推荐
专栏
教程
课程
飞鹅
本次共找到4261条
网络存储
相关的信息
Karen110
•
4年前
网络知识扫盲:扒开 TCP 的外衣,我看清了 TCP 的本质
后台回复关键字“黑魔法”,即可获取明哥整理的《Python黑魔法指南》大家好,我是明哥。从上周开始,我开始了一个新的文章专栏:网络知识扫盲并写下了第一篇文章:从阅读和在看数来看,大家对这个系列还是比较期待的,所以这周我全身心地投入本篇文章的编写,用了整整4个晚上的时间梳理了这篇关于 TCP 的重点知识,另外还参考小林coding的文章配图,用了一天
DeepFlow开源
•
2年前
K8s 应用的网络可观测性: Cilium VS DeepFlow
K8s是微服务设计理念能落地的最重要的承载体,本文主要聚焦谈谈K8s的网络可观测性,以及其给基础设施/应用等团队能带来的价值。
Karen110
•
4年前
盘点那些年我们一起玩过的网络安全工具
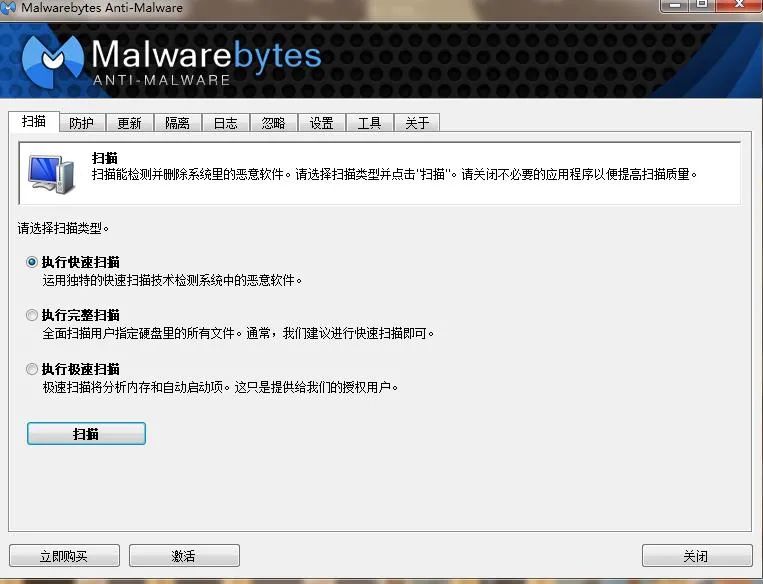
大家好,我是IT共享者,人称皮皮。这篇文章,皮皮给大家盘点那些年,我们一起玩过的网络安全工具。一、反恶意代码软件1.Malwarebytes这是一个检测和删除恶意的软件,包括蠕虫,木马,后门,流氓,拨号器,间谍软件等等。快如闪电的扫描速度,具有隔离功能,并让您方便的恢复。包含额外的实用工具,以帮助手动删除恶意软件。分为两个版本,Pro和Free,Pro
Stella981
•
4年前
Scrapy学习
基础知识爬虫发展史!(https://images2018.cnblogs.com/blog/1275420/201805/1275420201805212058308111094218837.png)爬虫去重1.存储到数据库中存取速度慢
Stella981
•
4年前
Redis哈希(Hash)
个人学习笔记Hash是一个string类型的field和value的映射表,hash适合存储对象。插入HashHMSETzxqname"redistutorial"description"redisbasiccommandsforcaching"likes20visitors23000获取Hash
Stella981
•
4年前
Python数据可视化 之 使用API
使用requests模块来请求网站数据1importrequests234执行API调用并存储响应5url'https://api.github.com/search/repositories?qlanguage:python&sortstars'6r
Python进阶者
•
2年前
盘点一个Python网络爬虫抓取股票代码问题(上篇)
大家好,我是皮皮。一、前言前几天在Python白银群【厚德载物】问了一个Python网络爬虫的问题,这里拿出来给大家分享下。二、实现过程这个问题其实for循环就可以搞定了,看上去粉丝的代码没有带请求头那些,导致获取不到数据。后来【瑜亮老师】、【小王子】给了
Python进阶者
•
2年前
盘点一个Python网络爬虫抓取股票代码问题(下篇)
大家好,我是皮皮。一、前言前几天在Python白银群【厚德载物】问了一个Python网络爬虫的问题,这里拿出来给大家分享下。二、实现过程这个问题其实for循环就可以搞定了,看上去粉丝的代码没有带请求头那些,导致获取不到数据。后来【瑜亮老师】、【小王子】给了
燕青
•
2年前
尖叫青蛙网络爬虫工具:Screaming Frog SEO Spider Mac破解下载
的爬取功能强大而灵活。它能够快速准确地爬取网站的所有页面和链接,让您可以全面了解网站的架构和内容。而且,您可以根据需要设置爬取的深度和规则,确保数据的获取符合您的需求。其次,ScreamingFrogSEOSpider的分析功能非常强大。它能够详细分析每个
流浪剑客
•
2年前
「最新更新」Screaming Frog SEO Spider for Mac 网络爬虫开发工具
是一款功能强大的SEO工具,可以帮助用户进行网站的SEO优化和分析。以下是ScreamingFrogSEOSpider的主要特点:网站爬取:可以快速扫描整个网站并列出所有内部和外部页面,包括URL,标题,描述和头信息等。数据导出:可以将扫描结果导出为CSV
1
•••
147
148
149
•••
427