery、数据存储、Ajax数据爬取等内容,接着通过多个案例介绍了不同场景下如何实现数据爬取,后介绍了pyspider框架、S
Irene181
•
4年前
深入解析网页结构解析模块beautifulsoup
大家好,我是Python进阶者,今天给大家分享一个网页结构解析模块beautifulsoup。前言beautifulsoup(以下简称bs),是一款网页结构解析模块,它支持传统的Xpath,css selector语法,可以说很强大了,下面我们就来着重介绍下它的用法。安装bs可以使用pip或者easy\install安装,方便快捷。pip in
Stella981
•
4年前
Python爬虫:现学现用xpath爬取豆瓣音乐
爬虫的抓取方式有好几种,正则表达式,Lxml(xpath)与BeautifulSoup,我在网上查了一下资料,了解到三者之间的使用难度与性能三种爬虫方式的对比。!(https://oscimg.oschina.net/oscnet/2daa493a02eeb49299b1ab6db462cb42124.png)这样一比较我我选择了Lx
Stella981
•
4年前
C#使用Selenium实现QQ空间数据抓取 说说抓取
上一篇讲的是如何模拟真人操作登录QQ空间,本篇主要讲述一下如何抓取QQ说说数据继续登录空间后的操作登陆后我们发现QQ空间的菜单其实是固定的,只需要找到对应元素就可以,继续XPath!(https://images2018.cnblogs.com/blog/318685/201808/3186852018082909444441195851
Stella981
•
4年前
Python Xpath 提取html整个元素(标签与内容)
提取html某标签中文字时,文字中含有:“<sub2</subO<sub5</sub”,导致提取的文字不符合预期。解决方法:codingutf8fromlxmlimportetreefromHTMLParserimportHTMLParserhtmlu'''<h
Stella981
•
4年前
Seleinum_CSS定位方式
转载:https://www.cnblogs.com/longronglang/p/9144661.htmlCSS选择器:常见符号:表示id选择器.表示class选择器\表示子元素,层级一个空格也表示子元素,但是是所有的后代子元素,相当于xpath中的相对路径一、css:属性定
京东云开发者
•
2年前
Jayway JsonPath-提取JSON文档内容的Java DSL | 京东物流技术团队
介绍JsonPath是一种能够提取部分JSON文档属性、对象、数组的语法,支持条件过滤、数学运算、字符串处理等功能。JsonPath与JSON文档就像XPath表达式与XML文档结合使用一样。由于JSON结构通常是匿名的,并不一定和XML一样具有“根成员对
Python进阶者
•
1年前
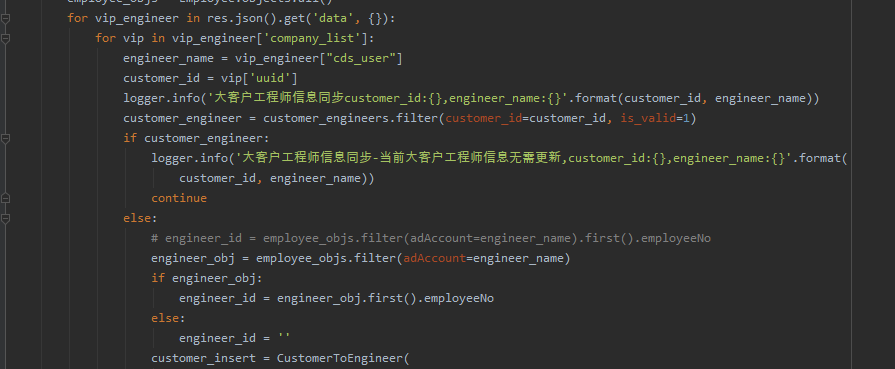
Python爬取免费IP代理时,无法解析到数据
大家好,我是Python进阶者。一、前言前几天在Python最强王者交流群【ZXS】问了一个Python网络爬虫实战问题。问题如下:我这里遇到一个问题:【爬取免费IP代理时,无法解析到数据】,我通过xpath,css定位到了元素,但是在运行时返回空列表,请
Python进阶者
•
1年前
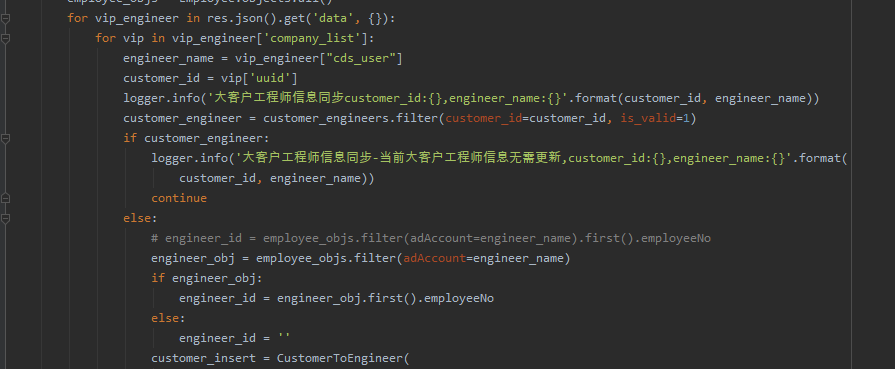
麻烦问一下xpath标签定位的这个索引是做什么用的?
大家好,我是Python进阶者。一、前言前几天在Python最强王者交流群【杨又串🍻】问了一个Python网络爬虫的问题,问题如下:老师,麻烦问一下xpath标签定位的这个索引是做什么用的,我听网课把这个知识点跳过了?二、实现过程后来【隔壁😼山楂】给了
Python进阶者
•
1年前
怎么用xpath写drissionpage?或者用相对位置?
大家好,我是Python进阶者。一、前言前几天在Python最强王者交流群【黑科技·鼓包】问了一个Python网络爬虫处理的问题。问题如下:有没有大佬指点下怎么用xpath写drissionpage?或者用相对位置?我看了半天中文文档硬是写不出来。这是xp
1
2
3
4