
前言
本文针对 MySQL 数据库的 InnoDB 存储引擎,介绍其中索引的实现以及索引在慢 SQL 优化中的作用。
本文主要讨论不同场景下索引生效与失效的原因。
慢SQL与索引的关系
慢SQL优化原则
数据库也是应用,MySQL 作为一种磁盘数据库,属于典型的 IO 密集型应用,并且随机 IO 比顺序 IO 更昂贵。
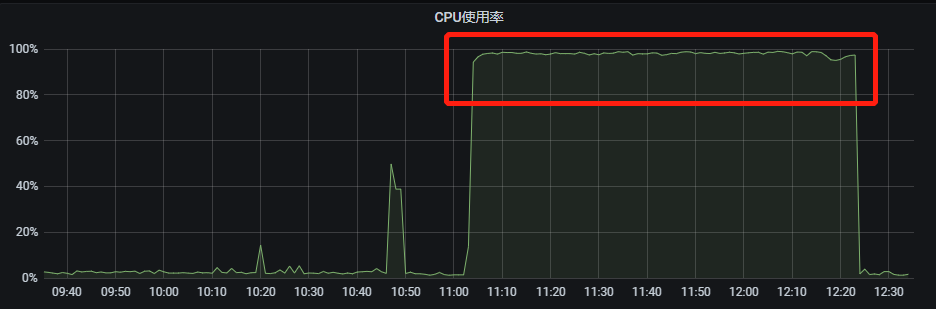
真实的慢 SQL 往往会伴随着大量的行扫描、临时文件排序,直接影响就是磁盘 IO 升高、CPU 使用率升高,正常 SQL 也变为了慢 SQL,对于应用来说就是大面积执行超时。
线上很多事故都与慢 SQL 有关,因此慢 SQL 治理已成为 DBA 与业务研发的共识。
 )
)慢SQL的优化原则为:减少数据访问量与减少计算操作
减少访问量:
•创建合适的索引
•减少不必要访问的列
•使用覆盖索引
•语句改写
•数据结转
减少计算操作:
•排序列加入索引
•适当的列冗余
•SQL 拆分
•计算功能拆分
可以将慢 SQL 优化的方法分为三类:
•查询优化
•索引优化
•库表结构优化
其中索引是数据库中用来提升性能的最常用工具。
可是,为什么索引可以加快查询,索引一定可以加快查询吗?
索引的作用
要回答这个问题,可以对比没有索引与有索引时查询操作的性能差异。
在此之前,首先介绍下查询操作的处理流程。
查询操作可以分为以下两步:
•定位到记录所在的页
•从所在的页中定位到具体的记录
其中从页中定位记录的方法依赖每个页面中创建的Page Directory(页目录),因此关键在于如何定位页。
数据保存在磁盘上,数据处理发生在内存中,数据页是磁盘与内存之间交互的基本单位,也是 MySQL 管理存储空间的基本单位,大小默认为 16KB。
因此通常一次最少从磁盘中读取 16KB 的内容到内存中,一次最少把内存中的 16KB 内容刷新到磁盘中。
要理解索引的作用,需要首先明确没有索引时如何定位页。
没有索引时,由于每个页中的数据没有规律,因此无法快速定位记录所在的页,只能从第一个页沿双向链表向后遍历,也就是说需要遍历所有数据页依次判断是否满足查询条件。
简单来说,没有索引时每次查询都是全表扫描。
因此索引需要解决的主要问题就是实现每个数据页中数据有规律,具体是保证下一个数据页中用户记录的索引列值必须大于上一个页中用户记录的索引列值。
索引是存储引擎用于快速查找的一种排序的数据结构。
有索引时,优化器首先基于成本自动选择最优的执行计划,然后基于索引的有序性可以通过扫描更少的数据页定位到满足条件的数据。
具体原因与索引的数据结构有关,下面基于索引的数据结构介绍常见的索引生效与索引失效的场景。
索引
索引的数据结构
索引是一种以空间换时间思想的具体实现,用于加速查询。
MySQL 中由存储引擎层实现索引,InnoDB 存储引擎中基于 B+ 树实现,因此每个索引都是一棵 B+ 树。
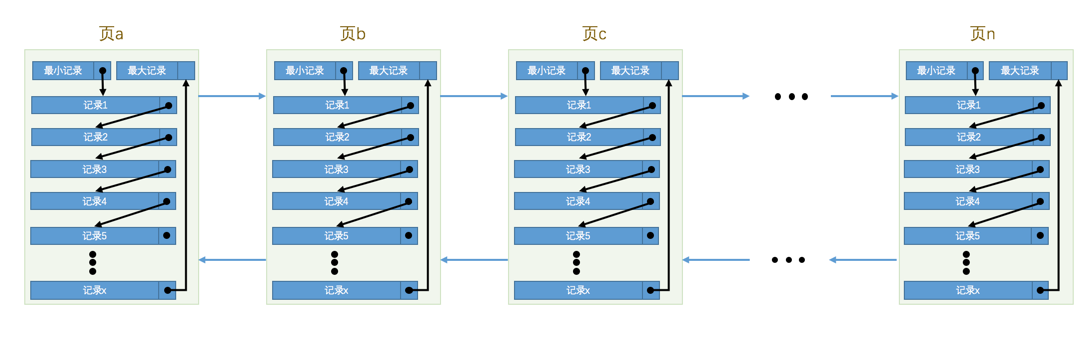
索引用于组织页,页用于组织行记录。在介绍索引的结构之前首先介绍页的结构,如下图所示。
 )
)其中:
