爬虫
什么是爬虫 使用编程语言所编写的一个用于爬取web或app数据的应用程序 怎么爬取数据 1.找到要爬取的目标网站、发起请求 2.分析URL是如何变化的和提取有用的URL 3.提取有用的数据 爬虫数据能随便爬取吗? 遵守robots.txt协议
爬虫的分类
通用网络爬虫 百度,Google等搜索引擎,从一些初识的URL扩展到整个网站,主要为门户站点搜索引擎和大型网站服务采集数据 聚焦网络爬虫 又称主题网络爬虫,选择性地爬行根据需求的主题相关页面的网络爬虫 增量式网络爬虫 对已下载网页采取增量式更新知识和只爬行新产生或者已经发生变化的网页爬虫 深层网络爬虫 大部分内容不能通过静态的URL获取、隐藏在搜索表单后的、只有用户提交一些关键词才能获得的网络页面
网络爬虫原理
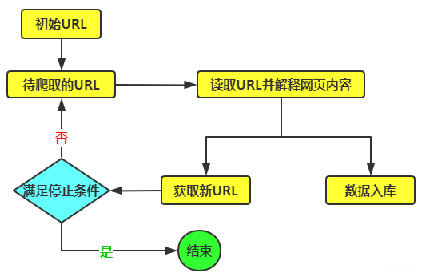
通用网络爬虫原理
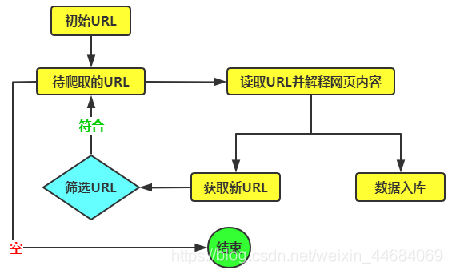
 聚焦网络爬虫原理
聚焦网络爬虫原理
HTTP与HTTPS
HTTP协议
全称是HyperText Transfer Protocal ,中文意思是超文本传输协议,是一种发布和接收HTML(HyperText Markuup Language)页面的方法。服务器端口号为80端口
HTTPS 协议
(全称:Hyper Text Transfer Protocol over SecureSocket Layer) ,是HTTP协议的加密版本,在HTTP下加入了SSL层,服务器端口号是443
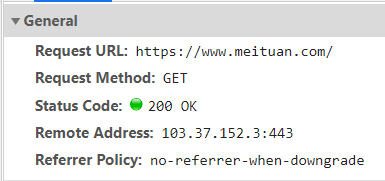
URL与URI
URL(网址)是Uriform Resource Locator的简写,统一资源定位符。
一个URL由以下几部分组成
1)协议的类型
2)主机名称/域名
3)端口号
4)查找路径
5)查询参数
6)锚点,前端用来做面定位的。现在一些前后端分离项目,也用锚点来做导航
前端定位 https://baike.baidu.com/item/%E5%88%98%E8%8B%A5%E8%8B%B1#2
锚点导航 动的是#之后的内容 ,根据锚点去请求数据 https://music.163.com/#/friend
URI:统一资源标识符 Uniform Resource Identifier ,是一个用于标识某一互联网资源名称的字符串
常见的请求方式
http协议规定了 浏览器与服务器进行数据交互的过程中必须要选择一种交互的方式
在HTTP协议中,定义了八种请求方式。常见的有get请求与post请求
get请求:一般情况下,只从服务器获取数据下来,并不会对服务器资源产生任何影响的时候会使用get请求
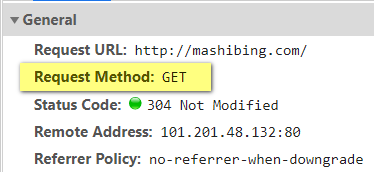
常见的请求方式
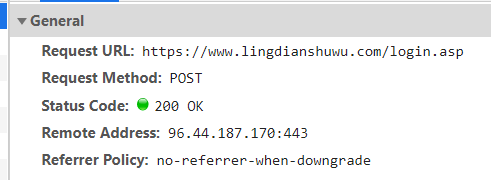
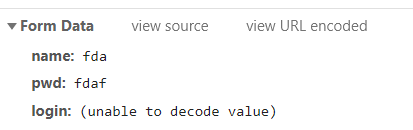
post请求:向服务器发送数据(登录)、上传文件等,会对服务器资源产生影响的时候会使用Post请求。 请求参数在form data中 get与post的区别 Get是不安全的,因为在传输过程,数据被放在请求的URL中;Post的所有操作对用户来说都是不可见的。 Get传送的数据量较小,这主要是因为受URL长度限制,不能大于2kb;Post传送的数据量较大,一般被默认为不受限制。 Get限制Form表单的数据集的值必须为ASCII字符;而Post支持整个ISO10646字符集。 Get执行效率却比Post方法好。Get是form提交的默认方法。
 )
)
常见的请求头参数
http协议中,向服务器发送一个请求,数据分为三部分 第一个是把数据放在url中 第二个是把数据放在body中(post请求时) 第三个就是把数据放在head中
常见的请求头参数 user-agent:浏览器名称 referer:表明当前这个请求是从哪个url过来的 cookie:http协议是无状态的。也就是同一个人发送了两次请求。服务器没有能力知道这两个请求是否来自同一个人。
常见的响应状态码
常见的响应状态码 200: 请求正常,服务器正常的返回数据 301:永久重定向。比如访问http://www.360buy.com的时候会重定向到www.jd.com http://www.jingdong.com。。。。。。。www.jd.com 404:请求的url在服务器上找不到,换句话说就是请求的url错误. https://www.jianshu.com/fd 418:发送请求遇到服务器端反爬虫,服务器拒绝响应数据 500:服务器内部错误,可能是服务器出现了bug
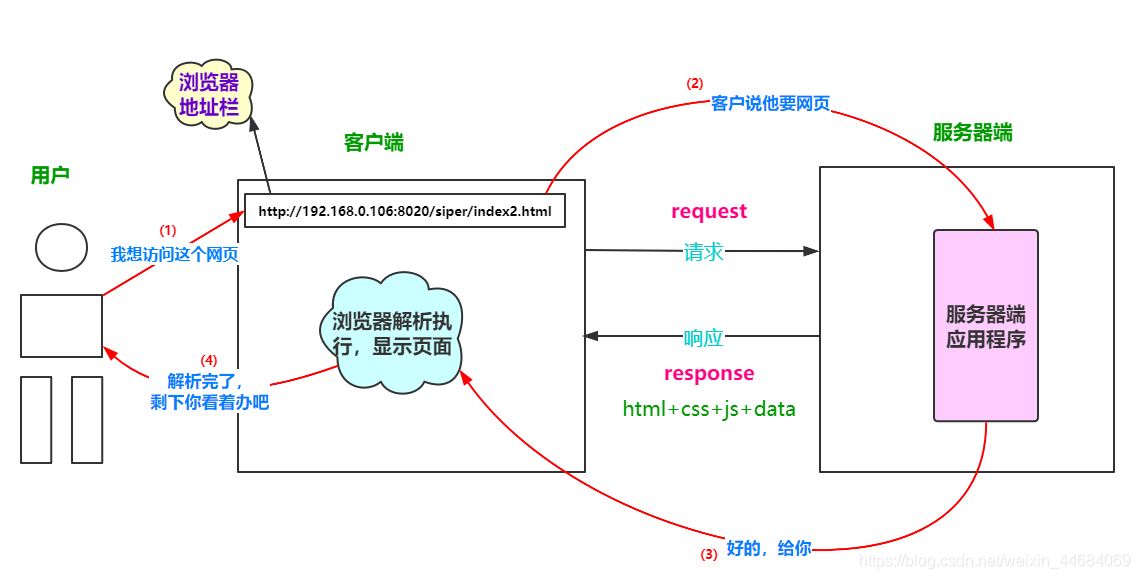
HTTP请求的交互过程
(1)客户端浏览器向网站所在的服务器发送一个请求
(2)网站服务器接收到这个请求后进行解析、处理,然后返回响应对应的数据给浏览器
(3)浏览器中包含网页的源代码等内容(存在浏览器的缓存中),浏览器再对其进行解析,最终将结果呈现给用户
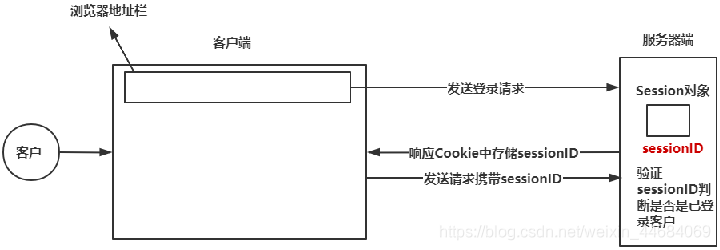
Session与Cookie
Session代表服务器与浏览器的一次会话过程。
Session是一种服务器端的机制,Session对象用来存储特定用户会话所需的信息。
