
作为解决方案厂商,MapGis是如何实现分布式大数据存储的呢?
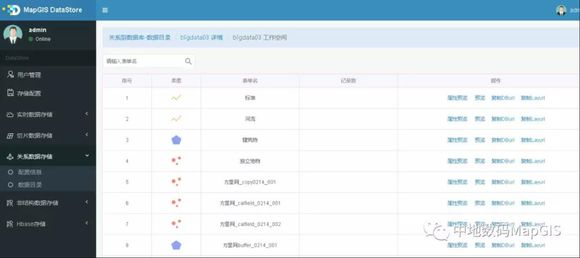
MapGIS在传统关系型空间数据库引擎MapGIS SDE的基础之上,针对地理大数据的特点,构建了MapGIS DataStore分布式数据库引擎,其集成整合了多种开源分布式数据库和文件系统,分别用来存储和管理关系型数据,切片型数据,实时型数据和非结构化数据,形成针对地理大数据应用场景相关的解决方案。
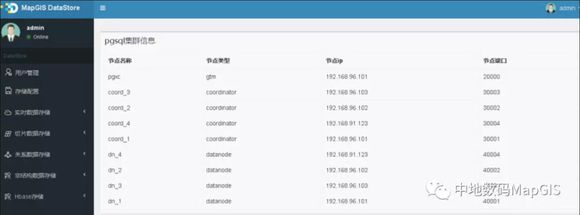
传统关系型数据库在存储海量矢量数据时,只能部署在单个服务器上,无法承受海量数据的存储和查询请求,尤其是对于对象个数超过千万条的复杂空间数据,其性能会急剧下降。PostgreSQL是一个功能强大的开源关系型数据库,其具备矢量点线面的高效存储和查询的的能力,并且可以构建分布式的数据库集群。MapGIS将PostgreSQL集成和融入到MapGIS DataStore中,将其作为海量矢量数据的存储引擎,可实现海量矢量数据的分布式存储,将传统数据库的复杂表进行数据分块分节点,同时可控制每个存储节点的数据量在千万左右,在此基础之上利用空间索引分区技术实现快速查询,最终有效解决传统关系型数据存在的瓶颈问题。

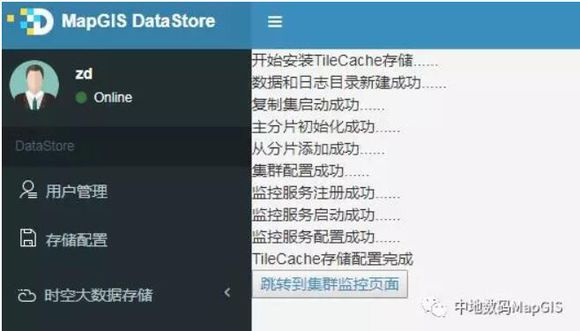
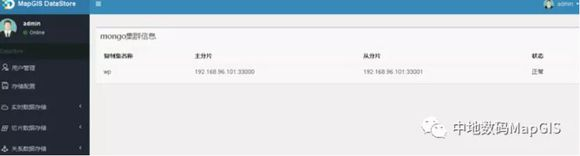
对于栅格数据,传统关系型数据库存储海量切片数据时,存在硬盘I/O读写瓶颈,另外为了维护数据的一致性,也会牺牲很大的读写效率,从而导致切片数据的并发读取速度无法满足应用需求。MongoDB是一个基于分布式存储的NoSQL型数据库,其介于关系型数据库和非关系型数据库之间。MapGIS集成MongoDB并且融入到MapGIS DataStore中,将其作为切片数据的存储引擎,实现亿级切片数据的存储,可方便的复制迁移以及秒级的并发访问,实现了切片数据的高性能存储和读取,有效解决切片数据的高并发读取瓶颈。
问:实时数据的存储和分析存在哪些问题?它和传统的GIS数据有什么区别?
对象存储方式。Elasticsearch。
















