推荐
专栏
教程
课程
飞鹅
本次共找到2809条
存储引擎
相关的信息
京东云开发者
•
3年前
Clickhouse表引擎探究-ReplacingMergeTree
作者:耿宏宇1表引擎简述1.1官方描述MergeTree系列的引擎被设计用于插入极大量的数据到一张表当中。数据可以以数据片段的形式一个接着一个的快速写入,数据片段在后台按照一定的规则进行合并。相比在插入时不断修改(重写)已存储的数据,这种策略会高效很多。R
Peter20
•
4年前
Mysql中MVCC的使用及原理详解
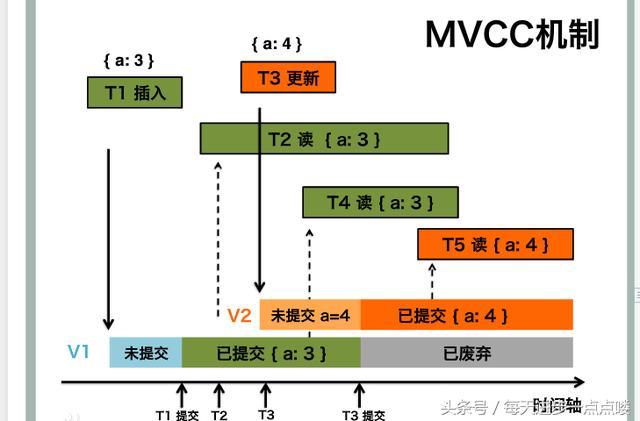
数据库默认隔离级别:RR(RepeatableRead,可重复读),MVCC主要适用于Mysql的RC,RR隔离级别创建一张存储引擎为testmvcc的表,sql为:CREATETABLEtestmvcc(idint(11)DEFAULTNULL,namevarchar(11)DEFAULTNULL)ENGINE\InnoDB
Wesley13
•
4年前
MySQL表介绍
MySQLInnoDB表介绍一、索引组织表在InnoDB引擎中,表都是根据主键顺序存放的。这种存储方式称为索引组织表,在InnoDB引擎中,每张表都有逐渐。如果没有显示定义主键,则引擎会按照以下方式选择或创建主键。(1)、判断表是否有非空唯一索引,如果有,则该字段为主键。如果有多个非空唯一索引,则选择第一个定义的非空索引字段作为
Stella981
•
4年前
Nebula 架构剖析系列(二)图数据库的查询引擎设计
摘要上文(存储篇)说到数据库重要的两部分为存储和计算,本篇内容为你解读图数据库Nebula在查询引擎 QueryEngine 方面的设计实践。在Nebula中,QueryEngine是用来处理Nebula查询语言语句(nGQL)。本篇文章将带你了解NebulaQueryEngine的架构。!(https://o
Stella981
•
4年前
ELK部署检测nginx日志demo
ELKE:ElasticSearch搜索引擎存储https://www.elastic.co/cn/downloads/elasticsearch(https://www.oschina.net/action/GoToLink?urlhttps%3A%2F%2Fwww.elastic.co%2Fcn%2Fdownloads%2F
Stella981
•
4年前
CentOS6 x64下编译TiDB
TiDB由三部分组成:tidb(SQL解析引擎)、tikv(存储引擎)、pd(placementdriver,提供时间戳服务和系统拓扑维护)。其中tidb和pd用go语言开发,tikv用rust语言开发。 官方要求TiDB在CentOS7中使用,但有时确实需要在CentOS6及以下部署,此时可根据如下方式编译:1\.配置编译环境为了提
Stella981
•
4年前
ClickHouse和他的朋友们(5)存储引擎技术进化与MergeTree
21世纪的第二个10年,虎哥已经在存储引擎一线奋战近10年,由于强大的兴趣驱动,这么多年来几乎不放过arXiv上与存储相关的每一篇paper。尤其是看到带有draft的paper时,有一种乞丐听到“叮当”响时的愉悦。看paper这玩意就像鉴宝,多数是“赝品”,需要你有“鉴真”的本领,否则今天是张三的算法超越xx,明儿又是王二的硬件提升
Wesley13
•
4年前
5 mysql底层解析——b+ tree和每个page存储结构,包括连接、解析、缓存、引擎、存储等
上一篇(https://www.oschina.net/action/GoToLink?urlhttps%3A%2F%2Fblog.csdn.net%2Ftianyaleixiaowu%2Farticle%2Fdetails%2F100079700),我们学习了innodb文件系统内部大的存储结构,包括段(segment),簇(extent),页(pa
Stella981
•
4年前
MapGis如何实现WebGIS分布式大数据存储的
作为解决方案厂商,MapGis是如何实现分布式大数据存储的呢?MapGIS在传统关系型空间数据库引擎MapGISSDE的基础之上,针对地理大数据的特点,构建了MapGISDataStore分布式数据库引擎,其集成整合了多种开源分布式数据库和文件系统,分别用来存储和管理关系型数据,切片型数据,实时型数据和非结构化数据,形成针对地理大数据应用场景相关的解
京东云开发者
•
2年前
慢 SQL 优化之索引的作用是什么? | 京东云技术团队
本文针对MySQL数据库的InnoDB存储引擎,介绍其中索引的实现以及索引在慢SQL优化中的作用。本文主要讨论不同场景下索引生效与失效的原因。
1
•••
5
6
7
•••
281