Session由服务器端生成,保存在服务器的内存、缓存、硬盘或数据库中。
Session的基本原理
 Cookie是由服务端生成后发送给客户端(通常是浏览),Cookie总是保存在客户端
Cookie的基本原理
(1)创建Cookie
(2)设置存储Cookie
(3)发送Cookie
(4)读取Cookie
Cookie是由服务端生成后发送给客户端(通常是浏览),Cookie总是保存在客户端
Cookie的基本原理
(1)创建Cookie
(2)设置存储Cookie
(3)发送Cookie
(4)读取Cookie
JSON
JavaScript ObjectNotation,JS对象标记)是一种轻量级的数据交互格式,采用完全独立于编程语言的文本格式来存储和表示数据。 简洁和清晰的层次结构使得JSON成为理想的数据交换语言,易于阅读和编写,同时也易于机器解析和生成,并有效地提升网络传输效率。 JSON的数据格式 (1)对象表示为键值对 (2)数据由逗号分隔 (3)花括号保存对象 (4)方括号保存数组 在数据结构上,JSON与Python里的字典非常相似
Ajax
Ajax在浏览器与Web服务器之间使用异步数据传输。这样就可以使网页从服务器请求少量的信息,而不是整个页面。
Ajax技术独立于浏览器和平台。
Ajax一般返回的是JSON,直接对Ajax地址进行Post或get,就返回JSON数据了
urllib简介
urllib是Python自带的标准库中用于网络请求的库 ,无需安装,直接引用即可 通常用于爬虫开发、API(应用程序编程接口)数据获取和测试 urllib库的4大模块 urllib.request :用于打开和读取URL urllib.error:包含提出的例外(异常)urllib.request urllib.parse:用于解析URL(地址栏不让使用中文,所以搜索内容在url中以编码显示,此时就需要解析编码) urllib.robotparser:用于解析robots.txt文件
解析url
# 导入包用于url解析
import urllib.parse
kw = {'wd':'小张'}
# 编码
result = urllib.parse.urlencode(kw)
# 输出编码
print(result)
# 解码
res = urllib.parse.unquote(result)
print(res)发送请求
urllib.request库 模拟浏览器发起一个HTTP请求,并获取请求响应结果 urllib.request.urlopen的语法格式 urlopen(url, data=None, [timeout,], cafile=None, capath=None, cadefault=False, context=None) *参数说明** url:url参数是str类型的地址,也就是要访问的URL,例如:https://www.baidu.com data:默认值为None,urllib判断参数data是否为None从而区分请求方式。或参数data为None,则代表请求方式为Get,反之请求方式为Post,发送Post请求。参数data以字典形式存储数据,并将参数data由字典类型转换成字节类型才能完成Post请求 urlopen函数返回的结果是一个http.client.HTTPResponse对象
import urllib.request
url = 'https://www.douban.com/'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.114 Safari/537.36 Edg/91.0.864.59',
}
# 添加请求头操作
request = urllib.request.Request(url, headers=headers)
resp = urllib.request.urlopen(request)
html = resp.read().decode('UTF-8') # decode将byte类型转换成str类型
print(html)decode后面内容根据网站代码决定
post请求
import urllib.request
import urllib.parse
url = 'https://www.douban.com/'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/91.0.4472.114 Safari/537.36 Edg/91.0.864.59',
}
date = {'name': '13915796826', 'password': 'zhanghao1333'}
# 发送请求
request = urllib.request.Request(url, data=bytes(urllib.parse.urlencode(date), encoding='utf-8'),headers=headers)
resp = urllib.request.urlopen(request)
html = resp.read().decode('utf-8')
print(html)
IP代理
为什么需要使用IP代理 假如一个网站它会检测某一段时间某个IP的访问次数,如果访问次数过多,它会禁止你的访问。所以你可以设置一些代理服务器来帮助你做工作,每隔一段时间换一个代理。
IP代理的分类
