推荐
专栏
教程
课程
飞鹅
本次共找到2376条
网络爬虫
相关的信息
Python进阶者
•
3年前
Python网络爬虫之js逆向之远程调用(rpc)免去抠代码补环境简介
大家好,我是黑脸怪。这篇文章主要给大家介绍jsrpc,方便大家日后在遇到JS逆向的时候派上用场。前言jsrpc是指在浏览器开启一个ws和go服务连接,以调用http接口的形式来通信,浏览器端收到调用通信执行原先设置好的js代码。可以用于js逆向调用加密函数直接返回结果,也可以用来直接获取数据。该工具和代码,已经上传到git,下载即可用。下载地址:https
Python进阶者
•
3年前
手把手教你用Python网络爬虫进行多线程采集高清游戏壁纸
一、背景介绍大家好,我是皮皮。对于不同的数据我们使用的抓取方式不一样,图片,视频,音频,文本,都有所不同,由于网站图片素材过多,所以今天我们使用多线程的方式采集某站4K高清壁纸。二、页面分析目标网站:http://www.bizhi88.com/3840x2160/如图所示,有278个页面,这里我们爬取前100页的壁纸图片,保存到本地;解析页面如图所示所哟
Python进阶者
•
3年前
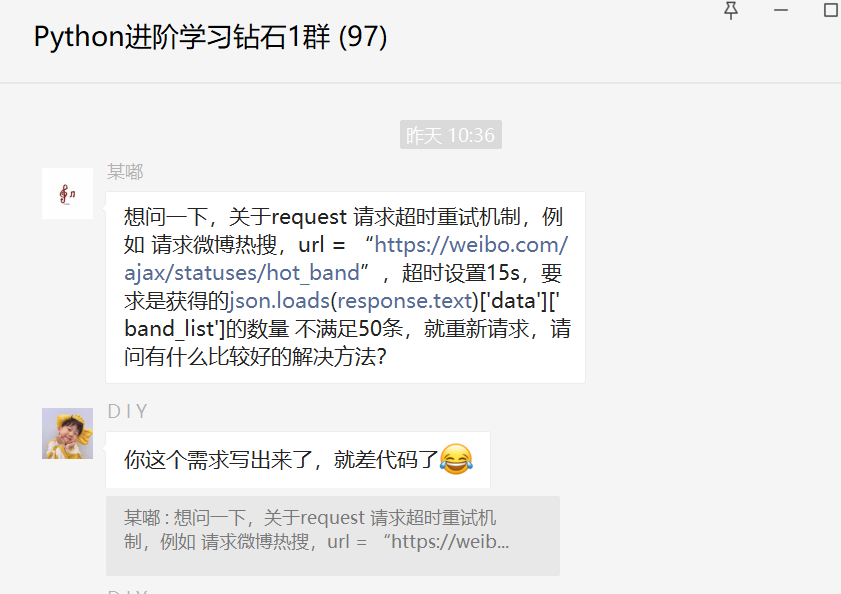
Python网络爬虫中重新请求,请问有什么比较好的解决方法?