•每个数据页中的记录会按照主键值从小到大的顺序组成一个单向链表,依赖行记录的Page Header中next_record属性实现,其中保存下一条记录相对于本条记录的地址偏移量;
•数据页之间组成一个双向链表,依赖数据页的File Header中FIL_PAGE_PREV和FIL_PAGE_NEXT属性实现,其中保存本页的上一个和下一个页的页号。
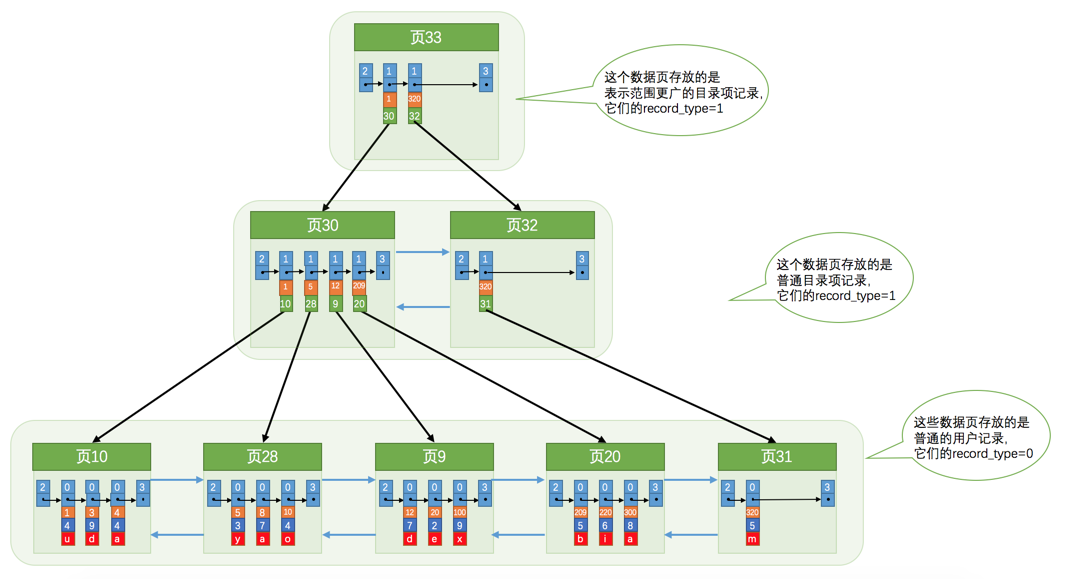
多个页通过树进行组织,其中保存用户数据与目录项。目录项中保存页的用户记录中主键的最小值与页号,从而保证下一个数据页中用户记录的主键值大于上一个页中用户记录的主键值。
 )
)其中:
•用户数据保存在叶子节点,目录项保存在非叶子节点,每个节点中可能保存多个页;
•最上面的节点称为根节点,根节点的地址保存在内存的数据字典中;
•B+ 树的深度一般控制在 3 层以内,因此定位到单条记录不超过 3 次 IO。
因此,页面和记录是排好序的,就可以通过二分法来快速定位查找。
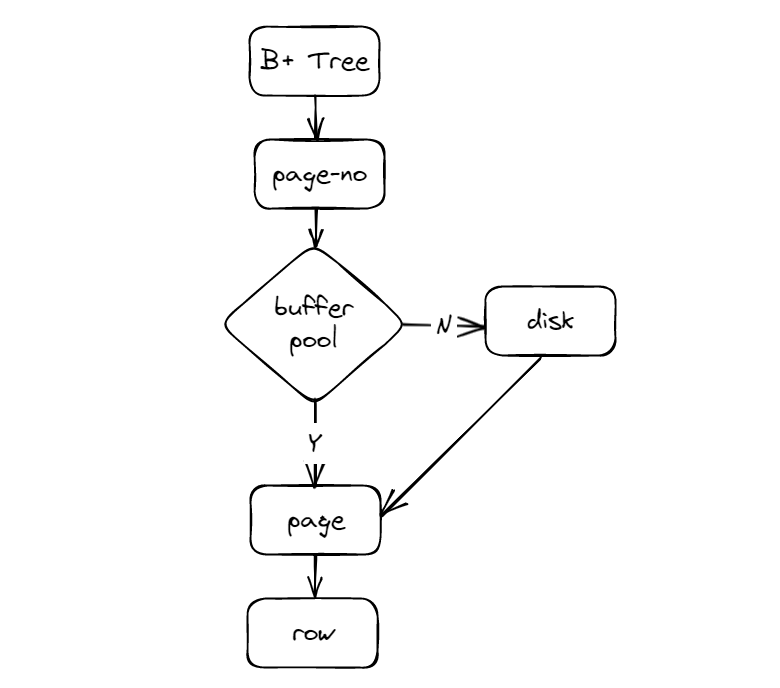
有索引时,查询操作变成了什么样呢?
•从 B+ 树的根节点出发,一层一层向下搜索目录项,由于上层节点保存的都是下层节点的最小值,因此可以快速定位到数据可能所在的页;
•如果数据页在缓存池中,直接从内存中获取,否则从磁盘加载到内存中;
•数据页内部二分查找定位满足条件的记录行。
 )
)索引保存的数据
索引中保存的数据与索引的类型有关。
索引可以分为两种类型:
•聚簇索引,主键索引。叶子节点中保存主键值+对应的完整行记录,目录项中保存主键最小值+页号。InnoDB 属于索引组织表,每张表都有聚簇索引,因此表必须有主键,表中行的物理顺序与索引的逻辑顺序相同;
•非聚簇索引,二级索引,在非主键的其他列上建的索引。叶子节点中保存索引列的值+对应的主键值,目录项中保存索引列最小值+对应的主键值+页号。
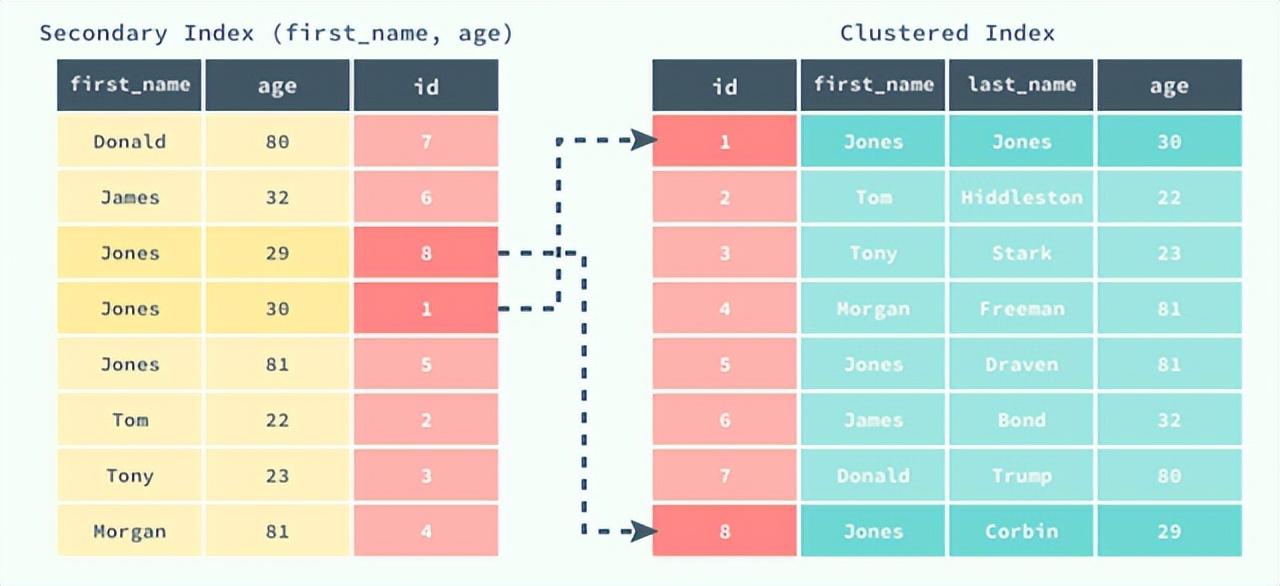 )
)介绍三个与索引性能相关的概念:
| 概念 | explain.extra |
|---|---|
| 覆盖索引 | Using index |
| 回表 | Using where |
| 索引下推 | Using index condition |
•覆盖索引,当二级索引中包含要查询的所有字段时,这个索引称为覆盖索引;
•回表,当二级索引中不包含要查询的所有字段时,就需要先通过二级索引查出主键索引,再通过主键索引查询二级索引中没有的其他列的数据,这个过程叫做回表;
•索引下推,用于优化使用二级索引从表中检索行的实现。条件过滤可以下推到存储引擎层进行,先由索引元组(index tuple)根据查询条件进行过滤,满足条件的前提下才回表,否则跳过,相当于延迟加载数据行,因此 ICP 可以降低回表次数与 IO 次数。
正常情况下看不到二级索引中隐藏的主键,但实际上,如下所示查看锁信息,显示LOCK_DATA: '17118168721', 2,其中 2 就是二级索引中保存的主键值。
ENGINE:INNODB
ENGINE_LOCK_ID:140123070938328:14:7:4:140122972537552
