推荐
专栏
教程
课程
飞鹅
本次共找到2932条
python爬虫
相关的信息
Python进阶者
•
3年前
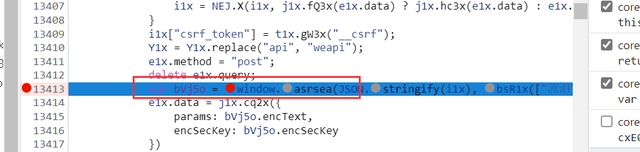
Jsrpc学习——网易云热评加密函数逆向
大家好,我是皮皮。前几天给大家分享jsrpc的介绍篇,Python网络爬虫之js逆向之远程调用(rpc)免去抠代码补环境简介,感兴趣的小伙伴可以戳此文前往。今天给大家来个jsrpc实战教程,Jsrpc学习——Cookie变化的网站破解教程,让大家继续加深对jsrpc的理解和认识。下面是具体操作过程,不懂的小伙伴可以私我。1、因为网易云音乐热评的加密并不在co
宙哈哈
•
2年前
恶意爬虫?能让恶意爬虫遁于无形的小Tips
验证码是阻挡机器人攻击的有效实践,网络爬虫,又被称为网络机器人,是按照一定的规则,自动地抓取网络信息和数据的程序或者脚本。如何防控,这里简单提供几个小Tips。
Wesley13
•
4年前
Java爬虫——常用的maven依赖
java实现爬虫常用的第三方包:httpclient,forhttpjsoup,fordomrhino,forjsjackson,forjsonpom.xml摘录<dependencies<!simulatewebbrowser
Stella981
•
4年前
HtmlExtractor 1.1 发布,网页信息抽取组件
HtmlExtractor(https://www.oschina.net/action/GoToLink?urlhttps%3A%2F%2Fgithub.com%2Fysc%2FHtmlExtractor)是一个Java实现的基于模板的网页结构化信息精准抽取组件,本身并不包含爬虫功能,但可被爬虫或其他程序调用以便更精准地对网页结构化信息进行抽取。
Wesley13
•
4年前
Java网络爬虫(十三)
先说点题外话吧,在我刚开始学习爬虫的时候,有一次一个学长给了我一个需求,让我把京东图书的相关信息抓取下来。恩,因为真的是刚开始学习爬虫,并且是用豆瓣练得手,抓取了大概500篇左右的影评吧,然后存放到了mysql中,当时觉得自己厉害的不行,于是轻松的接下了这个需求。。。然后信心满满的开始干活。。首先查看网页源代码。。。???我需要的东西源代码里面没有!!!
Wesley13
•
4年前
Ubuntu中使用RoboMongo实现MongoDB的可视化
在运行爬虫的过程中,考虑到将数据存储到数据库会更加方便查看和测试,所以使用了mongodb存储爬虫结果。在Ubuntu中,对MongoDB的操作都是在命令窗口中进行的,无法以图标的形式直接查看整个数据库的状态和其中的内容。在学习极客学院的爬虫教程中,老师在windows系统中使用了MongoVUE进行数据库的可视化,所以我决定也对自己的数据库进行可视化。
小白学大数据
•
1年前
实用工具推荐:适用于 TypeScript 网络爬取的常用爬虫框架与库
随着互联网的迅猛发展,网络爬虫在信息收集、数据分析等领域扮演着重要角色。而在当前的技术环境下,使用TypeScript编写网络爬虫程序成为越来越流行的选择。TypeScript作为JavaScript的超集,通过类型检查和面向对象的特性,提高了代码的可维护
Python进阶者
•
1年前
这个网络爬虫代码,拿到数据之后如何存到csv文件中去?
大家好,我是皮皮。一、前言还是昨天的那个网络爬虫问题,那个粉丝说自己不熟悉pandas,用pandas做的爬虫,虽然简洁,但是自己不习惯,想要在他自己的代码基础上进行修改,获取数据的代码已经写好了,就差存储到csv中去了。他的原始代码如下:pythonim
小白学大数据
•
6个月前
应对反爬:使用Selenium模拟浏览器抓取12306动态旅游产品
在当今数据驱动的时代,网络爬虫已成为获取互联网信息的重要手段。然而,许多网站如12306都实施了严格的反爬虫机制,特别是对于动态加载的内容。本文将详细介绍如何使用Selenium模拟真实浏览器行为,有效绕过这些限制,成功抓取12306旅游产品数据。1230
小白学大数据
•
3个月前
构建稳定爬虫:为番茄小说爬虫添加IP代理与请求头伪装
一、引言:为何我们的爬虫会被“封杀”?当我们兴致勃勃地编写好一个爬虫脚本,初期运行顺畅,但很快便会遭遇403Forbidden、429TooManyRequests,甚至IP被直接封禁的窘境。这背后,是网站防御系统对我们发起的挑战:频率特征:同一IP在短时
1
•••
24
25
26
•••
294