
Baidu音乐歌曲爬虫:
1、分析Baidu音乐歌曲下载接口,组装参数
2、判断是否需要登录
a、使用cookie
b、使用selenium
3、歌曲信息页面分析
4、数据表设计
歌曲类型表

歌曲表
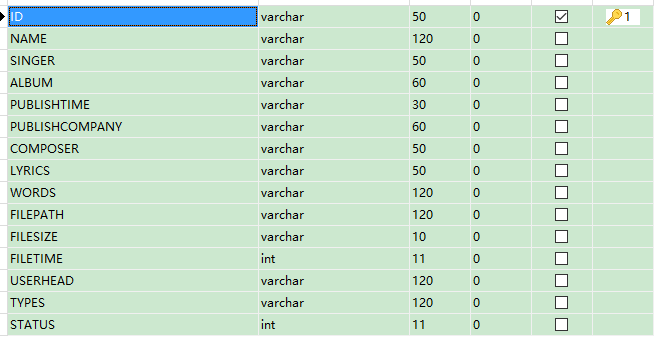
表都无所谓,自己设计就行。
-------------------------------
# -*- coding: utf-8 -*-
'''
***
_author_= "fengshaungzi"
_time_='2018-4-10'
_python_version_ = 'python2.7'
_script_type_ = 'spider'
url = 'http://music.baidu.com/tag/类型?start=0&size=20&third_type=0'
***
'''
from os import path
from bs4 import BeautifulSoup
import urllib,urllib2,requests,cookielib
import sys,time,datetime
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
import pymysql,shutil
import sys,os
reload(sys)
sys.setdefaultencoding('utf-8')
d = path.dirname(__file__)
class BadiuMusicSpider():
def __init__(self):
pass
def login(self,cursor,type_id,type_q):
chrome_options = Options()
chrome_options.add_argument('--headless')
chrome_options.add_argument('--disable-gpu')
driver = webdriver.Chrome()
driver.maximize_window()
driver.get("http://i.baidu.com/welcome/")
time.sleep(5)
driver.find_element_by_xpath('/html/body/header/div/div/a[2]').click()
time.sleep(2)
driver.find_element_by_xpath('//*[@id="TANGRAM__PSP_10__userName"]').clear()
driver.find_element_by_xpath('//*[@id="TANGRAM__PSP_10__userName"]').send_keys('用户')
time.sleep(2)
driver.find_element_by_xpath('//*[@id="TANGRAM__PSP_10__password"]').clear()
driver.find_element_by_xpath('//*[@id="TANGRAM__PSP_10__password"]').send_keys('密码')
##如果有验证码
time.sleep(3)
try:
driver.find_element_by_xpath('//*[@id="TANGRAM__PSP_10__verifyCodeChange"]').click()
input = raw_input(u'请输入验证码:')
code = driver.find_element_by_xpath('//*[@id="TANGRAM__PSP_10__verifyCode"]')
code.clear()
code.send_keys(input)
except:
print u'没有验证码。'
driver.find_element_by_xpath('//*[@id="TANGRAM__PSP_10__submit"]').submit()
time.sleep(2)
self.parse_html(driver,cursor,type_id,type_q)
def parse_html(self,driver,cursor,type_id,type_q,page=1,):
#response = urllib2.urlopen(url).read()
#response = opener.open(urllib2.Request(url, headers=headers))
#response = response.read()
#response = requests.get(url, headers=headers, cookies=cookies).content
#response = opener.open(urllib2.Request(url, headers=headers))
#response = response.read()
start = (page-1)*20
print u'---开始获取第{0}页的数据----'.format(page)
url = 'http://music.baidu.com/tag/{0}?start={1}&size=20&third_type=0'.format(type_q,start)
driver.get(url)
time.sleep(2)
response = driver.page_source
obj = BeautifulSoup(response, 'html.parser')
##获取歌曲m_url
span_list = obj.find_all('span',{"class":"song-title"})
## 判断下是否有下一页
try:
driver.find_element_by_class_name('page-navigator-next')
next_page = 1
except:
next_page = 0
#try:
for v in span_list:
list = []
try:
m_url = v.find('a')['href']
except:
continue
###获取song_id
song_id = m_url.replace('/song/', '')
##组装下url头部
m_url = 'http://music.baidu.com{0}'.format(m_url)
###开始获取歌曲信息
data = self.save_music_info(m_url,type_id)
### 判断data['check']==0,说明歌曲已经存在跳出这次循环
if data.has_key('check'):
print u'---该歌曲已经存在---'
continue
singer_path = u"G:\\www\\music2\\"+data['singer']
###歌曲信息获取完毕开始下载歌曲 需要song_id
music_lrc = self.save_music_lrc(driver,song_id,singer_path)
if music_lrc.has_key('words') and music_lrc['words'] =='暂无':
data['words'] =''
else:
print u"歌词:"+music_lrc['lrc_name']
data['words'] = u'music2/LRC/'+music_lrc['lrc_name']
data['filepath'] = u'music2/{0}/{1}.mp3'.format(data['singer'],data['name'])
## 设置id的值
cursor.execute('select id from network_music order by cast(id as SIGNED INTEGER) desc limit 0,1')
old_id = cursor.fetchone()
if old_id:
id_n = str(int(old_id[0]) + 1)
else:
id_n = str(1)
# 进入数据库
list = [(id_n,data['name'],data['singer'],data['album'],data['publishtime'],data['publishcompany'],data['composer'],data['lyrics'], \
data['filesize'],data['filetime'],data['userhead'],data['types'],data['status'],data['words'],data['filepath'])]
#xprint list
self.save_db(cursor,list)
'''
except:
## 记入log
try:
datetime_now = datetime.datetime.now()
datetime_str = '{0}-{1}-{2} {3}:{4}:{5}'.format(datetime_now.year,datetime_now.month,datetime_now.day,datetime_now.hour,datetime_now.minute,datetime_now.second)
effect_row = cursor.executemany("insert into music_log(page,datetime)values(%s,%s)",[(page,datetime_str)])
## 提交,不然无法保存新建或者修改的数据
conn.commit()
except:
print 'Add log fault!'
