推荐
专栏
教程
课程
飞鹅
本次共找到2932条
python爬虫
相关的信息
samzhangjy
•
4年前
知乎文章转Markdown的艰辛历程
好吧,让我们从头说起。众所不周知,我有了我自己的博客,于是就想把我的知乎内容同步到博客上去(目前还空空如也)。但是,出于能犯懒就犯懒的原则,我决定做一个自动化程序,自动将知乎上的文章转换成Markdown食用。嗯……结果还挺满意的,就是好像时间耗费的长了一点(三个月啊,中间搁置了两个月零30天)。。总之,我Python爬虫,成功构建了一个知乎2MD全自动转换
Karen110
•
4年前
手把手教你用Python爬取百度搜索结果并保存
一、前言大家好,我是崔艳飞。众所周知,百度上直接搜索关键字会出来一大堆东西,时常还会伴随有广告出现,不小心就点进去了,还得花时间退出来,有些费劲。最近群里有个小伙伴提出一个需求,需要获取百度上关于粮食的相关讲话文章标题和链接。正好小编最近在学习爬虫,就想着拿这个需求来练练手。我们都知道,对Python来说,有大量可用的库,实现起来并不难,动手吧。二、项目
Immortal
•
4年前
MongoDB的安装与基本操作
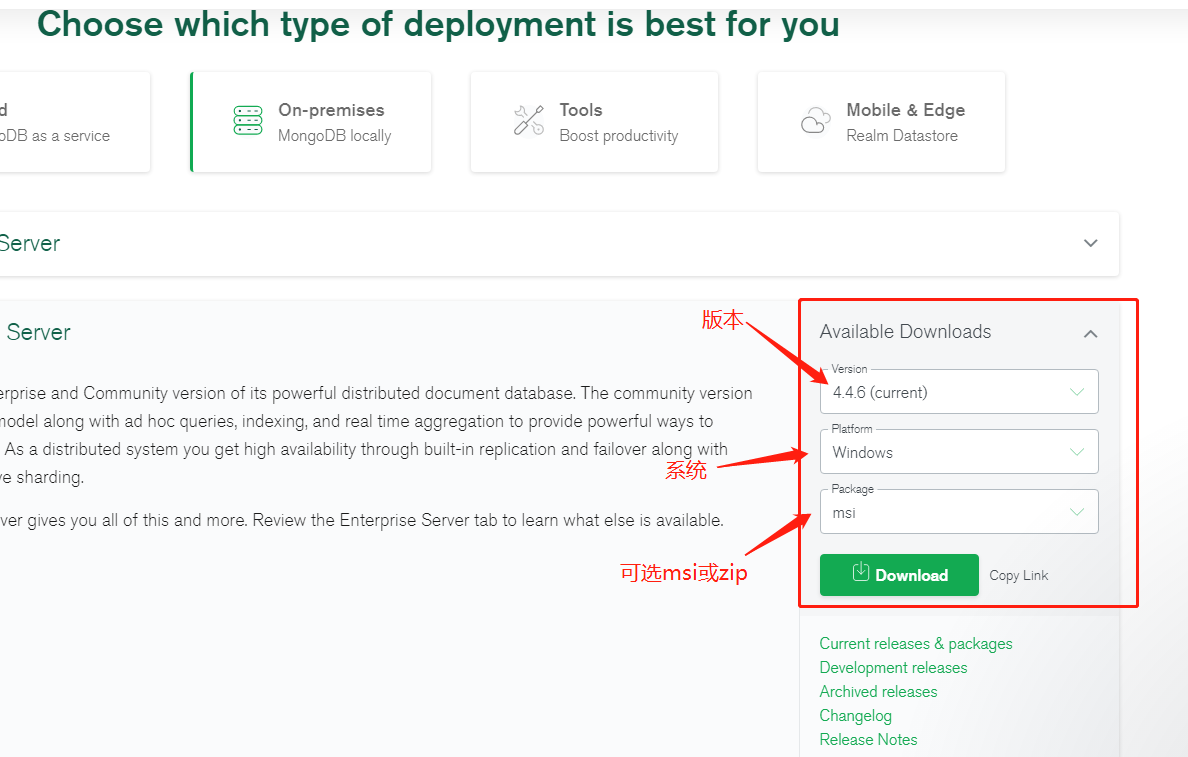
最近刚好在学习爬虫,了解到MongoDB非常适合JSON数据存储,受到广大爬虫程序员的青睐,故学习之。一、安装MongoDB官网:进入官网后选择你需要的版本,系统,已及你想要的安装包(可选msi或zip,这里我使用msi,双击安装,简单!):::warning在MongoDB2.2版本后已经不再支持WindowsXP系统。最新版本也
Stella981
•
4年前
CentOS升级Python到2.7版本
查看python的版本pythonVPython2.4.31.先安装GCCyumyinstallgcc2.下载Python2.7.2wgethttp://python.org/ftp/python/2.7.2/Python2.7.2.tar.bz23.解压Python2.7.2
Stella981
•
4年前
GuozhongCrawler实现一个完整爬虫
经过上一节开发环境搭建中的百度新闻的爬虫例子,相信大家已经对GuozhongCrawler简洁的API产生浓厚兴趣了。不过这个还不算一个入门例子。只是完成了简单的下载和解析。现在我们来完成一个比较完整的爬虫吧。 为了体现GuozhongCrawler适应业务灵活性。我们以抓取西刺代理(http://www.xici.net.co/nn/1)
小白学大数据
•
1年前
错误处理在网络爬虫开发中的重要性:Perl示例 引言
错误处理的必要性在网络爬虫的开发过程中,可能会遇到多种错误,包括但不限于:网络连接问题服务器错误(如404或500错误)目标网站结构变化超时问题权限问题错误处理机制可以确保在遇到这些问题时,爬虫能够优雅地处理异常情况,记录错误信息,并在可能的情况下恢复执行
小白学大数据
•
1年前
建筑业数据挖掘:Scala爬虫在大数据分析中的作用
数据的挖掘和分析对于市场趋势预测、资源配置优化、风险管理等方面具有重要意义,特别是在建筑业这一传统行业中。Scala,作为一种强大的多范式编程语言,提供了丰富的库和框架,使其成为开发高效爬虫的理想选择。本文将探讨Scala爬虫在建筑业大数据分析中的作用,并
小白学大数据
•
1年前
如何在Java爬虫中设置动态延迟以避免API限制
一、动态延迟与代理服务器的重要性1.动态延迟的重要性动态延迟是指根据爬虫运行时的环境和API的响应情况,动态调整请求之间的间隔时间。与静态延迟(固定时间间隔)相比,动态延迟能够更灵活地应对API的限制策略,同时最大化爬虫的效率。动态延迟的重要性体现在以下几
小白学大数据
•
4个月前
增量爬取策略:如何持续监控贝壳网最新成交数据
一、增量爬取的核心思想与优势在深入代码之前,我们首先要理解增量爬取的核心理念。与传统的全量爬虫(每次运行都重新抓取所有数据)不同,增量爬虫只抓取自上次爬取以来新增或发生变化的数据。其核心优势不言而喻:极大提升效率:网络请求和数据处理的量级大幅下降,节省带宽
1
•••
28
29
30
•••
294