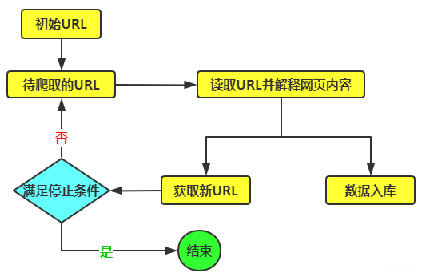
大数据时代,数据越来越具有价值了,没有数据寸步难行,有了数据好好利用,可以在诸多领域干很多事。从互联网上爬来自己想要的数据,是数据的一个重要来源,所以,爬虫工程师现在是一个非常吃香的职位,这个职业能带来稳定的、高效的和实时的数据。 爬虫可以很快的入门,但要做的真正大神,还必须不断实践。因为,一旦真正爬数据的时候就会出现各种问题,因为爬虫本质是一种对抗性的工作,你需要和反爬人员斗智斗勇。不过,这个过程会充满无穷的乐趣,还会把你锤炼成真正的爬虫高手。 今天我们就以知乎为例简单分析下爬虫入门的一些基本知识。之所以选择知乎是因为因为这例子可以尽量多的将爬虫涉及的技术点包含进去,同时又不至于那么复杂,方便入门。接下来就是爬取知乎会涉及到的一些主要技术点。1、模拟登陆,要爬取知乎这样需要登录的网站数据,模拟登录是必不可少的一步,而且往往是难点。2、数据的获取和解析,获取数据原本很简单,但是很多网站做了反爬措施所以就加大了获取的难度,像知乎对IP的限制就很严,这样的情况下我们要获取数据就需要加上代理IP。代理的使用是比较简单的,比如用jav写的爬虫,那添加代理IP的方式如下: import org.apache.commons.httpclient.Credentials; import org.apache.commons.httpclient.HostConfiguration; import org.apache.commons.httpclient.HttpClient; import org.apache.commons.httpclient.HttpMethod; import org.apache.commons.httpclient.HttpStatus; import org.apache.commons.httpclient.UsernamePasswordCredentials; import org.apache.commons.httpclient.auth.AuthScope; import org.apache.commons.httpclient.methods.GetMethod;
import java.io.IOException;
public class Main { # 代理服务器(产品官网 www.16yun.cn) private static final String PROXY_HOST = "t.16yun.cn"; private static final int PROXY_PORT = 31111;
public static void main(String[] args) {
HttpClient client = new HttpClient();
HttpMethod method = new GetMethod("https://httpbin.org/ip");
HostConfiguration config = client.getHostConfiguration();
config.setProxy(PROXY_HOST, PROXY_PORT);
client.getParams().setAuthenticationPreemptive(true);
String username = "16ABCCKJ";
String password = "712323";
Credentials credentials = new UsernamePasswordCredentials(username, password);
AuthScope authScope = new AuthScope(PROXY_HOST, PROXY_PORT);
client.getState().setProxyCredentials(authScope, credentials);
try {
client.executeMethod(method);
if (method.getStatusCode() == HttpStatus.SC_OK) {
String response = method.getResponseBodyAsString();
System.out.println("Response = " + response);
}
} catch (IOException e) {
e.printStackTrace();
} finally {
method.releaseConnection();
}
}} 爬虫代理的选择本不是很难的事,但是奈何网上太多的宣传广告和实际使用效果不符的,所以也是让很多爬虫小伙伴有了无从选择的烦恼,这里给大家推荐亿牛云代理,小编之前的公司一直都有在使用,身边很多的爬虫朋友也有在使用并且反馈都很好。还有一些关键的爬虫技术我们下次在详细分享给的大家学习参考。