推荐
专栏
教程
课程
飞鹅
本次共找到2932条
python爬虫
相关的信息
Irene181
•
4年前
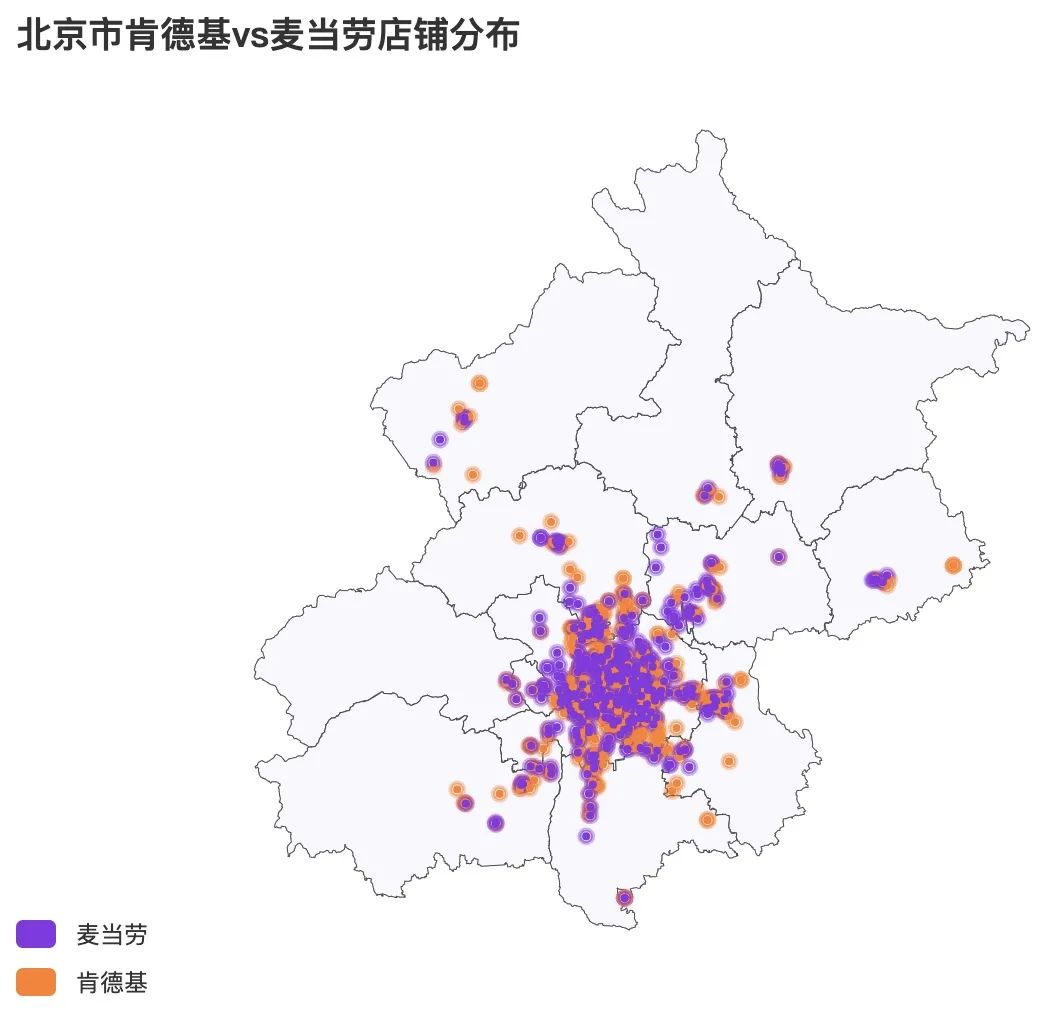
只要两步,用Python将地址标记在地图上!
