推荐
专栏
教程
课程
飞鹅
本次共找到2376条
网络爬虫
相关的信息
Python进阶者
•
3年前
Jsrpc学习——网易云热评加密函数逆向
大家好,我是皮皮。前几天给大家分享jsrpc的介绍篇,Python网络爬虫之js逆向之远程调用(rpc)免去抠代码补环境简介,感兴趣的小伙伴可以戳此文前往。今天给大家来个jsrpc实战教程,Jsrpc学习——Cookie变化的网站破解教程,让大家继续加深对jsrpc的理解和认识。下面是具体操作过程,不懂的小伙伴可以私我。1、因为网易云音乐热评的加密并不在co
浅梦一笑
•
4年前
多人说Python简单,但是如何入门Python并精通?
一般而言,Python几个月就可以开始使用了。假如你几个月没入门,那肯定是方法不对,或者是偷懒.我在公众号里有一篇文章详细写了“初学者别上爬虫”,爬虫虽然很有趣,但不适合于小白用户。以下是2点:多人说Python简单,但是如何入门Python并精通?Python再简单再通俗,它也是一门语言,掌握一门语言绝非一朝一夕,我个人不推荐初学者上岸学习爬虫,我举一个很
Aidan075
•
4年前
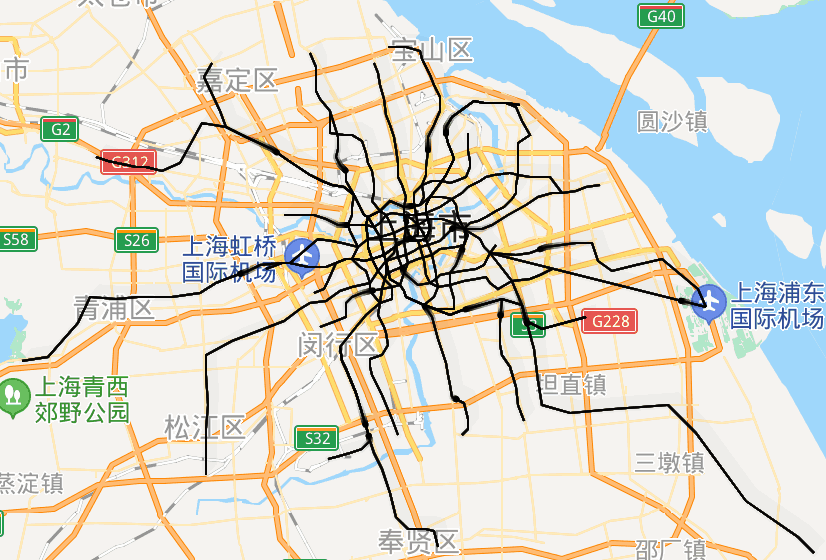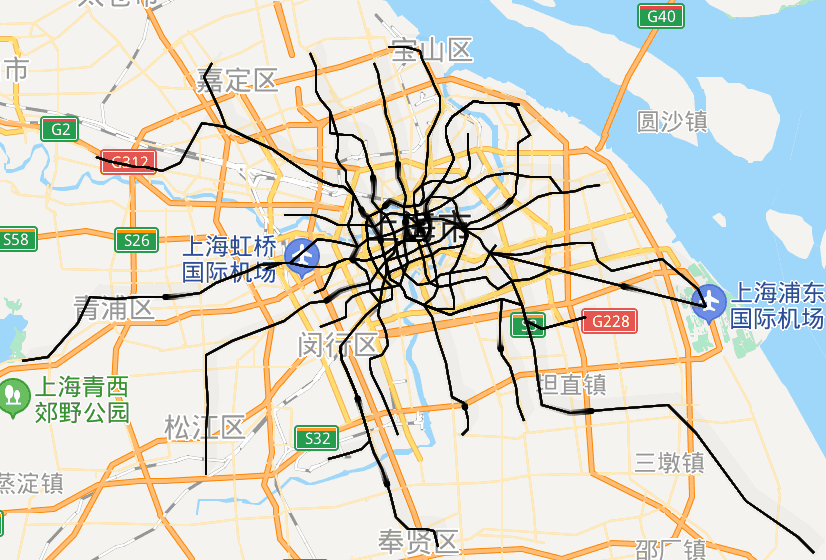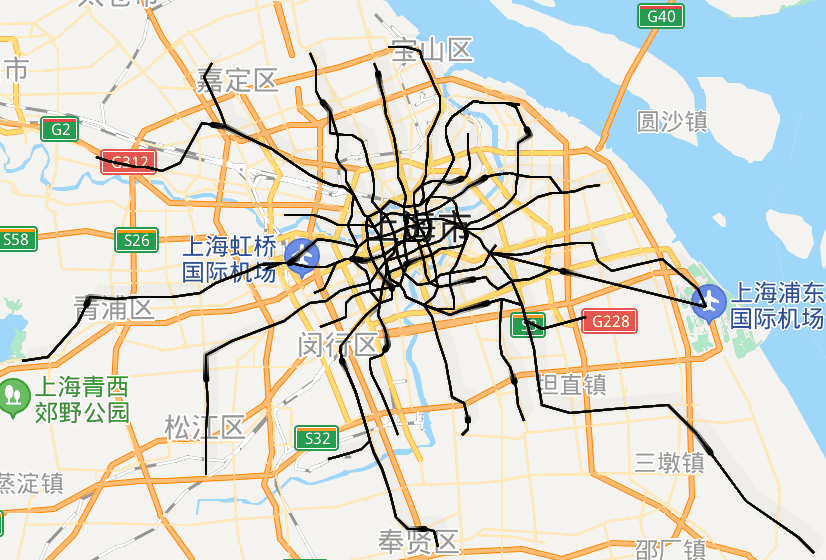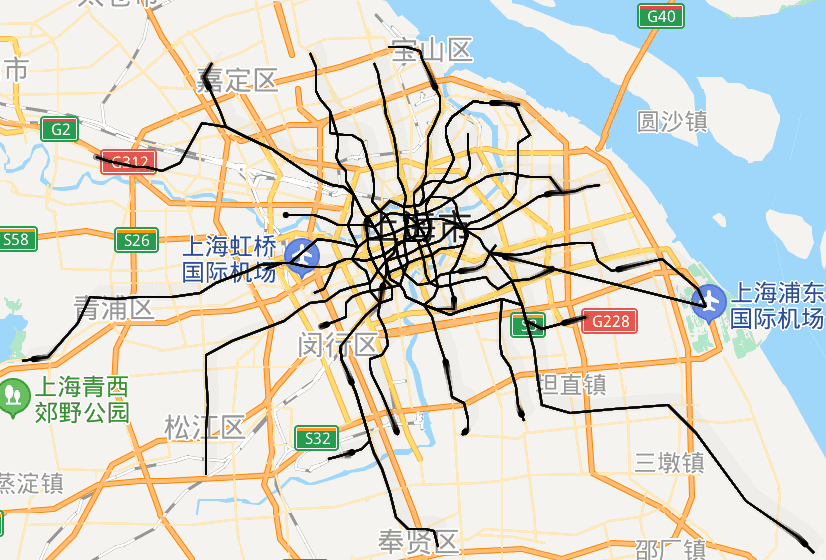
太酷炫了!我用Python画出了北上广深的地铁路线动态图
大家好,我是小五🐶今天教大家用python制作地铁线路动态图,这可能是全网最全最详细的教程了。坐标点的采集小五之前做过类似的地理可视化,不过都是使用网络上收集到的json数据。但很多数据其实是过时的,甚至是错误/不全的。所以我们最好还是要自己动手,丰衣足食(爬虫大法好)。打开高德地图的地铁网页,http://map.amap.com/subway/ind