大家好,我是皮皮。一、前言前几天在Python钻石群有个叫【某嘟】的粉丝问了一个关于Python网络爬虫中重新请求的问题,这里拿出来给大家分享下,一起学习。二、解决过程这里【DIY】大佬给了一个思路,确实可行。不过后来她自己又找到了一个更好的方法,找到一个HTTPAdapter可以实现超时重试,大概用法如下:fromrequests.adapter
小白学大数据
•
2年前
python如何通过分布式爬虫爬取舆情数据
作为爬虫,有时候会经历过需要爬取站点多吗,数据量大的网站,我们身边接触最频繁、同时也是最大的爬虫莫过于几大搜索引擎。今天我们来聊一个同样是站点多数据量的爬取方向,那就是舆情方向的爬虫。舆情简单来说就是舆论情况,要掌握舆情,那么就必须掌握足够多的内容资讯。除
Irene181
•
4年前
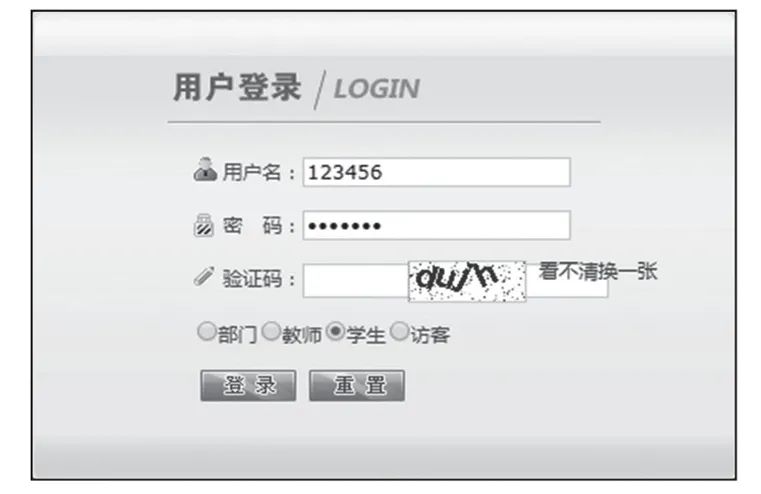
拒绝反爬虫!教你搞定爬虫验证码
导读:目前,许多网站采取各种各样的措施来反爬虫,其中一个措施便是使用验证码。随着技术的发展,验证码的花样越来越多。验证码最初是几个数字组合的简单的图形验证码,后来加入了英文字母和混淆曲线。有的网站还可能看到中文字符的验证码,这使得识别越发困难。使用验证码可以防止应用或者网站被恶意注册、攻击,对于网站、APP而言,大量的无效注册、重复注册甚至是恶意攻击很令
Python进阶者
•
4年前
手把手教你使用Python网络爬虫获取B站视频选集内容(附源码)
大家好,我是Python进阶者。前言前几天雪球兄在Python交流群里分享了一个获取B站视频选集的Python代码,小编觉得非常奈斯,这里整理成一篇小文章,分享给大家学习。关于雪球兄,大家应该都熟悉了,之前他写过Python实战文章,好评如潮,没来得及看的小伙伴,可以戳这里了:之前也有给大家分享B站的一些文章,感兴趣的话可以看看这个文章,Python网络爬
Stella981
•
4年前
Python爬虫原理与python爬虫实例大全
<divid"cnblogs\_post\_body"class"blogpostbody"<h2前言</h2<p简单来说互联网是由一个个站点和网络设备组成的大网,我们通过浏览器访问站点,站点把HTML、JS、CSS代码返回给浏览器,这些代码经过浏览器解析、渲染,将丰富多彩的网页呈现我们眼前;</p<p </p<h
Stella981
•
4年前
GuozhongCrawler看准网爬虫动态切换IP漫爬虫
有些关于URL去重的方面代码没有提供,需要自己去实现。主要这里提供思路项目地址:http://git.oschina.net/woshidaniu/GuozhongCrawler/tree/master/example/changeProxyIp/首先爬虫入口类:publicclassPervadeSpider{
Python进阶者
•
3年前
Python网络爬虫过程中这个selenium对应的火狐驱动怎么用不了?
大家好,我是皮皮。一、前言前几天在Python最强王者交流群【孤独】问了一个Python网络爬虫处理的问题,提问截图如下:报错截图如下:二、实现过程这里【隔壁山楂】、【此类生物】都看到真实路径和代码中写的不匹配,导致没找到对应的驱动。其实针对驱动选择,常用的方法就是将驱动加入到环境变量,一劳永逸。这里【瑜亮老师】、【此类生物】也指出使用绝对路径去加载驱动
Python进阶者
•
2年前
xpath的一次性同时获取a标签和p标签的内容?(下篇)
大家好,我是皮皮。一、前言前几天在Python白银交流群【上海新年人】问了一个Python网络爬虫数据提取的问题,一起来看看吧。他的需求就是:xpath的一次性同时获取a标签和p标签的内容。上一篇文章中,大佬们已经给出了一个答案,可是数据获取下来后发现和网
1
•••
16
17
18
•••
238