推荐
专栏
教程
课程
飞鹅
本次共找到2376条
网络爬虫
相关的信息
Irene181
•
4年前
3000字 “婴儿级” 爬虫图文教学 | 手把手教你用Python爬取 “实习网”!
1\.为"你"而写这篇文章,是专门为那些"刚学习"Python爬虫的朋友,而专门准备的文章。希望你看过这篇文章后,能够清晰的知道整个"爬虫流程"。从而能够"独立自主"的去完成,某个简单网站的数据爬取。好了,咱们就开始整个“爬虫教学”之旅吧!2\.页面分析①你要爬取的网站是什么?首先,我们应该清楚你要爬去的网站是什么?由于这里我们想要
菜鸟阿都
•
4年前
创建免费ip代理池
     反爬技术越来越成熟,为了爬取目标数据,必须对爬虫的请求进行伪装,骗过目标系统,目标系统通过判断请求的访问频次或请求参数将疑似爬虫的ip进行封禁,要求进行安全验证,通过python的第三方库faker可以随机生成header伪装请求头,并且减缓爬虫的爬取速度,能很好的避过多数目标系统的反扒机制,但对一些安全等级
菜鸟阿都
•
4年前
玩转python爬虫
    近几年来,python的热度一直特别火!大学期间,也进行了一番深入学习,毕业后也曾试图把python作为自己的职业方向,虽然没有如愿成为一名python工程师,但掌握了python,也让我现如今的工作开展和职业发展更加得心应手。这篇文章主要与大家分享一下自己在python爬虫方面的收获与见解。   
Karen110
•
4年前
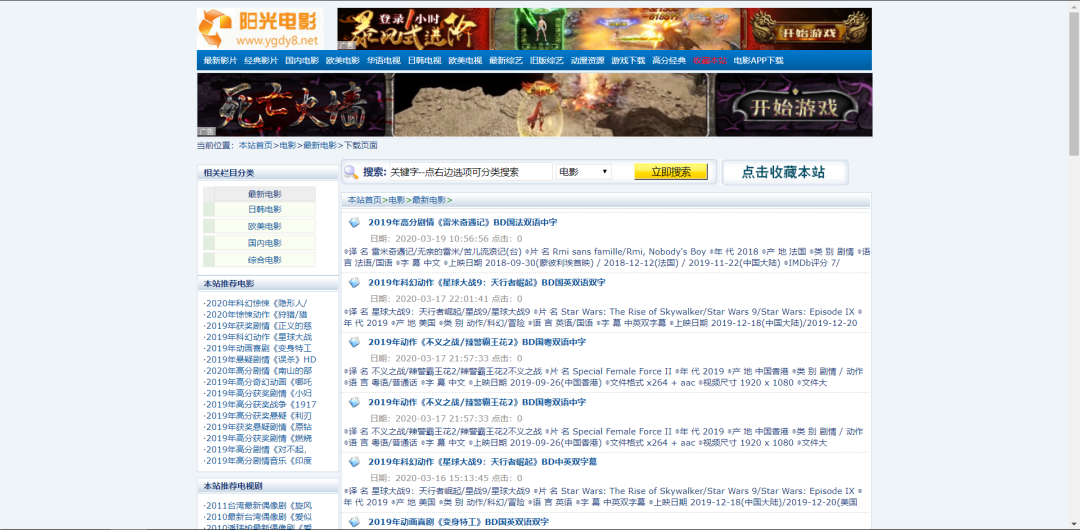
一篇文章教会你利用Python网络爬虫获取电影天堂视频下载链接
【一、项目背景】相信大家都有一种头疼的体验,要下载电影特别费劲,对吧?要一部一部的下载,而且不能直观的知道最近电影更新的状态。今天小编以电影天堂为例,带大家更直观的去看自己喜欢的电影,并且下载下来。【二、项目准备】首先我们第一步我们要安装一个Pycharm的软件。Pycharm软件安装可以看这篇教程:。电影天堂网的网址:https://ww
Wesley13
•
4年前
50 行代码教你爬取猫眼电影 TOP100 榜所有信息
对于Python初学者来说,爬虫技能是应该是最好入门,也是最能够有让自己有成就感的,今天,恋习Python的手把手系列,手把手教你入门Python爬虫,爬取猫眼电影TOP100榜信息,将涉及到基础爬虫架构中的HTML下载器、HTML解析器、数据存储器三大模块:HTML下载器:利用requests模块下载HTML网页;HTML解析器:利用re正则表达
Wesley13
•
4年前
JAVA 调用HTTP接口POST或GET实现方式
HTTP是一个客户端和服务器端请求和应答的标准(TCP),客户端是终端用户,服务器端是网站。通过使用Web浏览器、网络爬虫或者其它的工具,客户端发起一个到服务器上指定端口(默认端口为80)的HTTP请求。具体POST或GET实现代码如下:package com.yoodb.util;import java.