透明代理:目标网站知道你使用了代理并且知道你的源IP地址,这种代理显然不符合我们这里使用代理的初衷 匿名代理:匿名程序比较低,也就是网站知道你使用了代理,但是并不知道你的源IP地址 高匿代理:这是最保险的方式,目录网站既不知道你使用了代理更不知道你的源IP IP代理的方式 免费 20、http://www.nimadaili.com/ 泥马IP代理
19、http://lab.crossincode.com/proxy/ Crossin编程教室
18、http://www.xsdaili.com/dayProxy/ip/1415.html 小舒代理
17、http://www.xiladaili.com/ 西拉免费代理IP
16、http://ip.jiangxianli.com/ 免费代理IP库
15、http://www.superfastip.com/ 极速代理
14、http://ip.kxdaili.com/ 开心代理
13、https://proxy.mimvp.com/free.php 米扑代理
12、http://www.shenjidaili.com/open/ 神鸡代理IP
11、http://31f.cn/http-proxy/ 三一代理
10、http://www.feiyiproxy.com/?page_id=1457 飞蚁代理
9、http://ip.zdaye.com/dayProxy/2019/4/1.html 站大爷
8、http://www.66ip.cn 66免费代理网
7、https://www.kuaidaili.com/free/inha 快代理
6、https://www.xicidaili.com 西刺
5、http://www.ip3366.net/free/?stype=1 云代理
4、http://www.iphai.com/free/ng IP海
3、http://www.goubanjia.com/ 全网代理
2、http://www.89ip.cn/index.html 89免费代理
1、http://www.qydaili.com/free/?action=china&page=3 旗云代理
from urllib.request import build_opener
from urllib.request import ProxyHandler
poxy = ProxyHandler({'http':'193.150.117.102:8000'})
opener = build_opener(poxy)
url = 'https://www.douban.com/'
resp = opener.open(url)
print(resp.read().decode('utf-8'))使用Cookie
为什么需要使用Cookie 解决http的无状态性
使用步骤 实例化MozillaCookieJar (保存cookie) 创建 handler对象(cookie的处理器) 创建opener对象 打开网页(发送请求获取响应) 保存cookie文件
案例:获取百度贴吧的Cookie并保存到文件中https://tieba.baidu.com/index.html?traceid=#
from http import cookiejar
import urllib.request
filename = 'cookie.txt'
# 获取cookie
def get_cookie():
# (1)实例化一个MozillaCookieJar(用于保存cookie)
cookie = cookiejar.MozillaCookieJar(filename)
# (2)创建hander对象
hander = urllib.request.HTTPCookieProcessor(cookie)
# (3)创建opener对象
opener = urllib.request.build_opener(hander)
# (4)请求网址
url = 'https://tieba.baidu.com/index.html?traceid=# '
resp = opener.open(url)
# (5)存储cookie文件
cookie.save()
# 读取cookie
def use_cookie():
# 实例化MozillaCookieJar
cookie = cookiejar.MozillaCookieJar()
# 加载cookie文件
cookie.load(filename)
print(cookie)
if __name__ == '__main__':
# get_cookie()
use_cookie()
错误解析
异常处理主要用到两大类 urllib.error.URLError :用于捕获由urllib.request产生的异常,使用reason属性返回错误原因
urllib.error.HTTPError :用于处理HTTP与HTTPS请求的错误,它有三个属性 code:请求返回的状态码 reason:返回错误的原因 headers:请求返回的响应头信息
import urllib.request
import urllib.error
url = 'http://www.google.com' # 错误的url
# 捕获异常
try:
resp = urllib.request.urlopen(url)