ENGINE_TRANSACTION_ID:2032566
THREAD_ID:157
EVENT_ID:44
OBJECT_SCHEMA: test_zk
OBJECT_NAME: t_lock_test
PARTITION_NAME:NULL
SUBPARTITION_NAME:NULL
INDEX_NAME: idx_uk_mobile
OBJECT_INSTANCE_BEGIN:140122972537552
LOCK_TYPE: RECORD
LOCK_MODE: X,REC_NOT_GAP
LOCK_STATUS: GRANTED
LOCK_DATA:'17118168721',2如下所示,工作中多次遇到研发创建二级索引时显式指定主键,实际上是不需要的,二级索引末尾自动保存主键。
alter table payable_unsettled
add index idx_seller_no_recno_id(seller_no, receipt_no,id) using BTREE;因此二级索引+主键与联合索引的相同点是依次排序,不同点是索引中保存的数据不同。
索引生效的场景
等值查询
线上环境多次遇到表没有创建二级索引,只有主键索引。
SQL
select sys_no,area_no,area_name,dc_no,dc_name,wh_no,wh_name, business_type,business_no,item_code,item_grade, item_result,item_remark,status, yn,ts,create_time,create_pin,update_time,update_pin
from
evaluate_result
where
yn =1
and wh_no ='611-887-2'
and business_no ='QNSYKF23020900000018'
and create_pin ='13940137489'
orderby
update_time desc;
# 执行用时
5 rows in set(7.311125 sec)执行计划,显示全表扫描
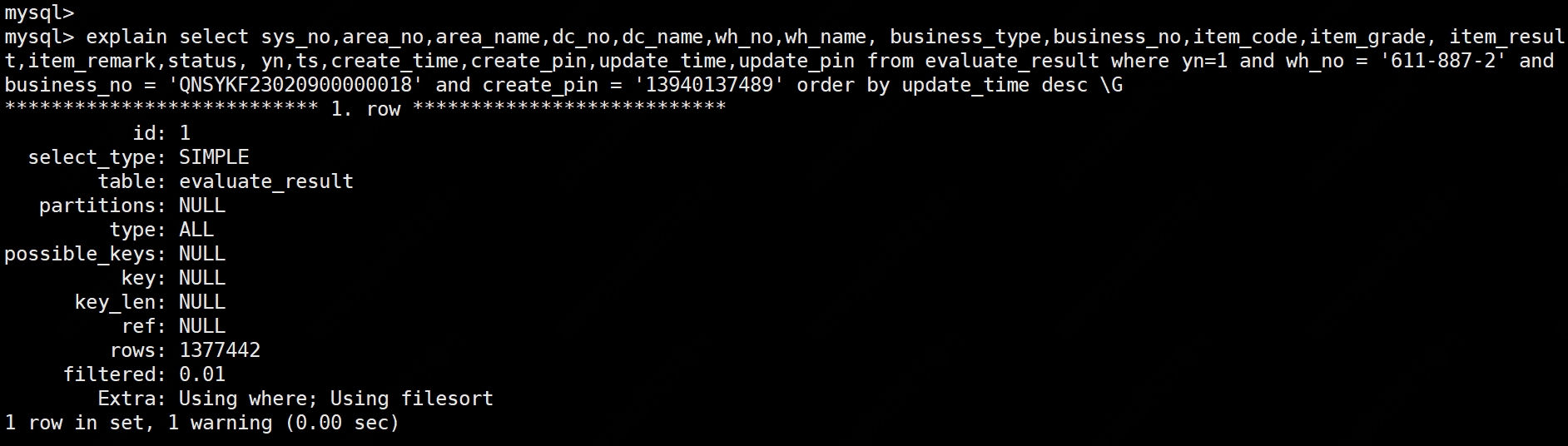 )
)表结构,显示查询字段无索引
mysql>show create table evaluate_result \G
***************************1.row***************************
Table: evaluate_result
CreateTable:CREATE TABLE `evaluate_result`(
`sys_no` bigint(20) NOT NULL AUTO_INCREMENT COMMENT '内部主键',
`wh_no` varchar(32) NOT NULL DEFAULT '' COMMENT'仓库编码',
`business_no` varchar(20) NOT NULL DEFAULT '' COMMENT'调研业务主键',
...
