大家好,我是皮皮。
一、前言
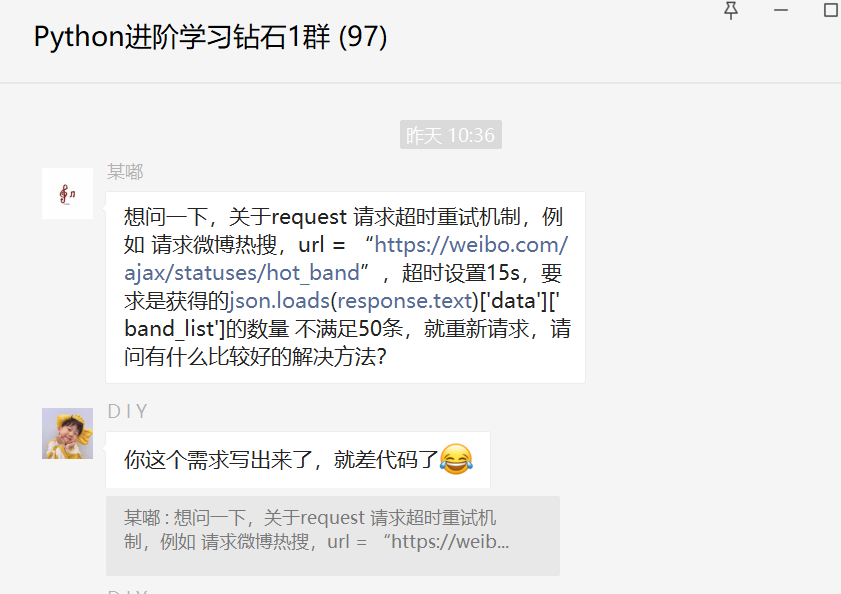
前几天在Python钻石群有个叫【某嘟】的粉丝问了一个关于Python网络爬虫中重新请求的问题,这里拿出来给大家分享下,一起学习。
二、解决过程
这里【D I Y】大佬给了一个思路,确实可行。
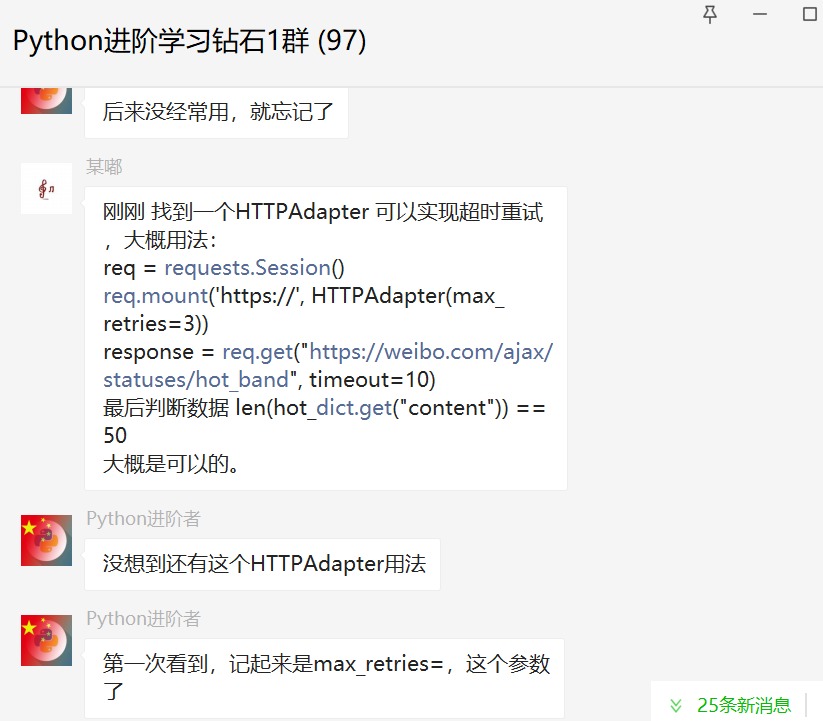
不过后来她自己又找到了一个更好的方法,找到一个HTTPAdapter可以实现超时重试,大概用法如下:
from requests.adapters import HTTPAdapter
req = requests.Session()
req.mount('https://', HTTPAdapter(max_retries=3))
response = req.get("https://weibo.com/ajax/statuses/hot_band", timeout=10)