except urllib.error.URLError as e:
print(e.reason)import urllib.request
import urllib.error
url = 'https://movie.douban.com'
try:
resp = urllib.request.urlopen(url)
except urllib.error.HTTPError as e:
print('原因', e.reason)
print('响应状态码', e.code)
print('响应头数据', e.headers)
requests库
Requests 是Python一个很实用的HTTP客户端,完全满足如今网络爬虫的需求
requests库的安装
pip命令安装
windows操作系统:pip install requests
Mac 操作系统: pip3 install requests
Linux操作系统; sudo pip install requests
源码安装
下源requests源码http://mirrors.aliyun.com/pypi/simple/requests/
下载文件到本地之后,解压到Python安装目录,之后打开解压文
运行命令行输入 python setup.py install 即可安装
若出现You are using pip version 21.0.1; however, version 21.1.3 is available.
You should consider upgrading via the 'c:\users\dell\appdata\local\programs\python\python39\python.exe -m pip install --upgrade pip' command.
则使用该命令行python -m pip install --upgrade pip
然后检查版本是否升级
pip3 --versionrequests库
requests库常用的方法
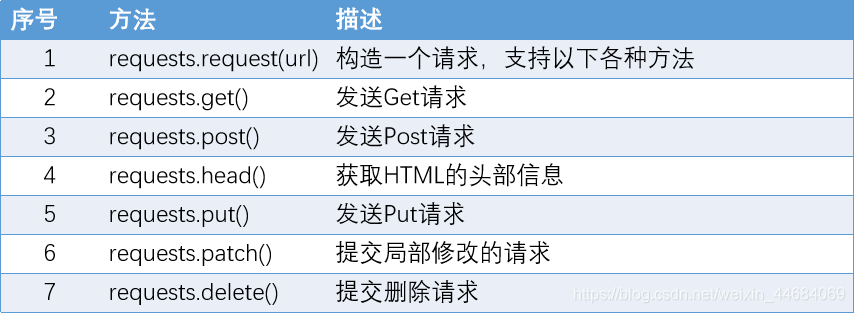 )最常用的方法为get()和post()分别用于发送Get请求和Post请求
requests库的使用
语法结构:
requests.get(url, params=None)
参数说明:
url:需要爬取的网站的网址
params:请求参数
该方法的结果为Response对象,包含服务器的响应信息
)最常用的方法为get()和post()分别用于发送Get请求和Post请求
requests库的使用
语法结构:
requests.get(url, params=None)
参数说明:
url:需要爬取的网站的网址
params:请求参数
该方法的结果为Response对象,包含服务器的响应信息
import requests
# 不带参数的get请求
url = 'http://www.baidu.com'
resp = requests.get(url)
# 设置响应的经编码格式
resp.encoding = 'utf-8'
cookie = resp.cookies # 获取请求后的cookie信息
headers = resp.headers
print('响应状态码:', resp.status_code)
print('请求后的cookie:', cookie)
print('获取请求的网址:', resp.url)
print('响应头:', headers)
print('响应内容:', resp.text)获取JSON数据
json的url获取地点如下图,需要刷新后可见
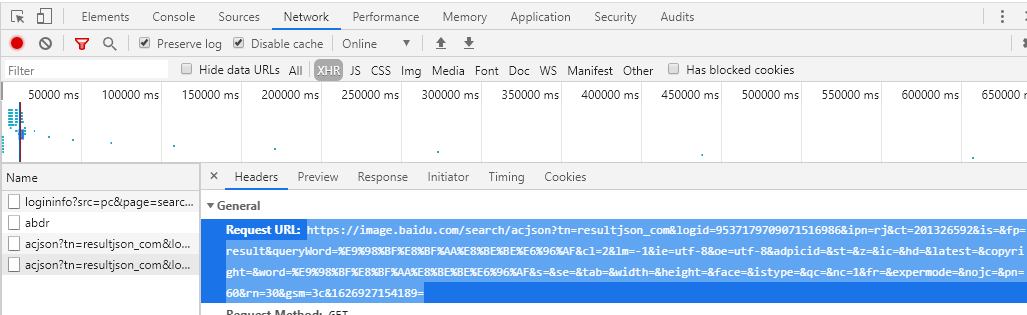
import requests
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/91.0.4472.114 Safari/537.36 Edg/91.0.864.59',
}
url = 'https://image.baidu.com/search/acjson?tn=resultjson_com&logid=9537179709071516986&ipn=rj&ct=201326592&is=&fp=result&queryWord=%E9%98%BF%E8%BF%AA%E8%BE%BE%E6%96%AF&cl=2&lm=-1&ie=utf-8&oe=utf-8&adpicid=&st=&z=&ic=&hd=&latest=©right=&word=%E9%98%BF%E8%BF%AA%E8%BE%BE%E6%96%AF&s=&se=&tab=&width=&height=&face=&istype=&qc=&nc=1&fr=&expermode=&nojc=&pn=60&rn=30&gsm=3c&1626927154189='
resp = requests.get(url, headers=headers)
json_data = resp.json()
print(json_data)获取二进制数据
获取并下载百度logo
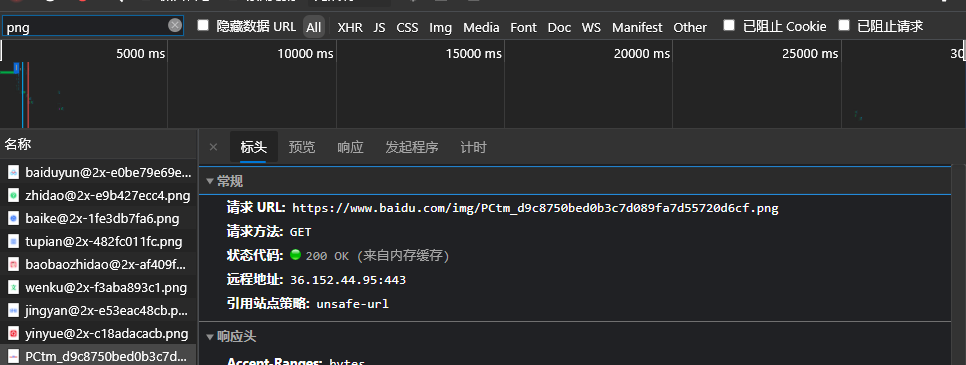
import requests
url = 'https://www.baidu.com/img/flexible/logo/pc/result.png'
