推荐
专栏
教程
课程
飞鹅
本次共找到2932条
python爬虫
相关的信息
Aidan075
•
4年前
厉害了,股票K线图还能这么画!
大家好,我是小五🐶发现大家还是最喜欢股票基金话题呀~那说到股票基金就不得不提——K线图!那小五今天就带大家👉用python来轻松绘制高颜值的K线图🚀获取股票交易数据巧妇难为无米之炊,做可视化也离不开数据。本文我将以酱香型科技——贵州茅台为例,获取它的近期股票数据并绘制K线图。如果我们要特意去动手去写爬虫,就显得有些多余了,这里
Aidan075
•
4年前
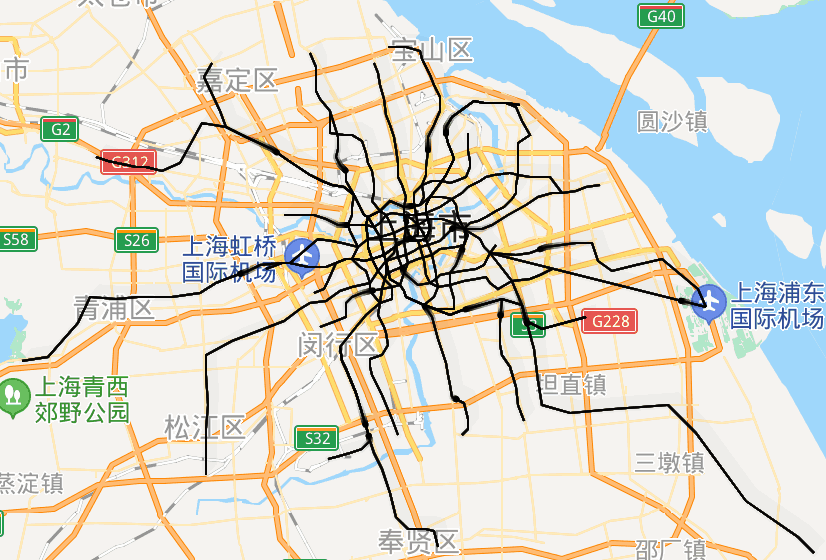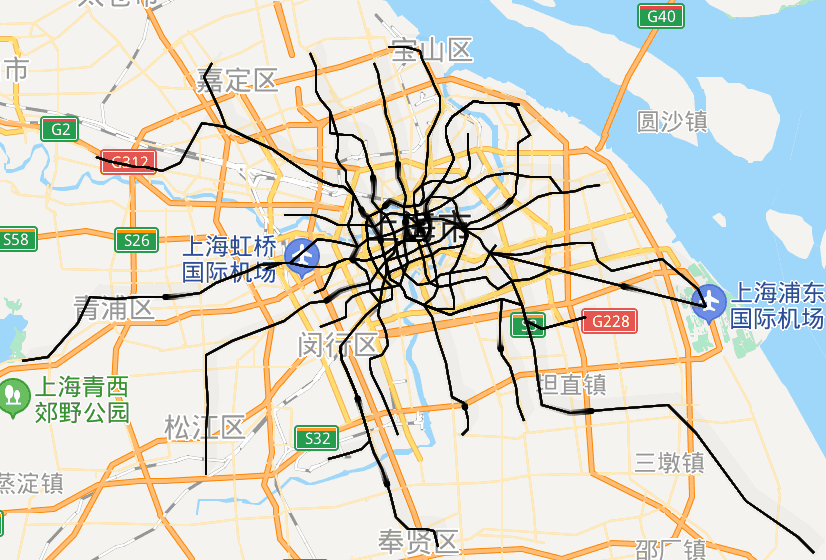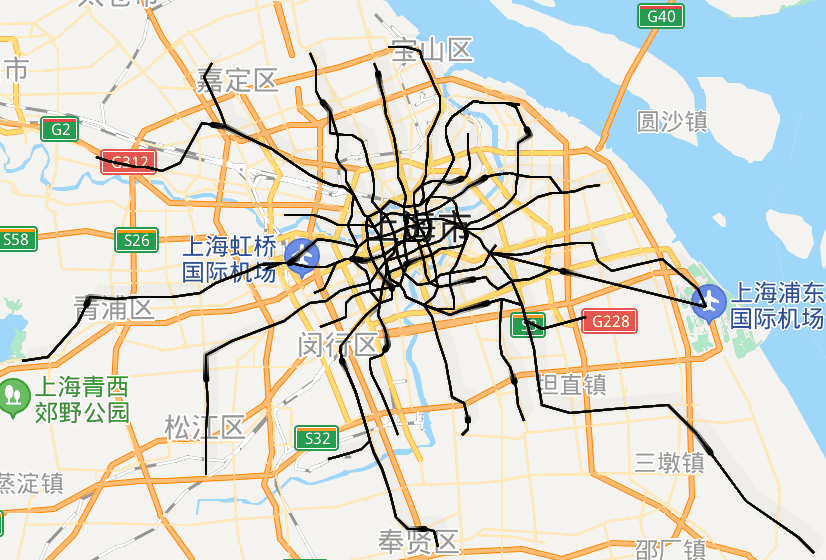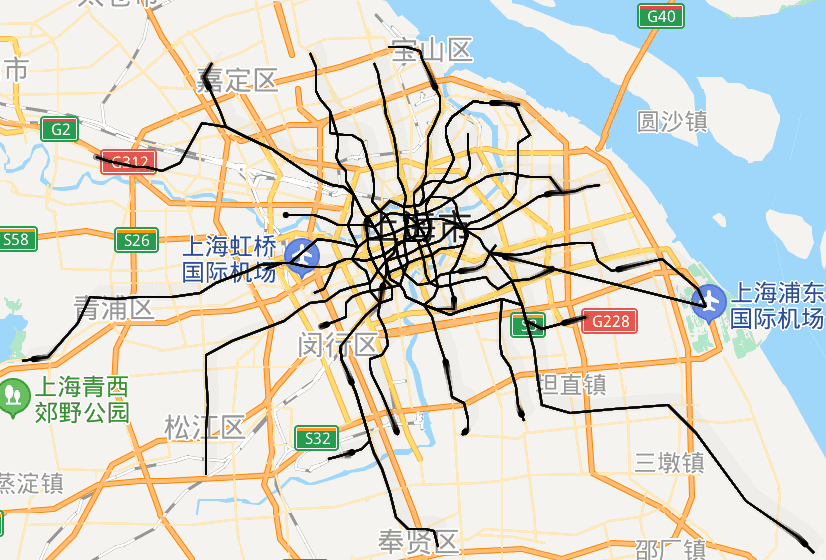
太酷炫了!我用Python画出了北上广深的地铁路线动态图
大家好,我是小五🐶今天教大家用python制作地铁线路动态图,这可能是全网最全最详细的教程了。坐标点的采集小五之前做过类似的地理可视化,不过都是使用网络上收集到的json数据。但很多数据其实是过时的,甚至是错误/不全的。所以我们最好还是要自己动手,丰衣足食(爬虫大法好)。打开高德地图的地铁网页,http://map.amap.com/subway/ind
黎明之道
•
5年前
python爬虫之数据提取Xpath(爬取起点中文网案例)
(https://blog.csdn.net/sjjsaaaa/article/details/111293732)Xpath详细的Xpath介绍手册——https://www.w3school.com.cn/xpa
