推荐
专栏
教程
课程
飞鹅
本次共找到2932条
python爬虫
相关的信息
Wesley13
•
4年前
java爬虫进阶 —— ip池使用,iframe嵌套,异步访问破解
写之前稍微说一下我对爬与反爬关系的理解一、什么是爬虫 爬虫英文是splider,也就是蜘蛛的意思,web网络爬虫系统的功能是下载网页数据,进行所需数据的采集。主体也就是根据开始的超链接,下载解析目标页面,这时有两件事,一是把相关超链接继续往容器内添加,二是解析页面目标数据,不断循环,直到没有url解析为止。举个栗子:我现在要爬取苏宁手机价
Irene181
•
4年前
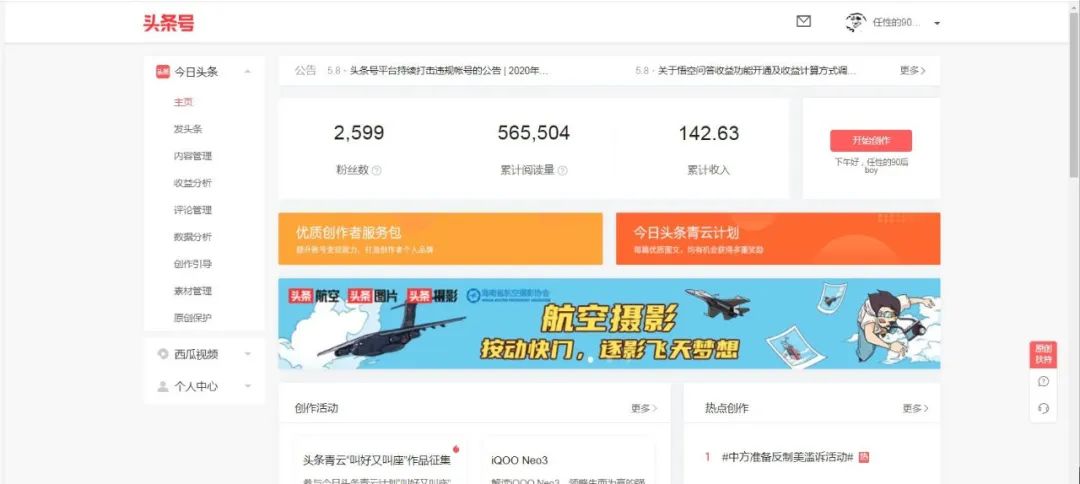
手把手教你用Python网络爬虫获取头条所有好友信息
前言大家好,我是黄伟。今日头条我发觉做的挺不错,啥都不好爬,出于好奇心的驱使,小编想获取到自己所有的头条好友,看似简单,那么情况确实是这样吗,下面我们来看下吧。项目目标获取所有头条好友昵称项目实践编辑器:sublimetext3浏览器:360浏览器,顺带一个头条号实验步骤1.登陆自己的头条号:可以看到2599,不知道谁会是下一个幸运观众了,
Irene181
•
4年前
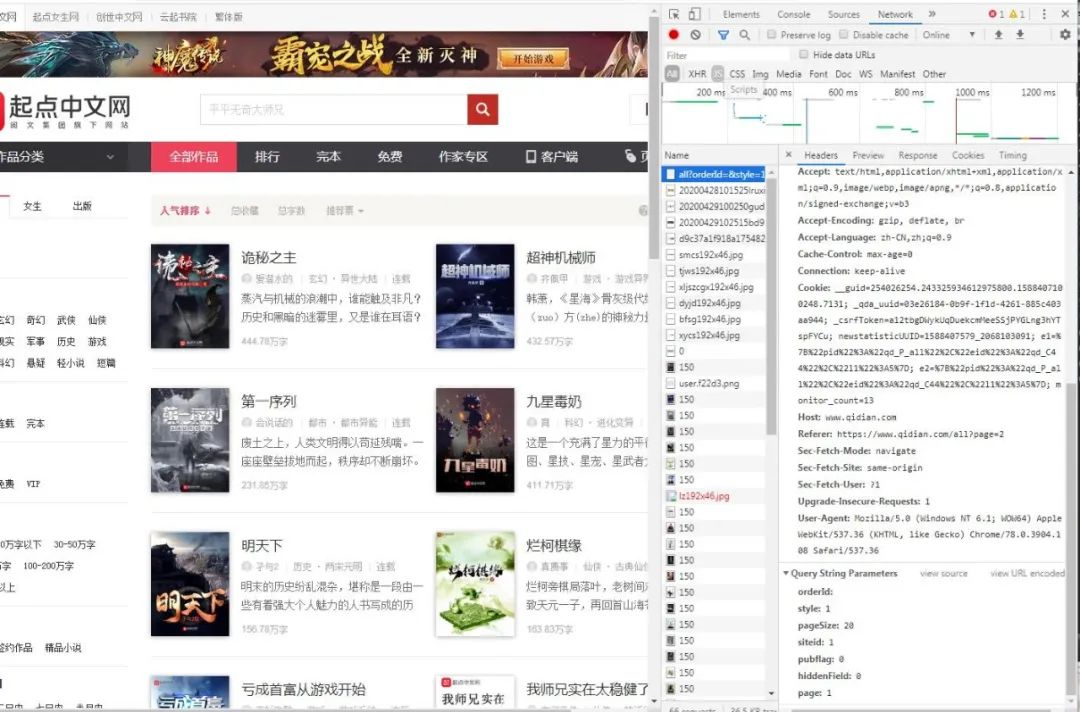
手把手教你用Python网络爬虫实现起点小说下载
今天要跟大家分享一个小说爬取案例起点小说的小说下载。在做这个案例之前,我们需要对其进行分析,1.界面分析,如图:通过分析很容易就找到了我们的get请求参数,然后获取相应页面的小说名和链接:获取到数据之后,我们就随机挑选一篇小说来进行下载,我们选第一篇,然后打开它的文章目录,可以看到是这样的,如图:基本上这篇小说很长,可以看到它卷一和卷二是免费的,后面的收费,
Aidan075
•
4年前
用python爬取4332条粽子数据进行分析,再送15盒粽子给大家
↑点击上方“凹凸数据” 关注星标 文章干货!有福利 ! 端午节快要到了,甜咸粽子之争也快要拉开帷幕。小五准备用Python爬取淘宝上的粽子数据并进行分析,看看有什么发现。(顺便送大家一波福利)爬虫爬取淘宝数据,本次采用的方法是:Selenium控制Chrome浏览器自动化操作\1\。其实我们还可以利用Ajax接口来构造链接,但是非常