resp = requests.get(url)
# 存储
with open('C:\\Users\\Dell\\Desktop\\login.png','wb') as file:
file.write(resp.content)request库
用python程序登录豆瓣网站
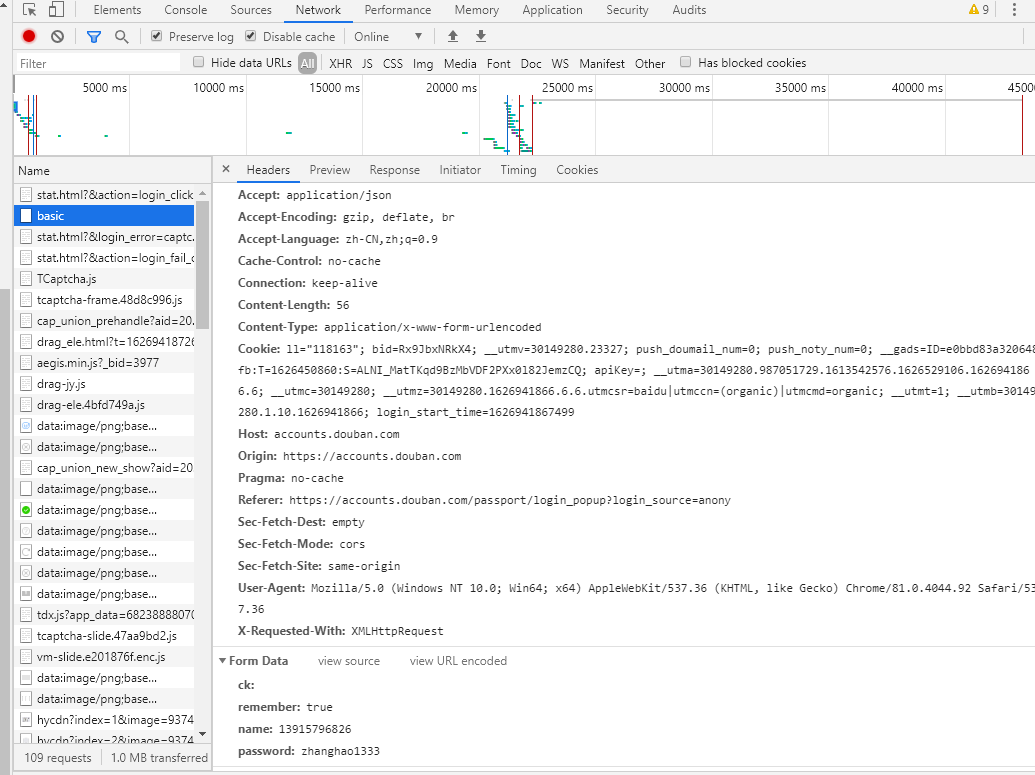
import requests
url = 'https://accounts.douban.com/j/mobile/login/basic'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/91.0.4472.114 Safari/537.36 Edg/91.0.864.59',
}
data = {'name': '13915796826', 'password': 'zhanghao1333'}
resp = requests.post(url, data=data, headers=headers)
resp.encoding = 'gbk'
print(resp.status_code)
print(resp.text)session发请求
获取session对象:requests.session() session对象.post() 发送post请求,可以记录当前状态
数据解析
1、XPath解析数据 2、BeautifulSoup解析数据 3、正则表达式 4、pyquery解析数据
XPath解析数据
XPath
全称: XML Path Language是一种小型的查询语言
是一门在XML文档中查找信息的语言
XPath的优点
可在XML中查找信息
支持HTML的查找
可通过元素和属性进行导航
Xpath需要依赖lxml库
安装方式 : pip install lxml
XPath详解
XPath插件下载地址
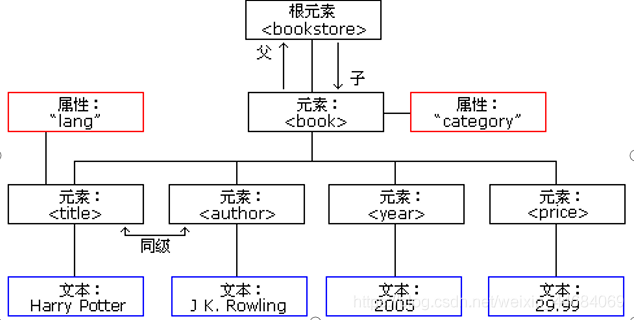
XML的树形结构
第一行为xml文档介绍,一个xml文档只允许有一个根元素
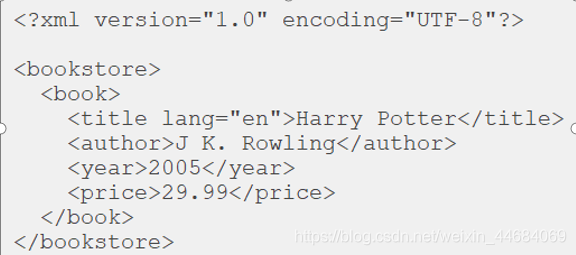
使用XPath选取节点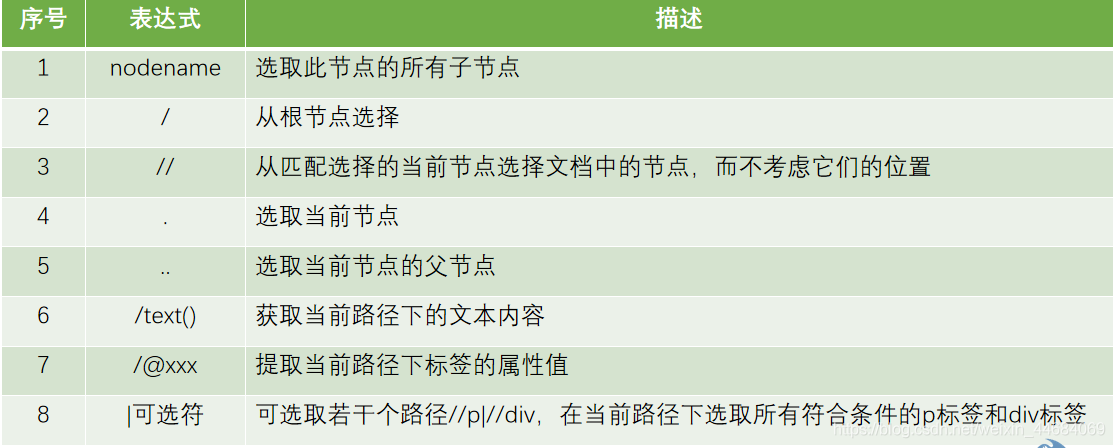
举例,获取起点小说网图书名称以及作者
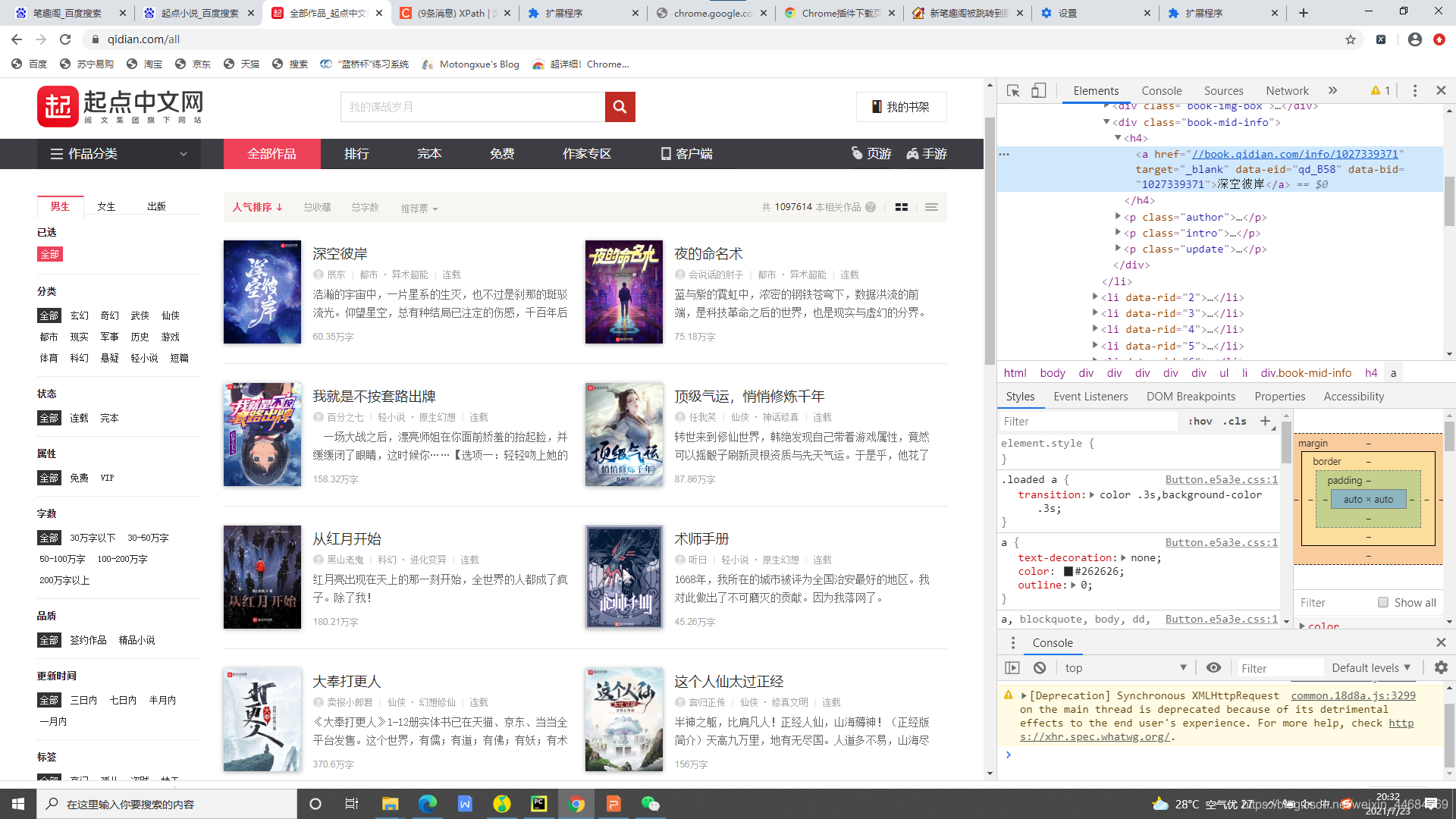 首先找到小说名所在的div,图中蓝色标注
然后打开XPath插件,如下图
首先找到小说名所在的div,图中蓝色标注
然后打开XPath插件,如下图
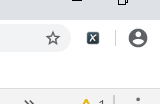 然后输入如下代码
然后输入如下代码
//div[@class="book-mid-info"]/h4/a/text() 获取小说作者同样方法
下面是使用python代码实现
获取小说作者同样方法
下面是使用python代码实现
import requests
from lxml import etree
url = 'https://www.qidian.com/all'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/91.0.4472.114 Safari/537.36 Edg/91.0.864.59',
}
# 发送请求
resp = requests.get(url, headers=headers)
# 响应文本类型转化为etree类型
e = etree.HTML(resp.text)
book_name = e.xpath('//div[@class="book-mid-info"]/h4/a/text()')
book_author = e.xpath('//p[@class = "author"]/a[1]/text()')
for book_name, book_author in zip(book_name, book_author):
print(book_name + ':' + book_author)
输出如下

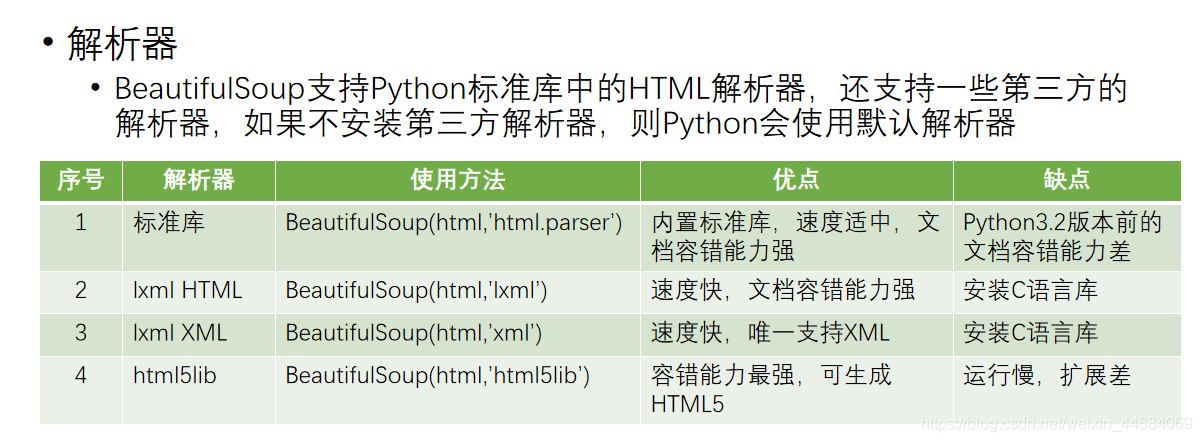
BeautifulSoup解析数据
BeautifulSoup
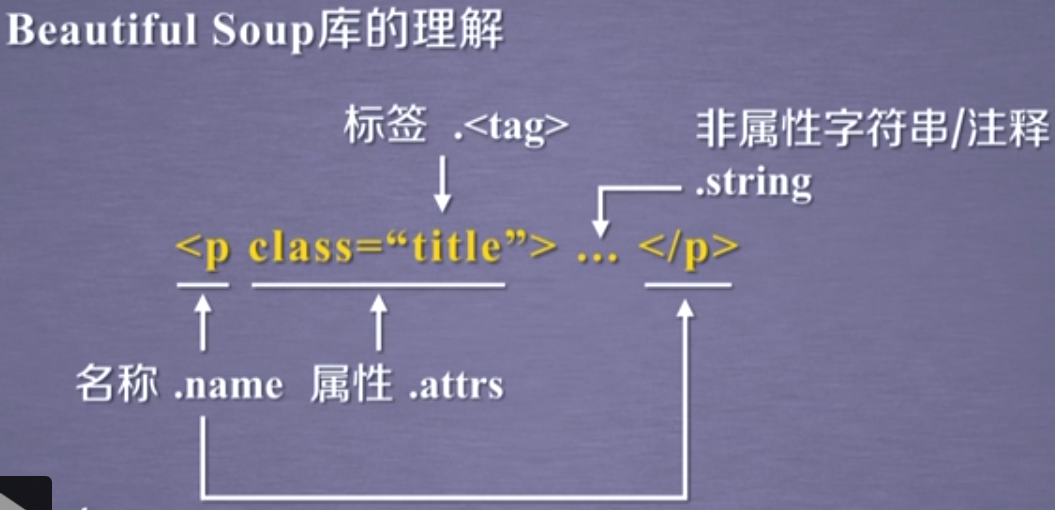
是一个可以从HTML或XML文件中提取数据的Python库。其功能简单而强大、容错能力高、文档相对完善,清晰易懂
非Python标准模块,需要安装才能使用
安装方式
pip install bs4
测试方式
import bs4
from bs4 import BeautifulSoup
html = '''
<html>
<head>
<title>马士兵教育</title>
</head>
<body>
<h1 class="info bg" float='left'>欢迎大家来到马士兵教育</h1>
<a href="http://www.mashibing.com"> 马士兵教育</a>
<h2><!--注释的内容--></h2>
</body>
</html>
'''
# bs=BeautifulSoup(html,'html.parser')
bs = BeautifulSoup(html, 'lxml')