python知道
•
4年前
怎么学python,学习python的正确姿势
Python是一门相对来说比较简单的编程语言,自学是非常轻松的。首先得明白python有哪些发展方向需要了解这个这门语言而不是听说这个高薪资容易学习最好的学习状态就是出于兴趣兴趣是最好的老师当然对钱感兴趣也是可以的。一、人工智能二、大数据三、网络爬虫工程师四、Pythonweb全栈工程师五、Python自动化运维六、Python自动化测试再来说
Stella981
•
4年前
HtmlExtractor 1.1 发布,网页信息抽取组件
HtmlExtractor(https://www.oschina.net/action/GoToLink?urlhttps%3A%2F%2Fgithub.com%2Fysc%2FHtmlExtractor)是一个Java实现的基于模板的网页结构化信息精准抽取组件,本身并不包含爬虫功能,但可被爬虫或其他程序调用以便更精准地对网页结构化信息进行抽取。
Stella981
•
4年前
Scrapy项目之User timeout caused connection failure(异常记录)
Windows10家庭中文版,Python3.6.4,Scrapy1.5.0,提示:此文存在问题,真正测试, 请勿阅读,_071414:26更新:_经过两个多小时的测试,发现此问题的原因是 昨天编写爬虫程序后,给爬虫程序添加了下面的属性:download\_timeout20此属性的解释:The
Stella981
•
4年前
CNKI小爬虫(Python)