Karen110
•
4年前
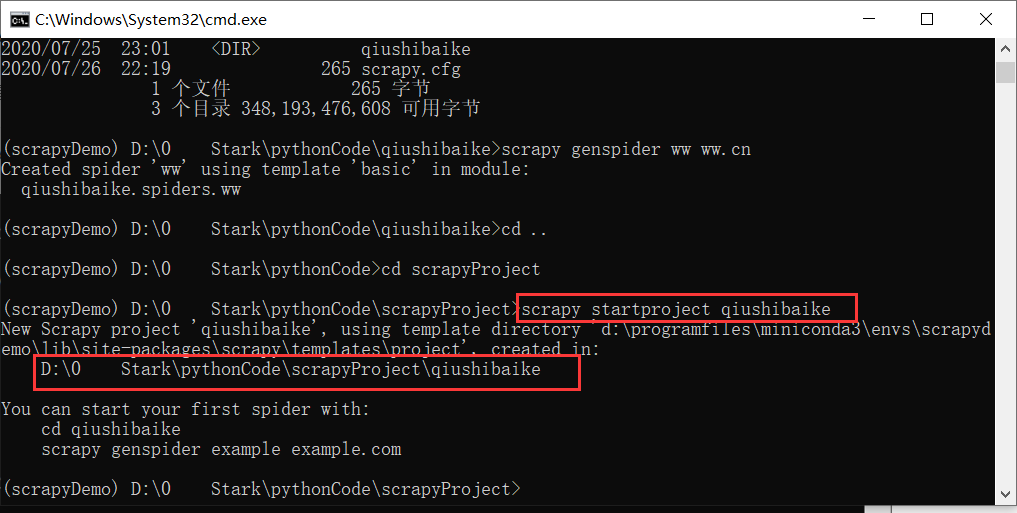
使用Scrapy网络爬虫框架小试牛刀
前言这次咱们来玩一个在Python中很牛叉的爬虫框架——Scrapy。scrapy介绍标准介绍Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架,非常出名,非常强悍。所谓的框架就是一个已经被集成了各种功能(高性能异步下载,队列,分布式,解析,持久化等)的具有很强通用性的项目模板。对于框架的学习,重点是要学习其框架的特性、各个功能的
Python进阶者
•
3年前
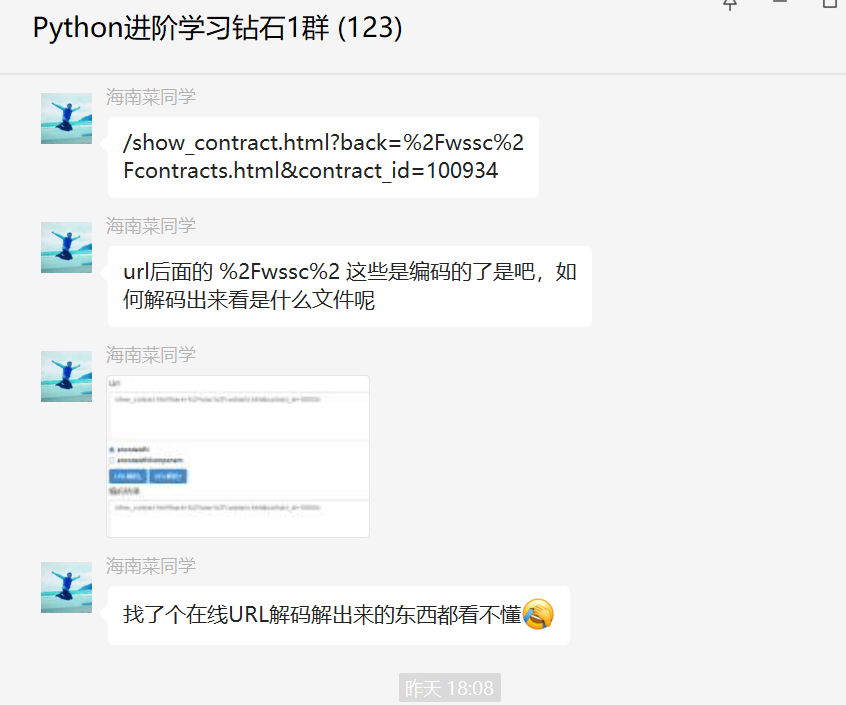
分享Python网络爬虫过程中编码和解码的一个库
大家好,我是皮皮。一、前言前几天在Python白银钻石群【海南菜同学】问了一个Python编码的问题,提问截图如下:原始代码如下:/showcontract.html?back%2Fwssc%2Fcontracts.html&contractid100934编码截图如下图所示:二、实现过程一开始以为不是编码,后来【此类生物】直接看出来了,太强了。其实关于
Python进阶者
•
4年前
数据提取之JSON与JsonPATH
大家好,我是Python进阶者。背景介绍我们知道再爬虫的过程中我们对于爬取到的网页数据需要进行解析,因为大多数数据是不需要的,所以我们需要进行数据解析,常用的数据解析方式有正则表达式,xpath,bs4,这次我们来介绍一下另一个数据解析库jsonpath,在此之前我们需要先了解一下什么是json。一、初识JsonJSON(JavaScriptObjec
小白学大数据
•
3年前