print(bs.title) # 获取标签
print(bs.h1.attrs) # 获取h1标签的所有属性
# 获取单个属性
print(bs.h1.get('class'))
print(bs.h1['class'])
print(bs.a['href'])
# 获取文本内容
print(bs.title.text)
print(bs.title.string)
# 获取内容
print('--------', bs.h2.string) # 获取到h2标签中的注释的文本内容
print(bs.h2.text) # 因为h2标签中没有的文本内容
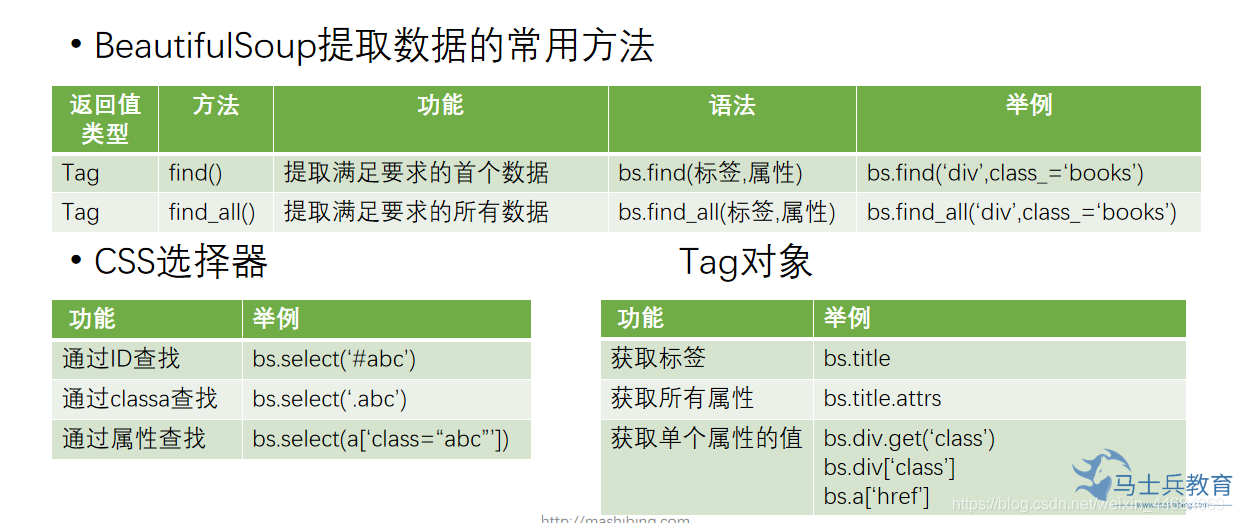 爬取淘宝首页,并用BeautifualSoup分析
爬取淘宝首页,并用BeautifualSoup分析
import requests
from bs4 import BeautifulSoup
url = 'https://www.taobao.com/'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.100 Safari/537.36'}
resp = requests.get(url, headers)
# print(resp.text)
bs = BeautifulSoup(resp.text, 'lxml')
a_list = bs.find_all('a')
# print(len(a_list))
for a in a_list:
url = a.get('href')
if url == None:
continue
if url.startswith('http') or url.startswith('https'):
print(url)
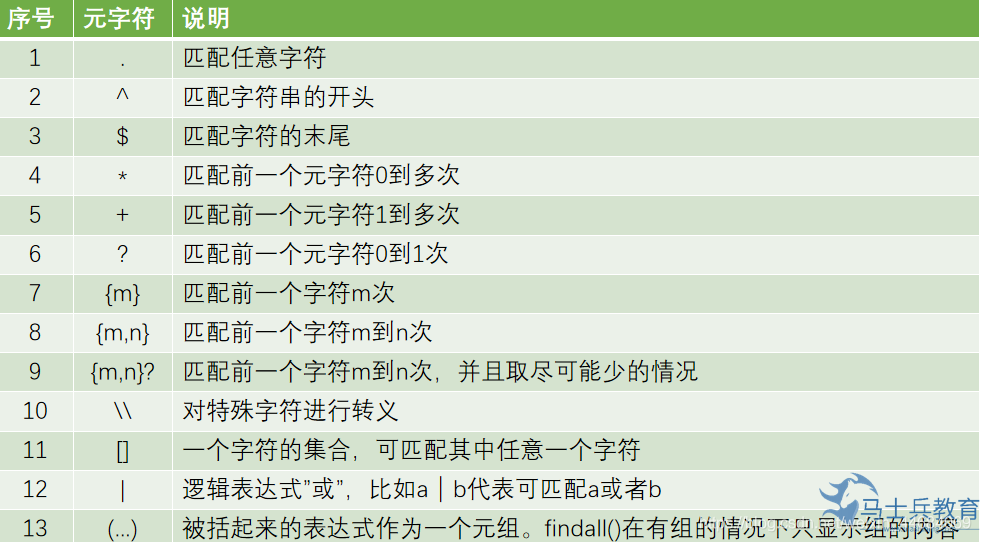
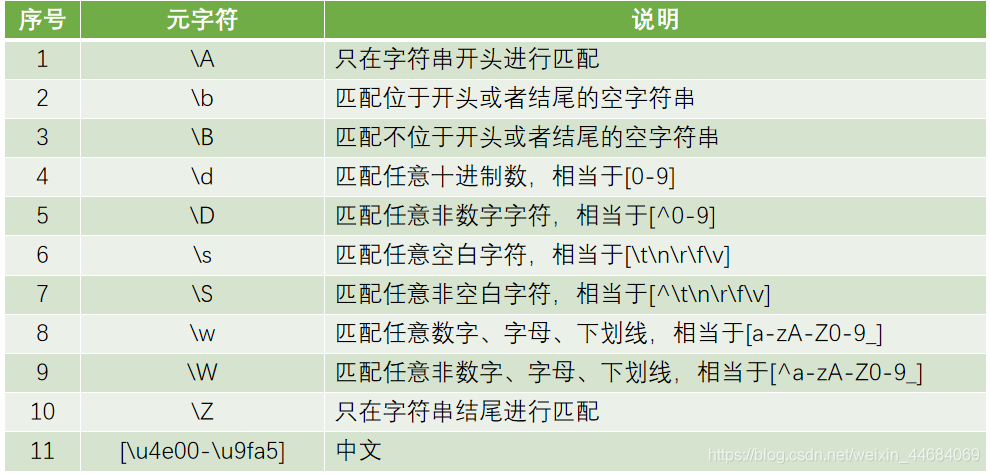
正则表达式
正则表达式
是一个特殊的字符序列,它能帮助用户便捷地检查一个字符串是否与某种模式匹配。
Python的正则模块是re,是Python的内置模块,不需要安装,导入即可

import re
s = 'Istudy study Python3.8 every day'
print('----------------match方法,从起始位置开始匹配------------')
print(re.match('I', s).group())
print(re.match('\w', s).group())
print(re.match('.', s).group())
print('---------------search方法,从任意位置开始匹配,匹配第一个---------------')
print(re.search('study', s).group())
print(re.search('s\w', s).group())
print('---------------findall方法,从任意位置开始匹配,匹配多个-----------------')
print(re.findall('y', s)) # 结果为列表
print(re.findall('Python', s))
print(re.findall('P\w+.\d', s))
print(re.findall('P.+\d', s))
print('--------------sub方法的使用,替换功能-------------------------')
print(re.sub('study', 'like', s))
print(re.sub('s\w+', 'like', s))
下载糗事百科小视频
import requests
import re
url = 'https://www.qiushibaike.com/video/'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.100 Safari/537.36'}
resp = requests.get(url, headers=headers)
# print(resp.text)
info = re.findall('<source src="(.*)" type=\'video/mp4\' />', resp.text)
# print(info)
lst = []
for item in info:
lst.append('https:' + item)
count = 0
for item in lst:
count += 1
resp = requests.get(item, headers=headers)
with open('video/' + str(count) + '.mp4', 'wb') as file:
file.write(resp.content)
print('视频下载完毕')pyquery解析数据
pyquery库是jQuery的Python实现,能够以jQuery的语法来操作解析 HTML 文档,易用性和解析速度都很好
前提条件:
你对CSS选择器与JQuery有所了解
非Python标准模块,需要安装
安装方式
pip install pyquery
测试方式
Import pyquery
