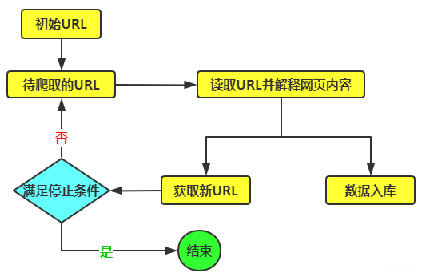
爬虫的主要爬取方式之一是聚焦爬虫,也就是说,爬取某一个特定网站或者具有特定内容的网站,而一般比较大的有价值的网站都会有反爬策略,其中常见的反爬策略是网站根据来访者的身份判定是否予以放行。 对来访者身份的判定一般基于headers里的user-Agent值,每一种浏览器访问网站的user-Agent都是不同的,因此,爬虫需要伪装成浏览器,并且在爬取的过程中自动切换伪装,从而防止网站的封杀。可以通过一些爬虫库调用随机返回一个headers(User-Agent)
import requests
ua = UserAgent() # 实例化,需要联网但是网站不太稳定-可能耗时会长一些
print(ua.random) # 随机产生
headers = {
'User-Agent': ua.random # 伪装
}
# 请求
if __name__ == '__main__':
url = 'https://www.baidu.com/'
response = requests.get(url, headers=headers ,proxies={"http":"117.136.27.43"})
print(response.status_code)
还有就是访问IP的判别,在进行Python爬虫程序开发时,如果频繁地访问同一网站的情况下,网站服务器可能会把该IP地址列入黑名单,限制其访问权限。此时,使用IP代理技术可以有效避免这种限制,保证爬虫程序的稳定性。使用IP代理技术还有其他的优点,比如增强隐私保护、提高数据访问速度、降低目标网站的压力等等。总之,IP代理技术已经成为了Python爬虫程序中不可或缺的一部分。
Python提供了丰富的第三方库,可以帮助我们实现IP代理功能。其中最常用的是requests库和urllib库。以下是使用requests库实现IP代理的示例代码:
``` #! -*- encoding:utf-8 -*-
import requests
import random
# 要访问的目标页面
targetUrl = "http://httpbin.org/ip"
# 要访问的目标HTTPS页面
# targetUrl = "https://httpbin.org/ip"
# 代理服务器(产品官网 www.16yun.cn)
proxyHost = "t.16yun.cn"
proxyPort = "31111"
# 代理验证信息
proxyUser = "username"
proxyPass = "password"
proxyMeta = "http://%(user)s:%(pass)s@%(host)s:%(port)s" % {
"host" : proxyHost,
"port" : proxyPort,
"user" : proxyUser,
"pass" : proxyPass,
}
# 设置 http和https访问都是用HTTP代理
proxies = {
"http" : proxyMeta,
"https" : proxyMeta,
}
# 设置IP切换头
tunnel = random.randint(1,10000)
headers = {"Proxy-Tunnel": str(tunnel)}
resp = requests.get(targetUrl, proxies=proxies, headers=headers)
print resp.status_code
print resp.text