PRIMARY KEY(`sys_no`)
)ENGINE=InnoDB AUTO_INCREMENT=2007412 DEFAULT CHARSET=utf8 COMMENT='评价结果表'
1rowinset(0.00 sec)优化方法:创建索引
alter table evaluate_result add index idx_wh_bus_no(wh_no,business_no);执行计划
***************************1.row***************************
id:1
select_type: SIMPLE
table: evaluate_result
partitions:NULL
type: ref
possible_keys: idx_wh_bus_no
key: idx_wh_bus_no
key_len:160
ref: const,const
rows:5
filtered:1.00
Extra:Using index condition;Using where;Using filesort
1rowinset,1 warning (0.00 sec)
# 执行用时
5 rows in set(0.01 sec)其中:
•key_len: 160,表明联合索引的两个字段都用到了,(32+20) * 3+2 * 2 = 160。
等值查询索引生效的原因是相同值的数据组成单向链表,因此定位到满足条件的 5 行数据需要扫描的行数从 1377442 行降低到 5 行。
范围查询
SQL
select
id
from
board_chute
where
status=1
and create_time <= date_sub(now(),interval 24 hour);执行计划,显示全表扫描
***************************1.row***************************
id:1
select_type: SIMPLE
table: board_chute
partitions:NULL
type:ALL
possible_keys: idx_create_time
key:NULL
key_len:NULL
ref:NULL
rows:407632
filtered:5.00
Extra:Using where
1rowinset,1 warning (0.00 sec)查询字段有索引,但是索引失效
KEY`idx_create_time`(`create_time`),status 字段的区分度
mysql> select status,count(*) from board_chute group by status;
+--------+----------+
| status | count(*) |
+--------+----------+
| 0 | 407317 |
| 1 | 4309 |
+--------+----------+
2 rows in set (0.17 sec)因此范围查询索引失效的原因是查看数据量大并且需要回表。
优化方法:创建联合索引实现覆盖索引
alter table board_chute add index idx_status_create_time(status, create_time);执行计划,显示 Using index 表明用到了覆盖索引,不需要回表。
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: board_chute
partitions: NULL
type: range
possible_keys: idx_create_time,idx_status_create_time
key: idx_status_create_time
key_len: 8
ref: NULL
rows: 203816
filtered: 10.00
Extra: Using where; Using index
1 row in set, 1 warning (0.00 sec)范围查询索引生效的原因是叶子节点中除了保存索引,还保存指向下个节点的指针,因此遍历叶子节点就可以获得范围值。
因此建议使用 between and 代替 in,如select * from T where k in (1,2,3,4,5);对应 5 次树的搜索,而select * from T where k between 1 and 5;对应 1 次树的搜索。
假设索引基于哈希表实现,可以通过散列函数将 key 值转换成一个固定的地址,如果发生哈希碰撞就在这个位置拉出一个链表。因此哈希表的优点是插入操作的速度快,根据 key 直接往后追加即可。但由于散列函数的离散特性,经过散列函数处理后的 key 将失去原有的顺序,所以哈希表无法满足范围查询,只适合等值查询。
注意上述索引生效的场景并非绝对成立,需要回表的记录越多,优化器越倾向于使用全表扫描,反之倾向于使用二级索引 + 回表的方式。
回表查询成本高有两点原因:
•需要使用到两个 B+ 树索引,一个二级索引,一个聚簇索引;
•访问二级索引使用顺序 I/O,访问聚簇索引使用随机 I/O。
因此有两条建议:
•建议为区分度高的字段创建索引,并且将区分度高的字段优先放在联合索引前面;
•建议优先使用覆盖索引,必须要回表时也需要控制回表的记录数,从而降低索引失效的风险。
索引失效的场景
违反最左匹配原则
SQL
select
count(*)
from
sort_cross_detail
where
yn =1
and org_id =3
and site_type =16
and site_code ='121671';执行计划,显示全表扫描
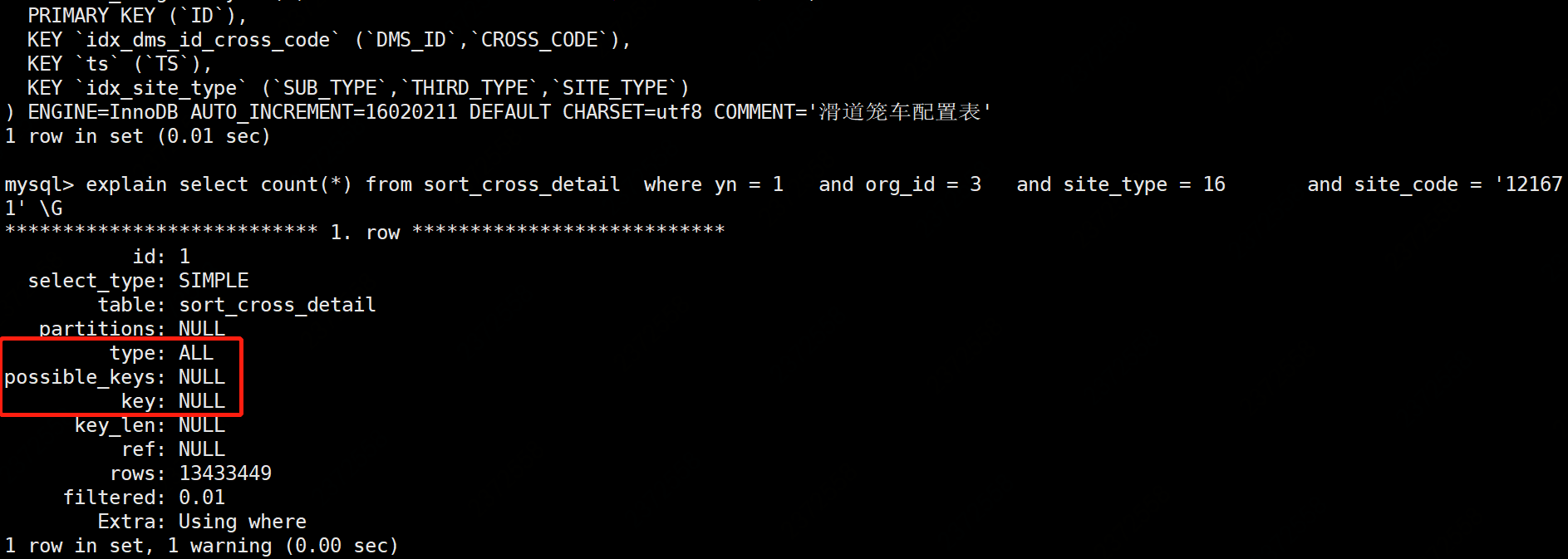 )
)尽管当前有联合索引 idx_site_type(SUB_TYPE, THIRD_TYPE, SITE_TYPE ),但由于查询条件中不包括 SUB_TYPE 字段,因此违反最左匹配原则,导致索引失效。
当前查询条件的多个字段区分度由高到低为 site_code、org_id、site_type。
 )
)优化方法:site_code 字段区分度很高,创建单列索引。
alter table sort_cross_detail add index `idx_site_code` (`SITE_CODE`);执行计划
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: sort_cross_detail
partitions: NULL
type: ref
possible_keys: idx_site_code
key: idx_site_code
key_len: 99
ref: const
rows: 1336
filtered: 0.10
Extra: Using where
1 row in set, 1 warning (0.00 sec)其中:
•使用联合索引过程中可以通过执行计划中的 key_len 字段评估具体 SQL 使用到了联合索引中的几个字段;
•联合索引中页面和记录首先按照联合索引前面的列排序,如果该列值相同,再按照联合索引后边的列排序。
违反最左匹配原则导致索引失效的原因是只有当索引前面的列相同时,后面的列才有序。
下面结合 innodb_ruby 工具解析 InnoDB 数据文件查看记录保存的顺序验证联合索引中索引前面的列不同时,后面的列可能无序。
准备测试数据。
mysql> show create table t_index \G
*************************** 1. row ***************************
Table: t_index
Create Table: CREATE TABLE `t_index` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`age` int(11) DEFAULT '0',
`name` varchar(10) DEFAULT '',
PRIMARY KEY (`id`),
KEY `idx_age_name` (`age`,`name`)
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8
