推荐
专栏
教程
课程
飞鹅
本次共找到8886条
聚合数据
相关的信息
CuterCorley
•
4年前
Python数据分析实战(2)使用Pandas进行数据分析
一、Pandas的使用1.Pandas介绍Pandas的主要应用包括:数据读取数据集成透视表数据聚合与分组运算分段统计数据可视化Pandas的使用很灵活,最重要的两个数据类型是DataFrame和Series。对DataFrame最直观的理解是把它当成一个Excel表格文件,如下:索引是从0开始的,也
Karen110
•
4年前
一篇文章带你了解Django ORM操作(高端篇)
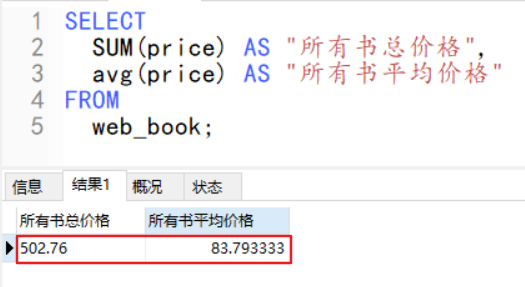
前言上次两篇基本学完的DjangoORM各种操作,怎么查,各种查。感兴趣的小伙伴可以戳这两篇文章学习下,、。但是还是遗留了一些技能。,再来瞅瞅吧!查询聚合操作聚合操作,不要被名字吓到了,通常用在筛选完一些数据之后,求一下平均值了,什么的。例如:求所有书的总价格和平均价格原生sqlSELECTSUM(price)AS"所有书总价格",a
Wesley13
•
4年前
JDK8之lambda表达式
/JDK8Stream特性Createdbychengbxon2018/5/27.Java8中的Stream是对集合(Collection)对象功能的增强,它专注于对集合对象进行各种非常便利、高效的聚合操作(aggregateoperation),或者大批量数据操
Stella981
•
4年前
Flink 系例 之 MaxBy
maxBy聚合:获取一组数据流算子中最大的记录行(和max的区别,max是返回计算字段的最大值)示例环境java.version:1.8.xflink.version:1.11.1 示例数据源(项目码云下载)Flink系例之搭建开发环境与数据(https://my.oschina.net/u/437309
Stella981
•
4年前
Hadoop学习之路(二十三)MapReduce中的shuffle详解
概述1、MapReduce中,mapper阶段处理的数据如何传递给reducer阶段,是MapReduce框架中最关键的一个流程,这个流程就叫Shuffle2、Shuffle:数据混洗——(核心机制:数据分区,排序,局部聚合,缓存,拉取,再合并排序)3、具体来说:就是将MapTask输出的处理结果数据,按照Par
Wesley13
•
4年前
Oracle 的开窗函数 rank,dense_rank,row_number
1、开窗函数和分组函数的区别分组函数是指按照某列或者某些列分组后进行某种计算,比如计数,求和等聚合函数进行计算。开窗函数是指基于某列或某些列让数据有序,数据行数和原始数据数相同,依然能曾现个体数据的原貌。事例数据createtablestudent\_scores(stu\_idvarchar2(10),学号stu\_n
Stella981
•
4年前
Elasticsearch入门之从零开始安装ik分词器
!(https://oscimg.oschina.net/oscnet/0197ba2bf7a6cba3bb1366fe28c985c0cba.jpg)起因需要在ES中使用聚合进行统计分析,但是聚合字段值为中文,ES的默认分词器对于中文支持非常不友好:会把完整的中文词语拆分为一系列独立的汉字进行聚合,显然这并不是我的初衷。我们来看个实例:
小白学大数据
•
1年前
Rust中的数据抓取:代理和scraper的协同工作
一、数据抓取的基本概念数据抓取,又称网络爬虫或网页爬虫,是一种自动从互联网上提取信息的程序。这些信息可以是文本、图片、音频、视频等,用于数据分析、市场研究或内容聚合。为什么选择Rust进行数据抓取?●性能:Rust的编译速度和运行效率极高。●内存安全:Ru
小白学大数据
•
1年前
使用Panther进行爬虫时,如何优雅地处理登录和Cookies?
前言在互联网数据采集领域,网络爬虫扮演着至关重要的角色。它们能够自动化地从网站获取数据,为数据分析、内容聚合、市场研究等提供原材料。然而,许多网站通过登录和Cookies机制来保护其数据,这为爬虫开发者提出了新的挑战。SymfonyPanther作为一个现
京东云开发者
•
1年前
Elasticearch索引mapping写入、查看、修改
作者:京东物流陈晓娟一、ESElasticsearch是一个流行的开源搜索引擎,它可以将大量数据快速存储和检索。Elasticsearch还提供了强大的实时分析和聚合查询功能,数据模式更加灵活。它不需要预先定义固定的数据结构,可以随时添加或修改数据字段,而
1
2
3
4
•••
889