Stella981
•
4年前
Baidu音乐爬虫
Baidu音乐歌曲爬虫:1、分析Baidu音乐歌曲下载接口,组装参数2、判断是否需要登录 a、使用cookie b、使用selenium3、歌曲信息页面分析4、数据表设计歌曲类型表!(https://oscimg.oschina.net/oscnet/31721c4edb51fe06d2c5116a616f012d2e
Stella981
•
4年前
Python爬虫初学
学习爬虫中,从最近自己写的爬虫小程序中抓截一点代码。加深下记忆。1.因为我已经安装了Python3,所以使用了urllib3库。2.要根据对应网页的数据格式进行解码,有的是utf8,有的是GB2312,当然可能还有其它。否则会报错。import urllib3import time因为我使用了Python3,所以使用urlli
Python进阶者
•
3年前
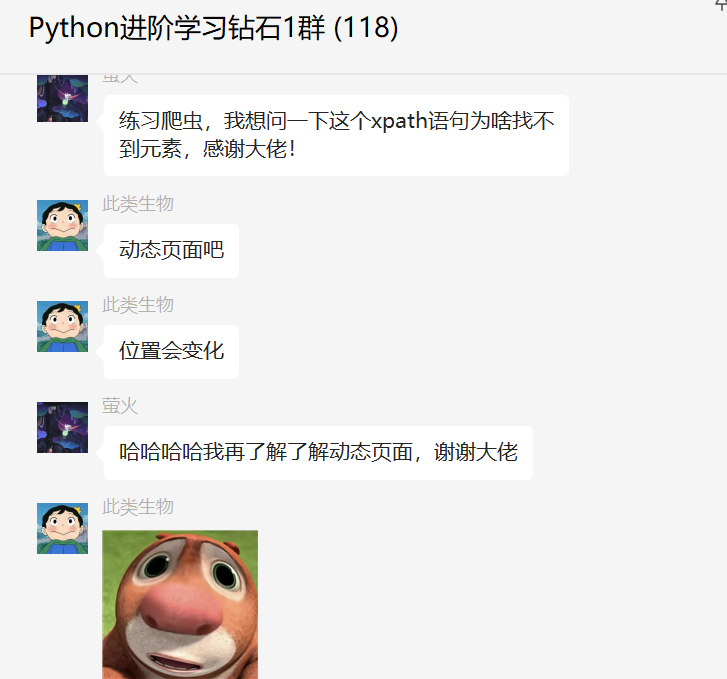
练习爬虫,我想问一下这个xpath语句为啥找不到元素,感谢大佬!
大家好,我是皮皮。一、前言前几天在Python钻石交流群【萤火】问了一个Python网络爬虫的问题,下图是截图:下图是报错截图:二、实现过程这里【error】给了一个代码,如下所示,满足粉丝的需求:用selenium没找到的话,大概率是网页还没渲染出来,代码就运行到了抓取规则,所以抓不到。其实他的匹配规则是可以拿到数据的,只不过用jupyter运行sel
小白学大数据
•
3年前
爬虫中使用代理IP的一些误区
做为爬虫工作者在日常工作中使用爬虫多次爬取同一网站时,经常会被网站的IP反爬虫机制给禁掉,为了解决封禁IP的问题通常会使用代理IP。但也有一部分人在HTTP代理IP的使用上存在着误解,他们认为使用了代理IP就能解决一切问题,然而实际上代理IP不是万
1
•••
17
18
19
•••
238