推荐
专栏
教程
课程
飞鹅
本次共找到2708条
软件开发模型
相关的信息
Stella981
•
4年前
MapReduce编程模型和计算框架架构原理
Hadoop解决大规模数据分布式计算的方案是MapReduce。MapReduce既是一个编程模型,又是一个计算框架。也就是说,开发人员必须基于MapReduce编程模型进行编程开发,然后将程序通过MapReduce计算框架分发到Hadoop集群中运行。我们先看一下作为编程模型的MapReduce。MapReduce编程模型
Stella981
•
4年前
JavaScript_DOM中的Model与Object
什么是Model 对象模型即创建对象时浏览器会将HTML文档抽象成树模型,比如一个节点对象就是模型中一个节点的实例,模型中相邻节点之间存在着关系,关系即父子、兄弟,每一个节单对象都保存着指示其他关系节点的“指针”,因此在操作节点对象时我们根据Model的定义可以在头脑里抽象出一个HTML的模型,作为操作节点的导航。下面是一个示例:!
天翼云开发者社区
•
2年前
大语言模型微调数据竞赛,冠军!
近日,天池FTDataRanker竞赛落下帷幕,天翼云智能边缘事业部AI团队(后称天翼云AI团队)凭借在大语言模型(LLM)训练数据增强方面的卓越研究,荣获大语言模型微调数据竞赛——7B模型赛道冠军。
taskbuilder
•
1年前
创建学员信息数据模型
3、创建学员信息数据模型使用TaskBuilder开发应用的第一步就是先创建数据模型,数据模型是用来存储应用数据结构的文件,可以定义各项业务数据有哪些字段,每个字段的数据类型、长度、是否为空等,TaskBuilder提供了一个可视化的数据模型设计器,可以不
飞速低代码平台
•
1年前
飞速搭震撼上线 开启软件开发智能化新篇章
近日,飞速低代码开发平台迎来了一项具有里程碑意义的重大更新——“飞速搭”正式上线。飞速搭通过深度融合前沿的人工智能技术,实现了从需求文档到应用发布的无缝衔接,一键智能生成应用,为软件开发领域带来了全新的突破和变革。“飞速搭”的实现路径高效而清晰。用户只需将
近屿智能
•
11个月前
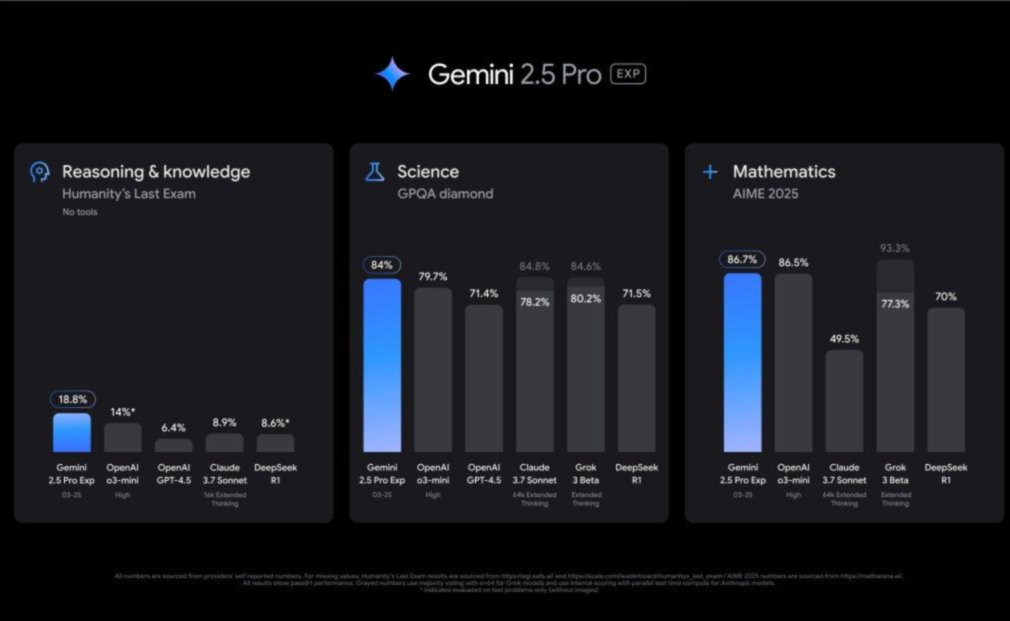
谷歌最强模型 Gemini 2.5 Pro 发布,近屿智能带你学AI大模型
近日,谷歌宣布推出“最智能的AI模型”Gemini2.5系列,实验版Gemini2.5Pro是该系列上线的首款推理模型。这个模型专为复杂任务打造,推理能力强大,一经诞生就横扫各大榜单、拿下各类TOP1,还创下了历史上最大分数飞跃纪录。目前,该模型已在Goo
京东云开发者
•
3个月前
JDD Oxygen智能零售论坛 | 《大模型时代的广告营销变革与实践》
核心观点1.通用大模型想解决营销领域问题需向垂类模型转型。“全才”通用大模型难覆盖广告营销全流程,需升级为“懂营销”的垂直模型,实现从“知道”到“落地执行”的三维跨越。2.广告智能体破解传统投放门槛高效果不稳定难题。把简单留给客户,让复杂交给AI。传统投放
linbojue
•
3星期前
box-sizing: border-box 详解
🎯核心作用boxsizing:borderbox改变了CSS盒模型的计算方式,让元素的宽度和高度包含内边距(padding)和边框(border),而不是仅仅内容区域。📊盒模型对比默认盒模型(contentbox)css体验AI代码助手代码解读复制代码
数据堂
•
2年前
大模型数据集:探索新维度,引领AI变革
一、引言在人工智能(AI)的快速发展中,大型预训练模型如GPT、BERT等已经取得了令人瞩目的成果。这些大模型的背后,离不开规模庞大、质量优良的数据集的支撑。本文将从不同的角度来探讨大模型数据集的新维度,以及它们如何引领AI的变革。二、大模型数据集的新维度
1
•••
15
16
17
•••
271