1 row in set (0.00 sec)
mysql> insert into t_index(age, name) values(8, "Tom"),(8, "David"), (10, "Andy");
Query OK, 3 rows affected (0.00 sec)
Records: 3 Duplicates: 0 Warnings: 0
mysql> select * from t_index;
+----+------+-------+
| id | age | name |
+----+------+-------+
| 2 | 8 | David |
| 1 | 8 | Tom |
| 3 | 10 | Andy |
+----+------+-------+
3 rows in set (0.00 sec)
mysql> explain select * from t_index \G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: t_index
partitions: NULL
type: index
possible_keys: NULL
key: idx_age_name
key_len: 38
ref: NULL
rows: 3
filtered: 100.00
Extra: Using index
1 row in set, 1 warning (0.00 sec)其中:
•insert 时,三条记录按照 name 字段逆序;
•select 时,三条记录按照联合索引排序,并不是按照主键排序。
分别查看索引以及索引中保存的数据
[root@exps-test3 data]# innodb_space -s ibdata1 -T test_zk/t_index space-indexes
id name root fseg fseg_id used allocated fill_factor
218 PRIMARY 3 internal 1 1 1 100.00%
218 PRIMARY 3 leaf 2 0 0 0.00%
219 idx_age_name 4 internal 3 1 1 100.00%
219 idx_age_name 4 leaf 4 0 0 0.00%
[root@exps-test3 data]#
[root@exps-test3 data]# innodb_space -s ibdata1 -T test_zk/t_index -p 3 page-records
Record 127: (id=1) → (age=8, name="Tom")
Record 158: (id=2) → (age=8, name="David")
Record 191: (id=3) → (age=10, name="Andy")
[root@exps-test3 data]#
[root@exps-test3 data]# innodb_space -s ibdata1 -T test_zk/t_index -p 4 page-records
Record 145: (age=8, name="David") → (id=2)
Record 127: (age=8, name="Tom") → (id=1)
Record 165: (age=10, name="Andy") → (id=3)其中:
•主键与二级索引的根节点页号分别是 3 与 4;
•查看聚簇索引中保存的记录,按照主键排序;
•查看二级索引中保存的记录,联合索引中当 age 相同时,name 有序,age 不同时,name 无序。
上面提到,数据字典中保存表的根节点的地址,具体是 INFORMATION_SCHEMA.INNODB_SYS_INDEXES 系统表的 space 与 page_no 字段,分别保存表空间 ID 与根节点页号。
mysql> SELECT
tables.name, indexs.space, indexs.name, indexs.page_no
FROM
INFORMATION_SCHEMA.INNODB_SYS_TABLES as tables
inner join INFORMATION_SCHEMA.INNODB_SYS_INDEXES as indexs on tables.table_id = indexs.table_id
WHERE
tables.NAME = 'test_zk/t_index';
+-----------------+-------+--------------+---------+
| name | space | name | page_no |
+-----------------+-------+--------------+---------+
| test_zk/t_index | 106 | PRIMARY | 3 |
| test_zk/t_index | 106 | idx_age_name | 4 |
+-----------------+-------+--------------+---------+
2 rows in set (0.00 sec)其中 test_zk/t_index 表有两个索引,对应的根节点页号分别等于 3 与 4,与上面数据文件解析的结果一致。
order by limit
SQL,不建议使用 select *
select
*
from
waybill_order_added_value_report_detail goodsInfo
WHERE
goodsInfo.is_delete = 0
AND goodsInfo.org_no = '418'
AND goodsInfo.distribute_no = '636'
AND (
goodsInfo.company_code = 'EBU4418046542406'
OR goodsInfo.company_name = 'EBU4418046542406'
)
AND goodsInfo.network_type = 1
AND goodsInfo.should_operator_time >= concat('2022-05-01', ' 00:00:00')
AND goodsInfo.should_operator_time <= concat('2022-05-31', ' 23:59:59')
AND goodsInfo.uniform_status = 0
ORDER BY
goodsInfo.id DESC
LIMIT
0, 20 \G
# 执行用时
2 rows in set (1 min 9.71 sec)执行计划,主键全索引扫描,联合索引失效
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: goodsInfo
type: index
possible_keys: idx_org_dc_operator_time,idx_operator_time_network
key: PRIMARY
key_len: 8
ref: NULL
rows: 16156
Extra: Using where
1 row in set (0.00 sec)表结构与查询条件
# 查询条件
WHERE
goodsInfo.org_no = '418'
AND goodsInfo.distribute_no = '636'
AND goodsInfo.should_operator_time >= concat('2022-05-01', ' 00:00:00')
AND goodsInfo.should_operator_time <= concat('2022-05-31', ' 23:59:59')
# 索引
KEY `idx_org_dc_operator_time` (`org_no`,`distribute_no`,`should_operator_time`),
KEY `idx_operator_time_network` (`should_operator_time`,`network_type`)将 limit 20 修改为 limit 30,SQL 如下所示。
select
*
from
waybill_order_added_value_report_detail goodsInfo
WHERE
...