最后判断数据 len(hot_dict.get("content")) == 50
大概是可以的。
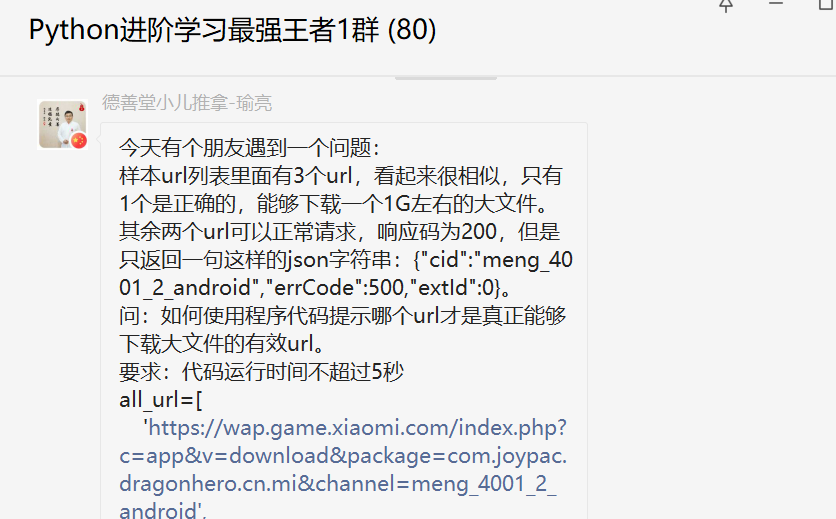
当时看到这里,也想起来前几天【瑜亮老师】分享的那个题目,关于Python网络爬虫请求的时候,大文件的抓取判断。之前也写过文章分享,这里就不再赘述了,感兴趣的小伙伴,可以前往:
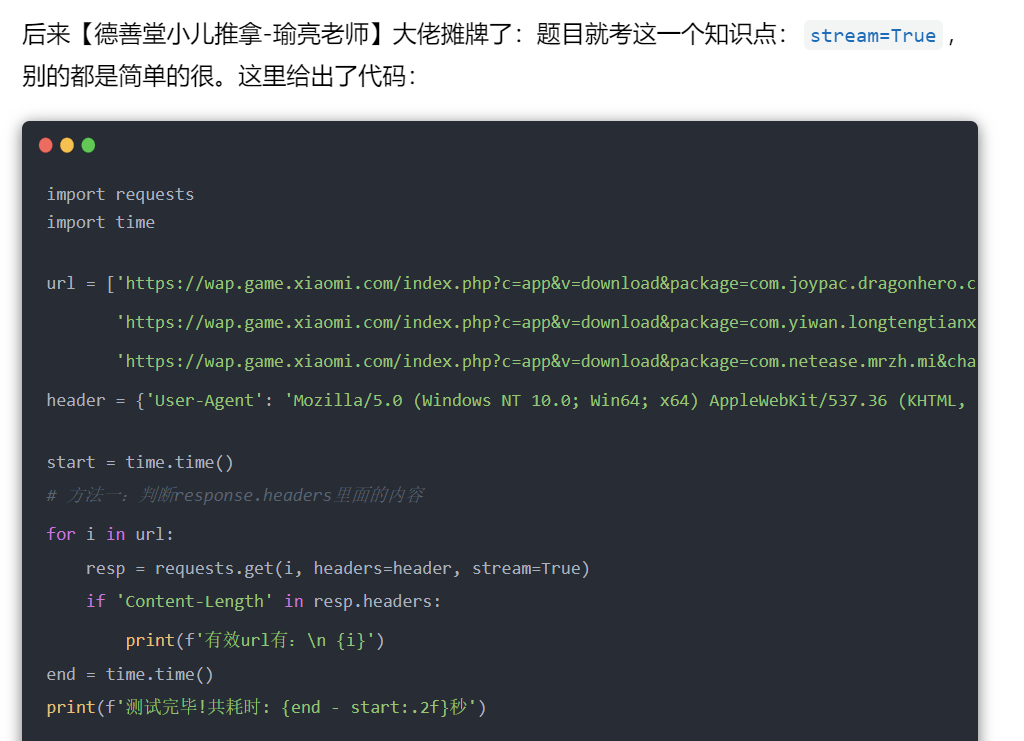
三、总结
大家好,我是皮皮。这篇文章基于粉丝提问,针对Python网络爬虫中重新请求的问题,给出了具体说明和演示,文章提出了两个解决思路,顺利地帮助粉丝解决了问题!
最后感谢粉丝【某嘟】提问,感谢【某嘟】、【D I Y】大佬给出的代码和思路支持,感谢粉丝【PI】、【德善堂小儿推拿-瑜亮老师】等人积极参与学习交流。
小伙伴们,快快用实践一下吧!如果在学习过程中,有遇到任何问题,欢迎加我好友,我拉你进Python学习交流群共同探讨学习。