python爬取数据的关键技术
大数据时代,数据越来越具有价值了,没有数据寸步难行,有了数据好好利用,可以在诸多领域干很多事。从互联网上爬来自己想要的数据,是数据的一个重要来源,所以,爬虫工程师现在是一个非常吃香的职位,这个职业能带来稳定的、高效的和实时的数据。爬虫可以很快的入门,但要做的真正大神,还必须不断实践。因为,一旦真正爬数据的时候就会出现各种问题,因为爬虫本质是一种对抗性的工作,
小白学大数据
•
2年前
Request 爬虫的 SSL 连接问题深度解析
SSL连接简介SSL(SecureSocketsLayer)是一种用于确保网络通信安全性的加密协议,广泛应用于互联网上的数据传输。在数据爬取过程中,爬虫需要与使用HTTPS协议的网站进行通信,这就牵涉到了SSL连接。本文将深入研究Request爬虫中的SS
Python进阶者
•
1年前
手把手教你使用Python网络爬虫下载一本小说(附源码)
大家好,我是Python进阶者。前言前几天【磐奚鸟】大佬在群里分享了一个抓取小说的代码,感觉还是蛮不错的,这里分享给大家学习。一、小说下载如果你想下载该网站上的任意一本小说的话,直接点击链接进去,如下图所示。只要将URL中的这个数字拿到就可以了,比方说这里
小白学大数据
•
3年前
安居客房源信息获取
最近身边有几个做房产销售的朋友经常在诉苦,找不到客户,没有业绩,所以就比较好奇他们现在的行情,所以今天我们就使用python获取下安居客的一些房源数据。之前分享过很多关于爬虫的实践示例,今天这个也算是实践内容。我们就以户型结构、装修情况、水肥情况进行房源数据获取。爬取数据的通用流程:1、根据url请求页面,获取页面响应对象2、将页面响应对象转化为对象3、定
1
•••
25
26
27
•••
294