ORDER BY
goodsInfo.id DESC
LIMIT
0, 30 \G
# 执行用时
2 rows in set (0.06 sec)执行计划显示当改为 limit 30 时,联合索引生效。
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: goodsInfo
type: range
possible_keys: idx_org_dc_operator_time,idx_operator_time_network
key: idx_org_dc_operator_time
key_len: 132
ref: NULL
rows: 19024
Extra: Using index condition; Using where; Using filesort
1 row in set (0.00 sec)可见,索引的选择与 limit n 的 n 值也有关系。
从现象上看,当 limit n 的 n 值变大时,SQL的执行反倒有可能变快了。
实际上,这是 MySQL 低版本中的 bug #97001,优化器认为排序是个昂贵的操作,因此在执行 order by id limit 这条 SQL 时,为了避免排序,并且认为当 limit n 的 n 很小时,全表扫描可以很快执行完,因此选择使用全表扫描,以避免额外的排序。
针对 MySQL 中 order by limit 或 group by limit 优化器选择错误索引的场景,常见的优化方法有四种:
•强制索引,通过 hint 固化执行计划,比如可以通过 force index 指定使用的索引,但是当条件发生变化时有可能失效,因此生产环境中不建议使用;
•prefer_ordering_index,5.7.33 中已修复该 bug,因此建议新申请时使用 5.7.33 及以上版本,存量低版本建议升级,建议优先使用该方法;
•联合索引,建议在合适的字段加联合索引, 增强可选索引的区分度,让优化器认为这种方式优于有序索引;
•order by (id+0),通过 trick 的方式欺骗优化器,由于 id 上进行了加法这种耗时操作,使优化器认为此时基于全表扫描的会更耗性能,因此选择基于成本选择的索引。
优化方法:order by (id+0)
select ...
ORDER BY goodsInfo.id+0 DESC
LIMIT 0, 20\G执行计划
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: goodsInfo
type: range
possible_keys: idx_org_dc_operator_time,idx_operator_time_network
key: idx_org_dc_operator_time
key_len: 132
ref: NULL
rows: 19024
Extra: Using index condition; Using where; Using filesort
1 row in set (0.00 sec)order by limit 导致索引失效的原因是当查询字段与排序字段不同时,如果使用查询字段的索引,排序字段将无序。优化器认为排序操作昂贵,因此优先使用排序字段的索引。
隐式转换
字段类型不一致或字符集不一致时自动隐式转换将导致索引失效。
SQL
SELECT
id
FROM
base_operating_report
WHERE
yn = 1
and ec_code = 42
order by
inbound_time desc;执行计划,显示索引失效全表扫描
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: base_operating_report
partitions: NULL
type: ALL
possible_keys: idx_ecCode_transferCode
key: NULL
key_len: NULL
ref: NULL
rows: 36524
filtered: 1.00
Extra: Using where; Using filesort
1 row in set, 3 warnings (0.00 sec)查看警告信息,显示隐式转换导致索引失效
mysql> show warnings \G
*************************** 1. row ***************************
Level: Warning
Code: 1739
Message: Cannot use ref access on index 'idx_ecCode_transferCode' due to type or collation conversion on field 'ec_code'
*************************** 2. row ***************************
Level: Warning
Code: 1739
Message: Cannot use range access on index 'idx_ecCode_transferCode' due to type or collation conversion on field 'ec_code'
*************************** 3. row ***************************
Level: Note
Code: 1003
Message: /* select#1 */ select `dms_uat`.`base_operating_report`.`id` AS `id` from `dms_uat`.`base_operating_report` where ((`dms_uat`.`base_operating_report`.`yn` = 1) and (`dms_uat`.`base_operating_report`.`ec_code` = 42)) order by `dms_uat`.`base_operating_report`.`inbound_time` desc
3 rows in set (0.00 sec)表结构
# 索引信息
KEY `idx_ecCode_transferCode` (`ec_code`, `transfer_code`)
# 字段类型
`ec_code` varchar(64) DEFAULT NULL COMMENT '仓库编码'优化方法:将参数中的数值类型转换成字符串
SELECT
id
FROM
base_operating_report
WHERE
yn = 1
and ec_code = '42'
order by
inbound_time desc;执行计划,显示索引生效。
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: base_operating_report
partitions: NULL
type: ref
possible_keys: idx_ecCode_transferCode
key: idx_ecCode_transferCode
key_len: 195
ref: const
rows: 443
filtered: 10.00
Extra: Using index condition; Using where; Using filesort
1 row in set, 1 warning (0.00 sec)隐式转换导致索引失效的原因是字段上有函数,而函数并不一定是单调函数,因此会破坏索引本身的有序性。
IN
SQL
select
IFNULL(count(DISTINCT (awi.id)), 0)
from
tc_attorney_waybill_info awi
where
awi.is_delete = 0
and awi.cur_transit_center_code in (
'2008' , '2052' , '2053' , '2054' , '2055' , '2056' , '2057' , '2058' , '2059' , '2061' , '2064' , '2069' , '2079' , '2084' , '2085' , '2094' , '2171' , '2201' , '2202' , '2207' , '2216' , '2258' , '2292' , '2301' , '2311' , '2324' , '2332' , '2334' , '2336' , '2349' , '2354' , '2355' , '2359' , '2367' , '2369' , '2373' , '2381' , '2385'
