推荐
专栏
教程
课程
飞鹅
本次共找到2932条
python爬虫
相关的信息
Python进阶者
•
3年前
Jsrpc学习——加密参数Sign变化的网站破解教程
大家好,我是皮皮。前几天给大家分享jsrpc的介绍篇,Python网络爬虫之js逆向之远程调用(rpc)免去抠代码补环境简介,还有实战篇,Jsrpc学习——网易云热评加密函数逆向,Jsrpc学习——Cookie变化的网站破解教程感兴趣的小伙伴可以戳此文前往。今天给大家来个jsrpc实战教程,让大家加深对jsrpc的理解和认识。下面是具体操作过程,不懂的小伙伴
Python进阶者
•
3年前
Jsrpc学习——Cookie变化的网站破解教程
大家好,我是皮皮。前几天给大家分享jsrpc的介绍篇,Python网络爬虫之js逆向之远程调用(rpc)免去抠代码补环境简介,感兴趣的小伙伴可以戳此文前往。今天给大家来个jsrpc实战教程,让大家加深对jsrpc的理解和认识。下面是具体操作过程,不懂的小伙伴可以私我。1、对Cookie进行hook,需要在浏览器的控制台输入命令Object.definePro
Wesley13
•
4年前
java爬虫入门
通用网络爬虫又称全网爬虫(ScalableWebCrawler),爬行对象从一些种子URL扩充到整个Web,主要为门户站点搜索引擎和大型Web服务提供商采集数据。今天我写的主要是一些皮毛入门现在来看下我们的pom依赖<projectxmlns"http://maven.apache.org/POM/4.0.0"xmln
Karen110
•
4年前
手把手教你用Python网络爬虫爬取新房数据
项目背景大家好,我是J哥。新房数据,对于房地产置业者来说是买房的重要参考依据,对于房地产开发商来说,也是分析竞争对手项目的绝佳途径,对于房地产代理来说,是踩盘前的重要准备。今天J哥以「惠民之家」为例,手把手教你利用Python将惠州市新房数据批量抓取下来,共采集到近千个楼盘,包含楼盘名称、销售价格、主力户型、开盘时间、容积率、绿化率等「41个字段」。数
陈占占
•
4年前
Python爬虫-爬取图片并且存储到MySQL数据库中
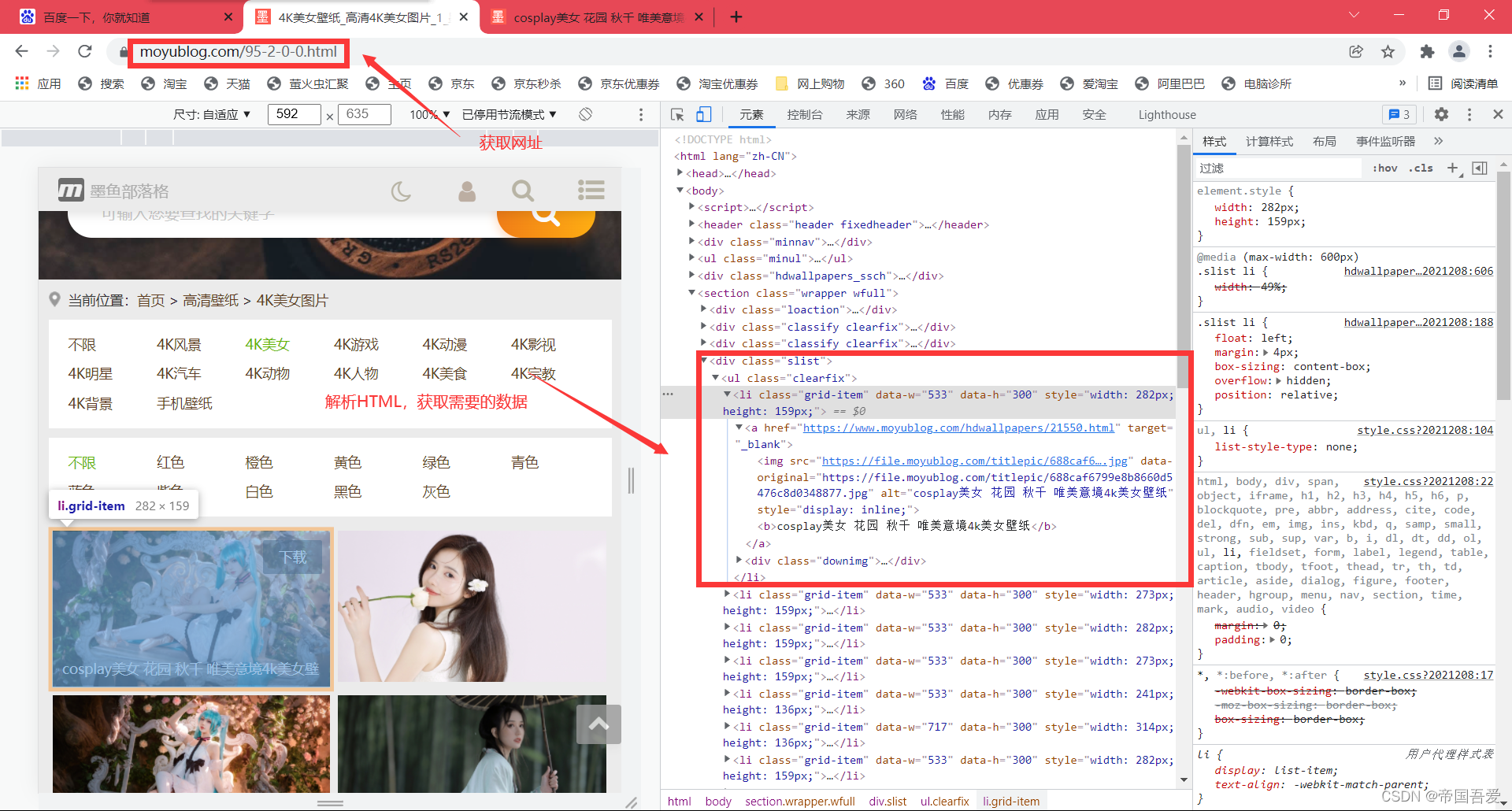