九路
•
5年前
一个爬虫的故事:这是人干的事儿?
本文转载自轩辕之风的文章,链接https://mp.weixin.qq.com/s/YygbUWpa2mbPZPuPNhdt2w爬虫原理我是一个爬虫,每天穿行于互联网之上,爬取我需要的一切。image.png(https://imghelloworld.osscnbeijing.aliyuncs.com/imgs/656d
Stella981
•
4年前
Python爬虫从入门到放弃(十六)之 Scrapy框架中Item Pipeline用法
原文地址https://www.cnblogs.com/zhaof/p/7196197.html当Item在Spider中被收集之后,就会被传递到ItemPipeline中进行处理每个itempipeline组件是实现了简单的方法的python类,负责接收到item并通过它执行一些行为,同时也决定此Item是否继续通过pipeline,或者被丢
Stella981
•
4年前
GitHub:爬虫入门JS 模拟登陆各大网站
GitHub:爬虫入门JS模拟登陆各大网站hello,小伙伴们,大家好,今天给大家介绍的开源项目是:SpiderCrack_Js,想学习爬虫解密js登陆的可以看看这个开源项目,这个开源项目可以给你提供一个不错的思路。代码教程【OpenLaw】登陆参数加密
爬虫程序大魔王
•
3年前
什么是网络爬虫?
什么是网络爬虫网络爬虫是一种在Internet上运行自动化任务的软件应用程序。与人类互联网活动相比,网络爬虫运行的任务通常很简单,并且执行速度要快得多。有些机器人是合法的——例如,Googlebot是Google用来抓取互联网并将其编入索引以进行搜索的应用程序。其他机器人是恶意的——例如,用于自动扫描网站以查找软件漏洞并执行简单攻击模式的机器人。
京东云开发者
•
2年前
恶意爬虫防护 | 京东云技术团队
引言如果您仔细分析过任何一个网站的请求日志,您肯定会发现一些可疑的流量,那可能就是爬虫流量。根据Imperva发布的《2023ImpervaBadBotReport》在2022年的所有互联网流量中,47.4%是爬虫流量。与2021年的42.3%相比,增长了
1
•••
23
24
25
•••
294