大家好,在之前的文章中,很多读者私信对如何将商家地址标记到地图上感兴趣👇本文就将讲解,给你一个地址,如何用Python进行可视化,只需要两步:将地址转成经纬度根据经纬度在地图上标记点一、将地址转成经纬度首先我们需要将地理位置转成经纬度这种统一格式,方便代码去识别。完成这一个需求可以使用爬虫通过在线的经纬度转换网站来实现,也可以使用
Wesley13
•
4年前
java 爬虫抓取数据一个简单例子
java爬虫抓取数据一个简单例子。用来备份用的。packagecom.util;importjava.io.BufferedReader;importjava.io.IOException;importjava.io.InputStream;importjava.io.Inpu
黎明之道
•
4年前
Python编程基础(快速入门必看
Python编程基础一、Python语言基本语法Python是一
Karen110
•
4年前
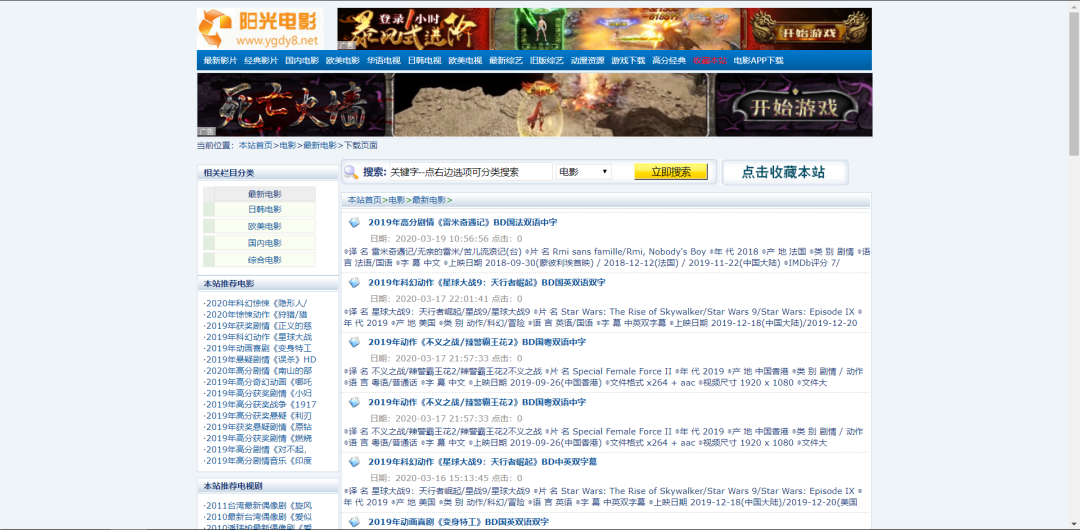
一篇文章教会你利用Python网络爬虫获取电影天堂视频下载链接
【一、项目背景】相信大家都有一种头疼的体验,要下载电影特别费劲,对吧?要一部一部的下载,而且不能直观的知道最近电影更新的状态。今天小编以电影天堂为例,带大家更直观的去看自己喜欢的电影,并且下载下来。【二、项目准备】首先我们第一步我们要安装一个Pycharm的软件。Pycharm软件安装可以看这篇教程:。电影天堂网的网址:https://ww
Stella981
•
4年前
30 行 Python 代码爬取英雄联盟全英雄皮肤
距离上次写爬虫文章已经过了许久了,之前写过一篇20行Python代码爬取王者荣耀全英雄皮肤 \1\,反响强烈,其中有很多同学希望我再写一篇针对英雄联盟官网的皮肤爬取,但苦于事情繁多,便一拖再拖,一直拖到了现在,那么本篇文章我们就一起来学习一下如何爬取英雄联盟全英雄皮肤。爬取代码非常简单,从上到下可能只需要写30行左右就能完成,但重要的是分析过程,在此
Stella981
•
4年前
Python3与Python2的差异
基于python3浅谈python3与python2的差异。由于现今主流Python3,但是之前用Python2做的项目,还得维护,所以作为python工作者,不免要了解其中差异,其中,Python2有ASCIIstr()类型,unicode()是单独的,不是byte类型。而Python3.X源码文件默认使用utf8编码,以及一个
Stella981
•
4年前
PHP用Swoole实现爬虫(一)
基本概念网络爬虫网络爬虫(又被称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。另外一些不常使用的名字还有蚂蚁、自动索引、模拟程序或者蠕虫。swoolePHP的异步、并行、高性能网络通信引擎,使用纯C语言编写,提供了PHP语
小白学大数据
•
3年前
一份解决爬虫错误问题指南
在互联网上进行自动数据采集已是互联网从业者的常规操作,爬虫程序想要长期稳定地进行数据采集,都会使用到爬虫代理来避免目标网站的IP访问限制。在数据采集过程中难免会遇到各种各样的问题,若想要想要快速分析数据采集过程中的问题,我们该怎么做呢?其实可以通过HTTP
小白学大数据
•
2年前
python如何分布式和高并发爬取电商数据
随着互联网的发展和数据量的不断增加,网络爬虫已经成为了一项非常重要的工作。爬虫技术可以帮助人们自动地从互联网上获取大量数据,并且这些数据可以应用于各种领域,如搜索引擎、数据分析和预测等。然而,在实际应用中,我们面临的一大难题就是如何高效地爬取大量数据。分布
小白学大数据
•
2年前
python爬取数据中的headers和代理IP问题
爬虫的主要爬取方式之一是聚焦爬虫,也就是说,爬取某一个特定网站或者具有特定内容的网站,而一般比较大的有价值的网站都会有反爬策略,其中常见的反爬策略是网站根据来访者的身份判定是否予以放行。对来访者身份的判定一般基于headers里的userAgent值,每一
1
•••
29
30
31
•••
294