 字符串方式
字符串方式
from pyquery import PyQuery as py
html='''
<html>
<head>
<title>PyQuery</title>
</head>
<body>
<h1>PyQuery</h1>
</body>
</html>
'''
doc=py(html) #创建PyQuery的对象,实际上就是在进行一个类型转换,将str类型转成PyQuery类型
print(doc)
print(type(doc))
print(type(html))
print(doc('title'))url方式
from pyquery import PyQuery
doc=PyQuery(url='http://www.baidu.com',encoding='utf-8')
print(doc('title'))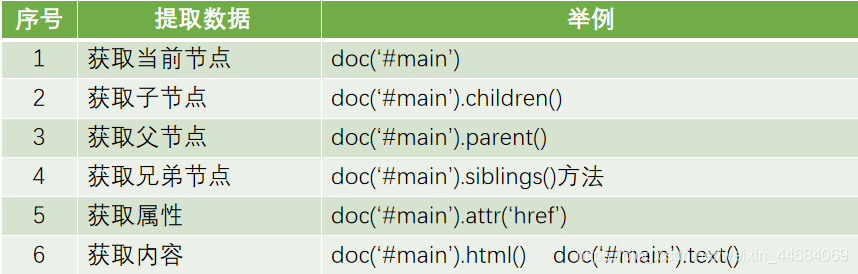
from pyquery import PyQuery
html='''
<html>
<head>
<title>PyQuery</title>
</head>
<body>
<div id="main">
<a href="http://www.mashibing.com">马士兵教育</a>
<h1>欢迎来到马士兵教育</h1>
我是div中的文本
</div>
<h2>Python学习</h2>
</body>
</html>
'''
doc=PyQuery(html)
#获取当前节点
print(doc("#main"))
#获取父节点,子节点,兄弟节点
print('-----------父节点----------------')
print(doc("#main").parent())
print('-----------子节点----------------')
print(doc("#main").children())
print('-------------兄弟节点------------------')
print(doc("#main").siblings())
print('------------------获取属性---------------')
print(doc('a').attr('href'))
print('------------获取标签的内容----------------')
print(doc("#main").html())
print('-------------------------')
print(doc("#main").text())
例子 爬取起点小说网
url = 'https://www.qidian.com/rank/yuepiao'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.100 Safari/537.36'}
resp = requests.get(url, headers=headers)
# print(resp.text)
# 初始化PyQuery对象
doc = PyQuery(resp.text) # 使用字符串初始化方式初始化PyQuery对象
# a_tag=doc('h4 a')
# print(a_tag)
names = [a.text for a in doc('h4 a')]
authors = doc('p.author a')
author_lst = []
for index in range(len(authors)):
if index % 2 == 0:
author_lst.append(authors[index].text)
# print(author_lst)
# print(names)
for name, author in zip(names, author_lst):
print(name, ':', author)
JSON文件存储
JSON JSON(JavaScript Object Notation)是一种轻量级的数据交换格式,它是基于ECMAScript的一个子集 JSON采用完全独立于语言的文本格式 JSON在Python中分别由list和dict组成。

import json
s = '{"name":"张三"}'
# 将字符串转成对象
obj = json.loads(s)
print(type(obj))
print(obj)
# 将对象转成字符串类型
ss = json.dumps(obj, ensure_ascii=False)
print(type(ss))
print(ss)
# 把对象(dict)保存到文件中
json.dump(obj, open('movie.txt', 'w', encoding='utf-8'), ensure_ascii=False)
# 把文件中的内容读取到Python程序
obj2 = json.load(open('movie.txt', encoding='utf-8'))
print(obj2)
print(type(obj2))
案列 获取京东销量最好的粽子信息
import requests
import json
def send_request():