'''
page = page + 1
#input = raw_input('输入任意值继续执行:')
if next_page==1:
print u'------开始获取下一页的数据----'
self.parse_html(driver,cursor,type_id,type_q,page=page)
else:
print u"-----爬虫程序即将结束-----"
cursor.close()
conn.close()
def save_music_info(self,m_url,type_id):
data = {}
music_info_response = urllib2.urlopen(m_url).read()
music_info_obj = BeautifulSoup(music_info_response, 'html.parser')
##获取歌曲信息 name singer alnum pubdate pic tag company
name = music_info_obj.find('span',{"class":"name"}).text.strip()
name = name.replace('"','')
name = name.replace("'",'')
singer = music_info_obj.find('span',{"class":"artist"}).find('a').text.strip()
singer = singer.replace('"', '')
singer = singer.replace("'", '')
if os.path.exists("G:\\www\\music2\\"+singer) == False:
os.mkdir("G:\\www\\music2\\"+singer)
else:
print u'歌手文件夹已经存在!'
album = music_info_obj.find('p',{"class":"album"}).find('a').text.strip()
##发布时间需要处理; 排除空白的情况
if music_info_obj.find('p',{"class":"publish"}).text.strip() ==u'发行时间:':
publishtime = '未知'
else:
publishtime = music_info_obj.find('p',{"class":"publish"}).text.strip()
publishtime = publishtime.replace(u'发行时间:','')
##发行公司需要处理;排除空白的情况
if music_info_obj.find('p',{"class":"company"}).text.strip() ==u'发行公司:':
publishcompany = '未知'
else:
publishcompany = music_info_obj.find('p',{"class":"company"}).text.strip()
publishcompany = publishcompany.replace(u'发行公司:','')
###获取图片
pic_url = music_info_obj.find('img',{"class":"music-song-ing"})['src']
if pic_url:
pic_path = self.save_pic(pic_url)
data['name'] = name
print u"歌名:"+name
data['singer'] = singer
print u"歌手:" + singer
data['album'] = album
data['publishtime'] =publishtime
data['publishcompany'] = publishcompany
data['composer'] = ''
data['lyrics'] = ''
data['filesize'] = ''
data['filetime'] = 0
data['userhead'] = pic_path if pic_path else ''
data['types'] = ','+str(type_id)+','
data['status'] = 0
## 判断数据库是否重复
#print 'select id,TYPES from network_music where NAME="{0}" and SINGER="{1}"'.format(name,singer)
cursor.execute('select id,TYPES from network_music where NAME="{0}" and SINGER="{1}"'.format(name,singer))
result_types = cursor.fetchall()
if result_types:
if str(type_id) in result_types[0][1]:
pass
else:
types = result_types[0][1] + str(type_id)+','
cursor.execute("UPDATE network_music SET TYPES='{0}' WHERE id ={1}".format(types, result_types[0][0]))
## 提交,不然无法保存新建或者修改的数据
conn.commit()
data['check'] = 0
return data
def save_music_lrc(self, driver,song_id,singer_path):
music_lrc = {}
m_api = 'http://music.baidu.com/data/music/file?link=&song_id={0}'.format(song_id)
driver.get(m_api)
time.sleep(3)
### 找到最新的文件
path_d = u'C:\\Users\\hz\\Downloads'
file_lists = os.listdir(path_d)
try:
file_lists.sort(key=lambda fn: os.path.getmtime(path_d + "\\" + fn))
filename = file_lists[-1]
if filename:
#print filename
#print singer_path
### 移动到
shutil.move(u'C:\\Users\\hz\\Downloads\\'+filename,singer_path)
except:
#os.remove(my_file)
print u"移动失败,文件名字问题,手动修改"
##跳转到页面
driver.get('http://music.baidu.com/song/{0}'.format(song_id))
time.sleep(2)
try:
l_api = driver.find_element_by_xpath('//*[@id="lyricCont"]').get_attribute('data-lrclink')
driver.get(l_api)
time.sleep(2)
try:
music_lrc['lrc_name'] = self.get_lrc_path()
except:
print u'获取歌词文件名错误'
except:
music_lrc['words'] = '暂无'
print u'没有歌词'
return music_lrc
def save_db(self,cursor,list):
print list
try:
effect_row = cursor.executemany("insert into network_music(ID,NAME,SINGER,ALBUM,PUBLISHTIME,PUBLISHCOMPANY,COMPOSER,LYRICS, \
FILESIZE,FILETIME,USERHEAD,TYPES,STATUS,WORDS,FILEPATH)values(%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s) ", list)
## 提交,不然无法保存新建或者修改的数据
conn.commit()
except:
print 'Add this db fault!'