CNKI作为国文最大的数据库,虽然下载文章是需要登陆的,但是只除了全文外还有很多有价值的信息,包括文章名,作者,基金还有摘要,都可以作为重要数据进行匿名爬取,先写个简单的出来,之后有空再建个关联的数据吧因为闲放在一个文件中太乱所以把他们分开两个文件,一个为主文件Crawl\_cnki.py,一个为参数文件Parameters.py。文件包:https:
Stella981
•
4年前
Python爬虫知识点全面梳理
学任何一门技术,都应该带着目标去学习,目标就像一座灯塔,指引你前进,很多人学着学着就学放弃了,很大部分原因是没有明确目标,所以,在你准备学爬虫前,先问问自己为什么要学习爬虫。有些人是为了一份工作,有些人是为了好玩,也有些人是为了实现某个黑科技功能。不过肯定的是,学会了爬虫,能给你的工作提供很多便利。作为零基础小白,大体上可分为三个阶段去实现,第一阶段是
小白学大数据
•
3年前
python爬取数据的关键技术
大数据时代,数据越来越具有价值了,没有数据寸步难行,有了数据好好利用,可以在诸多领域干很多事。从互联网上爬来自己想要的数据,是数据的一个重要来源,所以,爬虫工程师现在是一个非常吃香的职位,这个职业能带来稳定的、高效的和实时的数据。爬虫可以很快的入门,但要做的真正大神,还必须不断实践。因为,一旦真正爬数据的时候就会出现各种问题,因为爬虫本质是一种对抗性的工作,
Python进阶者
•
3年前
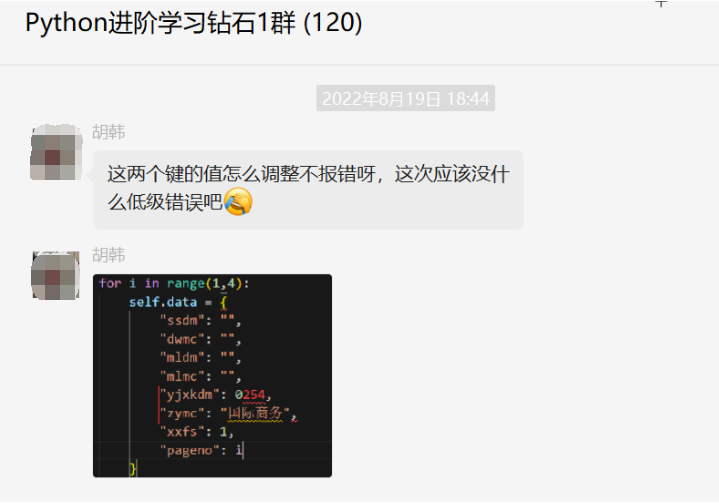
这两个键的值怎么调整不报错呀?
大家好,我是皮皮。一、前言前几天在Python钻石交流群【胡韩】问了一个Python网络爬虫的问题,提问截图如下:二、实现过程这里【薄荷味的鱼】、【🌑中华小矿工】、【磐奚鸟】都提示加引号试试,如下图所示:构造参数的时候,这个是字符串,数字不支持这么写,加个引号之后,就可以完美解决问题了。三、总结大家好,我是皮皮。这篇文章主要盘点了一个Python二鲁普
1
•••
20
21
22
•••
238