)
and awi.send_time >= '2022-10-20 00:00:00'
and awi.send_time <= '2022-11-18 23:59:59'
and awi.split_send_package_times > 0
and awi.first_split_type = 1;
# 执行用时
1 rows in set (1.309 sec)执行计划,显示索引失效全表扫描
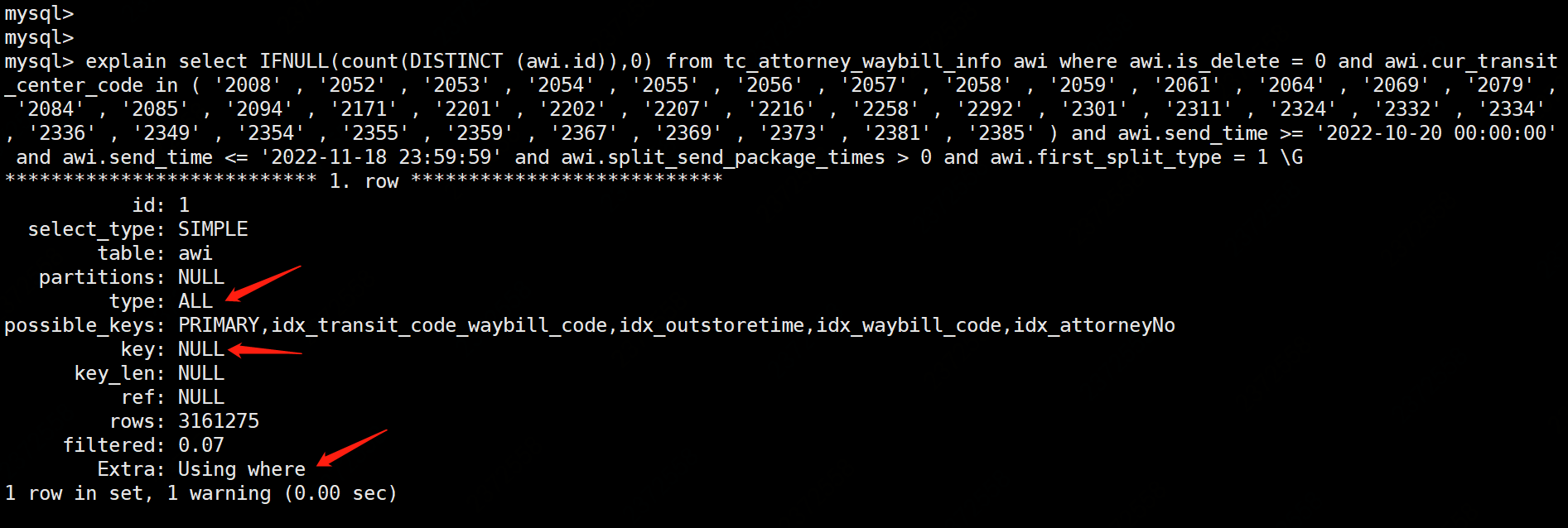 )
)trace,显示当前的索引中全表扫描的成本最低,因此索引失效。
"analyzing_range_alternatives": {
"range_scan_alternatives": [
{
"index": "idx_transit_code_waybill_code",
"ranges": [
"2008 <= cur_transit_center_code <= 2008",
"2052 <= cur_transit_center_code <= 2052",
"2053 <= cur_transit_center_code <= 2053",
"2054 <= cur_transit_center_code <= 2054",
"2055 <= cur_transit_center_code <= 2055",
"2056 <= cur_transit_center_code <= 2056",
"2057 <= cur_transit_center_code <= 2057",
"2058 <= cur_transit_center_code <= 2058",
"2059 <= cur_transit_center_code <= 2059",
"2061 <= cur_transit_center_code <= 2061",
"2064 <= cur_transit_center_code <= 2064",
"2069 <= cur_transit_center_code <= 2069",
"2079 <= cur_transit_center_code <= 2079",
"2084 <= cur_transit_center_code <= 2084",
"2085 <= cur_transit_center_code <= 2085",
"2094 <= cur_transit_center_code <= 2094",
"2171 <= cur_transit_center_code <= 2171",
"2201 <= cur_transit_center_code <= 2201",
"2202 <= cur_transit_center_code <= 2202",
"2207 <= cur_transit_center_code <= 2207",
"2216 <= cur_transit_center_code <= 2216",
"2258 <= cur_transit_center_code <= 2258",
"2292 <= cur_transit_center_code <= 2292",
"2301 <= cur_transit_center_code <= 2301",
"2311 <= cur_transit_center_code <= 2311",
"2324 <= cur_transit_center_code <= 2324",
"2332 <= cur_transit_center_code <= 2332",
"2334 <= cur_transit_center_code <= 2334",
"2336 <= cur_transit_center_code <= 2336",
"2349 <= cur_transit_center_code <= 2349",
"2354 <= cur_transit_center_code <= 2354",
"2355 <= cur_transit_center_code <= 2355",
"2359 <= cur_transit_center_code <= 2359",
"2367 <= cur_transit_center_code <= 2367",
"2369 <= cur_transit_center_code <= 2369",
"2373 <= cur_transit_center_code <= 2373",
"2381 <= cur_transit_center_code <= 2381",
"2385 <= cur_transit_center_code <= 2385"
],
"index_dives_for_eq_ranges": true,
"rowid_ordered": false,
"using_mrr": false,
"index_only": false,
"rows": 1328061,
"cost": 1.59e6,
"chosen": false,
"cause": "cost"
},
{
"index": "idx_outstoretime",
"ranges": [
"0x99ae280000 <= send_time <= 0x99ae657efb"
],
"index_dives_for_eq_ranges": true,
"rowid_ordered": false,
"using_mrr": false,
"index_only": false,
"rows": 1597295,
"cost": 1.92e6,
"chosen": false,
"cause": "cost"
}
],
"analyzing_roworder_intersect": {
"usable": false,
"cause": "too_few_roworder_scans"
}
}
}
}
]
},
{
"considered_execution_plans": [
{
"plan_prefix": [
],
"table": "`tc_attorney_waybill_info` `awi`",
"best_access_path": {
"considered_access_paths": [
{
"rows_to_scan": 3194590,
"access_type": "scan",
"resulting_rows": 3.19e6,
"cost": 677027,
"chosen": true
}
]
},优化方法:
•创建一个更多查询字段的联合索引,减少回表次数;
•缩小查询的时间范围,因为查询的数据量比较大,而且用到的字段比较多,导致回表成本高。
IN 导致索引失效的原因是符合条件的数据量过大导致回表成本高于全表扫描。
分组字段无索引
提数,创建唯一键之前分组查询是否有重复数据。
SQL
select
operate_id,
waybill_code,
private_call_id
from
tos_resource.courier_call_out_record_0
group by
operate_id,
waybill_code,
private_call_id
having
count(*) > 1;执行计划,显示全表扫描
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: courier_call_out_record_0
partitions: NULL
type: ALL
possible_keys: NULL
key: NULL
key_len: NULL
ref: NULL
rows: 1470107
filtered: 100.00
Extra: Using temporary; Using filesort
1 row in set, 1 warning (0.01 sec)分组字段无联合索引,有两个索引覆盖三个分组字段,因此索引无法使用。
KEY `courier_call_out_record_0_operate_id_IDX` (`operate_id`,`waybill_code`),
KEY `courier_call_out_recourd_0_waybill_code` (`waybill_code`)优化方法:给分组字段创建联合索引