def save_pic(self, pic_url, save_path=''):
##组装成接口
pic_list = ['.jpg@','.png@','.jpeg@','.JPG@','.PNG@','.JPEG@']
for v in pic_list:
#print pic_url
if v in pic_url:
check = 1
else:
endname = '.errorpic'
if 'check' in vars() and check == 1:
endname = v.replace('@', '')
#print endname,pic_url
save_path = path.join(d, 'music2/USERHEAD/')
###名字暂用时间戳
picName = int(time.time())
savepic = save_path + str(picName) + endname
try:
urllib.urlretrieve(pic_url, savepic)
return 'music2/USERHEAD/' + str(picName) + endname
except:
return 'no'
def get_lrc_path(self):
path_d = u'C:\\Users\\hz\\Downloads'
file_lists = os.listdir(path_d)
file_lists.sort(key=lambda fn: os.path.getmtime(path_d + "\\" + fn))
lrc_name = file_lists[-1]
'''
if lrc_name:
shutil.move(u'C:\\Users\\hz\\Downloads\\' + lrc_name, u'G:\\www\\music2\\LRC\\')
'''
return lrc_name
'''
def auto_down1(self, url, filename):
try:
urllib.urlretrieve(url, filename)
except urllib.ContentTooShortError:
print 'Network conditions is not good.Reloading.'
auto_down(url, filename)
def auto_down2(self, url, filename):
##加载cookies
raw_cookies = "PSTM=1523331116; BIDUPSID=6598753517A81D738FD546C2D96EDAC5; BAIDUID=E5EE59A93C8788A953248CD76BEBD48D:FG=1; H_PS_PSSID=1425_18194_21127_26182_20928; BDORZ=B490B5EBF6F3CD402E515D22BCDA1598; PHPSESSID=bae76nl31pln7r47vi3i1o9jh7; Hm_lvt_4010fd5075fcfe46a16ec4cb65e02f04=1523420559,1523420572; PSINO=2; Hm_lpvt_4010fd5075fcfe46a16ec4cb65e02f04=1523425208"
cookies = {}
for line in raw_cookies.split(';'):
key, value = line.split('=', 1) # 1代表只分一次,得到两个数据
cookies[key] = value
r = requests.get(url, stream=True,cookies = cookies )
f = open(filename, "wb")
for chunk in r.iter_content(chunk_size=512):
if chunk:
f.write(chunk)
f.close()
def auto_down3(self, url, filename):
cookie = cookielib.MozillaCookieJar()
cookie.load('c.txt', ignore_expires=True, ignore_discard=True)
opener = urllib2.build_opener(urllib2.HTTPCookieProcessor(cookie))
urllib2.install_opener(opener)
music = urllib2.urlopen(url).read()
f = open(filename,'wb')
f.write(music)
f.close()
'''
if __name__ == "__main__":
print r'Starting....'
for i in range(5):
sys.stdout.write('>'*i + '\n')
sys.stdout.flush()
time.sleep(0.5)
conn = pymysql.Connection(host="localhost", user="root", passwd="root", db='test1', charset="UTF8")
# 创建指针
cursor = conn.cursor()
type = raw_input(r'请输入歌曲的类型: ').strip()
## 加入数据库
## 先判断值是否存在
result = cursor.execute("select id from network_type where RESOURCETYPE='m' and TYPENAME='{0}'".format(type))
if result == 0:
print u'-----该类型不存在添加至数据库-------'
effect_row = cursor.executemany("insert into network_type(PID,RESOURCETYPE,TYPENAME)values(%s,%s,%s)", [(-1,'m',type)])
type_id = int(cursor.lastrowid)
else:
print u'-----该类型存在不需要添加至数据库-------'
type_val= cursor.fetchall()
type_id = type_val[0][0]
## 提交,不然无法保存新建或者修改的数据
conn.commit()
type_q = urllib2.quote(type)
# 实例
bmSpider = BadiuMusicSpider()
bmSpider.login(cursor,type_id,type_q)
----代码的逻辑
第一步:登录百度,使用selenium(本来我打算用selenium登录之后导出cookie,再通过加载cookie,但是遇到了些问题,再加上工作原因就没有用这个,下次我有空再试,验证码方面,没有设置,遇到验证码关了重启,只要登录成功了,可以爬很久了。)
第二步:输入歌曲类型,默认从第一页开始抓取,接下来就是各种循环,入库啥的,还有文件移动。
总的来说还是比较简单的一个爬虫,不足之处大佬轻喷。