url = 'https://club.jd.com/comment/productPageComments.action?callback=fetchJSON_comment98&productId=7252335&score=0&sortType=5&page=0&pageSize=10&isShadowSku=0&fold=1'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.100 Safari/537.36'}
resp = requests.get(url, headers=headers)
return resp.text
def parse_json(data):
return data.replace('fetchJSON_comment98(', '').replace(');', '') # 如果为str类型
def type_change(data):
return json.loads(data)
def save(obj):
json.dump(obj, open('京东销售最好的粽子数据.txt', 'w', encoding='utf-8'), ensure_ascii=False)
def start():
data = send_request()
obj = parse_json(data)
# print(type(type_change(s)))
save(obj)
# print(s)
if __name__ == '__main__':
start()CSV文件
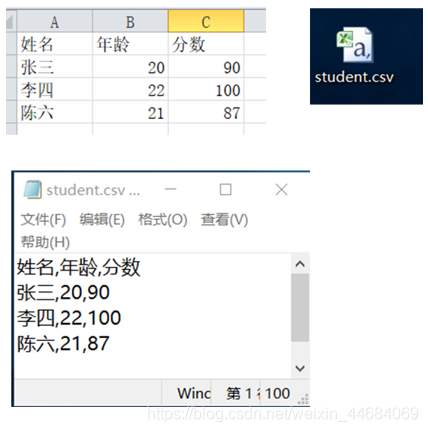
什么是CSV文件
CSV是Comma Separated Values 称为逗号分隔值,以一种以.csv结尾的文件
CSV文件的特点
值没有类型,所有值都是字符串
不能指定字体颜色等样式
不能指定单元格的宽高,
不能合并单元格
没有多个工作表
不能嵌入图像图表
CSV文件的创建
CSV文件的创建
新建Excel文件
编写数据
另存为CSV文件
CSV文件的操作
向CSV文件中写入数据 引入csv模块 使用open()函数创建 csv文件 借助csv.write()函数创建writer对象 调用writer对象的writerow()方法写入一行数据 调用writer对象的writerows()方法写入多行数据 从CSV文件中读取数据 引入csv模块 使用open()函数打开CSV文件 借助csv.reader()函数创建reader对象 读到的每一行都是一个列表(list) newline是为了防止两倍行距
写入内容
import csv
with open('student.csv','a+',newline='') as file:
#创建一个writer对象
writer=csv.writer(file)
#一次写一行数据
writer.writerow(['麻七',23,90])
#一次写入多行数据
lst=[
['Jack',23,98],
['Marry',22,87],
['Lili',22,76]
]
writer.writerows(lst)读取内容
import csv
with open('student.csv','r',newline='') as file:
#创建reader对象
reader=csv.reader(file)
for row in reader:
print(row)粽子评论存储到csv文件中
import requests
import json
import csv
def send_request():
url = 'https://club.jd.com/comment/productPageComments.action?callback=fetchJSON_comment98&productId=7252335&score=0&sortType=5&page=0&pageSize=10&isShadowSku=0&fold=1'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.100 Safari/537.36'}
resp = requests.get(url, headers=headers)
return resp.text
def parse_html(data):
s=data.replace('fetchJSON_comment98(', '').replace(');', '')
dict_data=json.loads(s)
comments_list=dict_data['comments']
lst=[]
for comment in comments_list:
content=comment['content'] #评论的内容
creationTime=comment['creationTime'].split(' ')[0] #获取评论时间
lst.append([content,creationTime])
save(lst)
def save(lst):
with open('粽子的评论数据.csv', 'w', newline='')as file:
writer = csv.writer(file)
writer.writerows(lst)
def start():
data = send_request()
parse_html(data)
if __name__ == '__main__':
start()