推荐
专栏
教程
课程
飞鹅
本次共找到2384条
网络爬虫
相关的信息
专注IP定位
•
3年前
网络爬虫技术及应用
前言:网络爬虫技术顺应互联网时代的发展应运而生。目前网络爬虫的使用范围是比较广的,在不同的领域中都有使用,爬虫技术更是广泛地被应用于各种商业模式的开发。一、什么是网络爬虫互联网是一个庞大的数据集合体,网络信息资源丰富且繁杂,如何在数据(ht
京东云开发者
•
2年前
Python网络爬虫原理及实践 | 京东云技术团队
网络爬虫:是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。网络爬虫相关技术和框架繁多,针对场景的不同可以选择不同的网络爬虫技术。
Irene181
•
4年前
详解4种类型的爬虫技术
导读:网络爬虫是一种很好的自动采集数据的通用手段。本文将会对爬虫的类型进行介绍。作者:赵国生王健来源:大数据DT(ID:hzdashuju)聚焦网络爬虫是“面向特定主题需求”的一种爬虫程序,而通用网络爬虫则是捜索引擎抓取系统(Baidu、Google、Yahoo等)的重要组成部分,主要目的是将互联网上的网页下载到本地,形成一个互联网内
爬虫程序大魔王
•
3年前
爬虫数据采集
经常有小伙伴需要将互联网上的数据保存的本地,而又不想自己一篇一篇的复制,我们第一个想到的就是爬虫,爬虫可以说是组成了我们精彩的互联网世界。网络搜索引擎和其他一些网站使用网络爬虫或蜘蛛软件来更新他们的网络内容或其他网站的网络内容索引。网络爬虫复制页面以供搜索引擎处理,搜索引擎对下载的页面进行索引,以便用户可以更有效地搜索。这都是爬虫数据采集的功劳。这篇文章我总
Stella981
•
4年前
Python Scrapy 实战
PythonScrapy什么是爬虫?网络爬虫(英语:webcrawler),也叫网络蜘蛛(spider),是一种用来自动浏览万维网的网络机器人。其目的一般为编纂网络索引。Python爬虫在爬虫领域,Python几乎是霸主地位,将网络一切数据作为资源,通过自动化程序进行有针对性
Wesley13
•
4年前
Java网络爬虫(十三)
先说点题外话吧,在我刚开始学习爬虫的时候,有一次一个学长给了我一个需求,让我把京东图书的相关信息抓取下来。恩,因为真的是刚开始学习爬虫,并且是用豆瓣练得手,抓取了大概500篇左右的影评吧,然后存放到了mysql中,当时觉得自己厉害的不行,于是轻松的接下了这个需求。。。然后信心满满的开始干活。。首先查看网页源代码。。。???我需要的东西源代码里面没有!!!
linbojue
•
6个月前
用C语言提升网络爬虫效率的策略指南
011.网络爬虫简介网络爬虫是一种能够自动获取和解析网页内容的工具,利用C语言编写网络爬虫程序能够有效地提取所需数据。通过C语言,您可以轻松地实现对网页的解析和数据的提取。1.1◆C语言与网络爬虫在C语言中,您可以利用诸如cspider这样的库来简化网络爬
helloworld_38131402
•
3年前
识别网络爬虫的策略分析
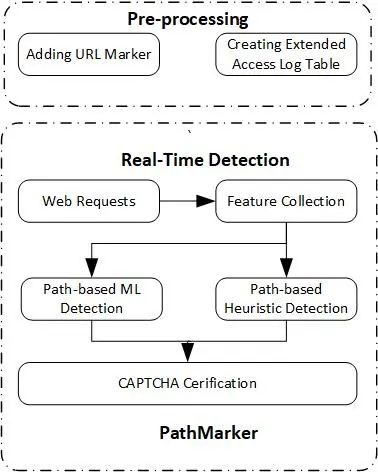
识别网络爬虫的策略分析一、网络爬虫爬虫(crawler)也可以被称为spider和robot,通常是指对目标网站进行自动化浏览的脚本或者程序,包括使用requests库编写脚本等。随着互联网的不断发展,网络爬虫愈发常见,并占用了大量的网络资源。由爬虫产生的网络流量占总流量的37.2%,其中由恶意爬虫产生的流量约占65%图1PathMarker的体系架构上述
小白学大数据
•
1年前
网络延迟对Python爬虫速度的影响分析
Python爬虫因其强大的数据处理能力和灵活性而被广泛应用于数据抓取和网络信息收集。然而,网络延迟是影响爬虫效率的重要因素之一。本文将深入探讨网络延迟对Python爬虫速度的影响,并提供相应的代码实现过程,以帮助开发者优化爬虫性能。网络延迟的定义与影响网络
1
2
3
•••
239