一、获取网址,解析网址(1)、for循环获取不同页的数据(2)、获取a标签中的网址(原因:外面图片分辨率太小,进入图片对应的网址寻找分辨率大点的图片)url网址https://www.moyublog.com/95200.htmlforiinrange(1):strvaluestr(i)页数url"htt
Stella981
•
4年前
Baidu音乐爬虫
Baidu音乐歌曲爬虫:1、分析Baidu音乐歌曲下载接口,组装参数2、判断是否需要登录 a、使用cookie b、使用selenium3、歌曲信息页面分析4、数据表设计歌曲类型表!(https://oscimg.oschina.net/oscnet/31721c4edb51fe06d2c5116a616f012d2e
爬虫程序大魔王
•
3年前
rogerbot 爬虫介绍
Rogerbot是MozProCampaign网站审核的Moz爬虫。它与Dotbot不同,Dotbot是为链接索引提供支持的网络爬虫。访问您网站的代码以将报告发送回您的MozProCampaign。这可以帮助您了解您的网站并教您如何解决可能影响您的排名的问题。Rogerbot为您的站点抓取报告、按需抓取、页面优化报告和页面评分器
小白学大数据
•
3年前
爬虫中使用代理IP的一些误区
做为爬虫工作者在日常工作中使用爬虫多次爬取同一网站时,经常会被网站的IP反爬虫机制给禁掉,为了解决封禁IP的问题通常会使用代理IP。但也有一部分人在HTTP代理IP的使用上存在着误解,他们认为使用了代理IP就能解决一切问题,然而实际上代理IP不是万
天翼云开发者社区
•
1年前
玩转云端 | 如何防爬虫?天翼云边缘安全加速平台AccessOne带你涨姿势!
玩转云端|如何防爬虫?天翼云边缘安全加速平台AccessOne带你涨姿势!
小白学大数据
•
8个月前
Python爬虫多线程并发时的503错误处理最佳实践
一、503错误产生的原因在HTTP协议中,503错误表示服务器当前无法处理请求,通常是因为服务器暂时过载或维护。在多线程爬虫场景下,503错误可能由以下几种原因引起:1.服务器负载过高:当多个线程同时向服务器发送请求时,服务器可能因负载过高而拒绝部分请求,
1
•••
22
23
24
•••
294