alter table courier_call_out_record_0
add index `courier_call_out_record_0_composite_key` (`operate_id`,`waybill_code`,`private_call_id`);执行计划
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: courier_call_out_record_0
partitions: NULL
type: index
possible_keys: courier_call_out_record_0_composite_key
key: courier_call_out_record_0_composite_key
key_len: 907
ref: NULL
rows: 2230391
filtered: 100.00
Extra: Using index
1 row in set, 1 warning (0.00 sec)分组字段无联合索引导致全表扫描的原因是分组时需要先排序,因此只有当分组字段在同一个索引中时才可以保证有序。
索引的优缺点
索引的代价
通过以上分析可以发现索引不是万能的,实际上有时候索引甚至会有副作用。
创建索引的代价可以分为两类:
•空间代价,索引需要占用磁盘空间,并且删除索引并不会立即释放空间,因此无法通过删除索引的方式降低磁盘使用率;
•时间代价,有的时候会发现创建索引后导致写入变慢,原因是每次数据写入后还需要对该记录按照索引排序。因此经常更新的列不建议创建索引。
可见,索引的优点是可以加快查询速度,缺点是占用内存与磁盘空间,同时减慢了插入与更新操作的速度。
因此,B+ Tree 适用于读多写少的业务场景,相对应的 LSM-Tree 适用于写多读少的业务场景,原因是每次数据写入对应一条日志追加写入磁盘文件,用顺序 IO 代替了随机 IO。
索引使用的建议
关于索引的使用有以下几点建议:
•建议给区分度高的字段创建索引;
•建议删除冗余索引,否则优化器可能使用 index_merge 导致选择到错误的索引;
•不建议使用强制索引,比如当数据量或统计信息发生变化时,强制索引不一定最优。
下面测试下与索引相关的两个操作:
•如果 SQL 中强制指定已删除的索引,SQL 执行会报错吗?
•如果删除字段,索引也会自动删除吗?
准备数据
mysql> create table t_index_drop like t_index;
Query OK, 0 rows affected (0.02 sec)
mysql> show create table t_index_drop \G
*************************** 1. row ***************************
Table: t_index_drop
Create Table: CREATE TABLE `t_index_drop` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`age` int(11) DEFAULT '0',
`name` varchar(10) DEFAULT '',
PRIMARY KEY (`id`),
KEY `idx_age_name` (`age`,`name`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8
1 row in set (0.00 sec)如果 SQL 中强制指定已删除的索引,SQL 将直接报错,生产环境中遇到过相关案例。
mysql> alter table t_index_drop drop index idx_age_name;
Query OK, 0 rows affected (0.01 sec)
Records: 0 Duplicates: 0 Warnings: 0
mysql> select * from t_index_drop force index(idx_age_name);
ERROR 1176 (42000): Key 'idx_age_name' doesn't exist in table 't_index_drop'如果删除字段,索引也会自动删除。
mysql> alter table t_index_drop add index idx_age(age);
Query OK, 0 rows affected (0.02 sec)
Records: 0 Duplicates: 0 Warnings: 0
mysql> show create table t_index_drop \G
*************************** 1. row ***************************
Table: t_index_drop
Create Table: CREATE TABLE `t_index_drop` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`age` int(11) DEFAULT '0',
`name` varchar(10) DEFAULT '',
PRIMARY KEY (`id`),
KEY `idx_age_name` (`age`,`name`),
KEY `idx_age` (`age`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8
1 row in set (0.00 sec)
mysql> alter table t_index_drop drop column age;
Query OK, 0 rows affected (0.02 sec)
Records: 0 Duplicates: 0 Warnings: 0
mysql> show create table t_index_drop \G
*************************** 1. row ***************************
Table: t_index_drop
Create Table: CREATE TABLE `t_index_drop` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(10) DEFAULT '',
PRIMARY KEY (`id`),
KEY `idx_age_name` (`name`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8
1 row in set (0.00 sec)基于优化器选择索引有可能选错索引导致性能下降,而使用强制索引可能导致 SQL 执行直接报错。
结论
慢SQL的优化原则是减少数据访问量与减少计算操作,其中索引是数据库中用来提升性能的最常用工具。
索引是一种用于快速查找的一种排序的数据结构,基于以空间换时间的思想实现。
MySQL 中由存储引擎层实现索引,InnoDB 存储引擎中基于 B+ 树实现,因此每个索引都是一棵 B+ 树。
索引用于组织页,页用于组织行记录。
其中:
•每个数据页中的记录会按照主键值从小到大的顺序组成一个单向链表,依赖行记录的Page Header中next_record属性实现,其中保存下一条记录相对于本条记录的地址偏移量;
•数据页之间组成一个双向链表,依赖数据页的File Header中FIL_PAGE_PREV和FIL_PAGE_NEXT属性实现,其中保存本页的上一个和下一个页的页号。
查询操作可以分为以下两步:
•定位到记录所在的页
•从所在的页中定位到具体的记录
对比没有索引与有索引时查询操作的性能差异:
•没有索引时每次查询都是全表扫描;
•有索引时从 B+ 树的根节点出发,一层一层向下搜索目录项,由于上层节点保存的都是下层节点的最小值,因此可以快速定位到数据可能所在的页。
关于索引失效的场景总结以下两点:
•索引的本质是有序的数据结构,因此破坏索引有序性的操作都有可能导致索引失效或部分生效;
•回表成本较高,因此优先使用覆盖索引,必须要回表时也需要控制回表的记录数,从而降低索引失效的风险。
参考教程
•《MySQL 是怎样运行的:从根儿上理解 MySQL》
•MySQL工具之innodb_ruby:探究InnoDB存储结构的利器
•你管这破玩意叫B+树?
作者:京东物流 张凯
来源:京东云开发者社区




