推荐
专栏
教程
课程
飞鹅
本次共找到438条
硬件创业
相关的信息
Karen110
•
4年前
计算机系统漫游:贯穿计算机系统所有方面的重要概念
作者:RandalE.Bryant,DavidR.O'Hallaron来源:华章计算机(hzbook\jsj)计算机系统是由硬件和系统软件组成的,它们共同协作以运行应用程序。计算机内部的信息被表示为一组组的位,它们依据上下文有不同的解释方式。程序被其他程序翻译成不同的形式,开始时是ASCII文本,然后被编译器和链接器翻译成二进制可执行文件。处
Stella981
•
4年前
Kafka 和 RocketMQ 之性能对比
在双十一过程中投入同样的硬件资源,Kafka搭建的日志集群单个Topic可以达到几百万的TPS,而使用RocketMQ组件的核心业务集群,集群TPS只能达到几十万TPS,这样的现象激发了我对两者性能方面的思考。温馨提示:TPS只是众多性能指标中的一个,我们在做技术选型方面要从多方面考虑,本文并不打算就消息中间件选型方面投入太多笔墨,重点想尝试剖析两
Stella981
•
4年前
HAProxy编译安装及配置详解
简介HAProxy提供高可用性、负载均衡以及基于TCP和HTTP应用的代理,支持虚拟主机,它是免费、快速并且可靠的一种解决方案。HAProxy特别适用于那些负载特大的web站点,这些站点通常又需要会话保持或七层处理。HAProxy运行在当前的硬件上,完全可以支持数以万计的并发连接。并且它的运行模式使得它可以很简单安全的整合进您当前的架构中
Stella981
•
4年前
Linux RPS RFS
随着单核CPU速度已经达到极限,CPU向多核方向发展,要持续提高网络处理带宽,传统的提升硬件设备、智能处理(如GSO、TSO、UFO)处理办法已不足够。如何充分利用多核优势来进行并行处理提高网络处理速度就是RPS解决的课题。以一个具有8核CPU和一个NIC的,连接在网络中的主机来说,对于由该主机产生并通过NIC发送到网络中的数据,CPU核的并行性是自热而然
helloworld_61442022
•
4年前
为什么选择云计算?
云计算是企业摒弃传统IT资源思维的重要转变。以下是组织转向云计算服务的七个常见原因:费用云计算让您无需投资硬件和软件,也无需设置和运行现场数据中心(包括服务器机架、不间断电源供电和冷却,以及IT专家管理基础架构)。它也提高了速度。全局缩放云计算service的优势包括灵活扩展的能力。对于云来说,这意味着在需要时可以从正确的地理位置提供适量的IT资源,例如或
个推技术实践
•
3年前
个推技术 | Hadoop3.0时代,怎么能不懂EC纠删码技术
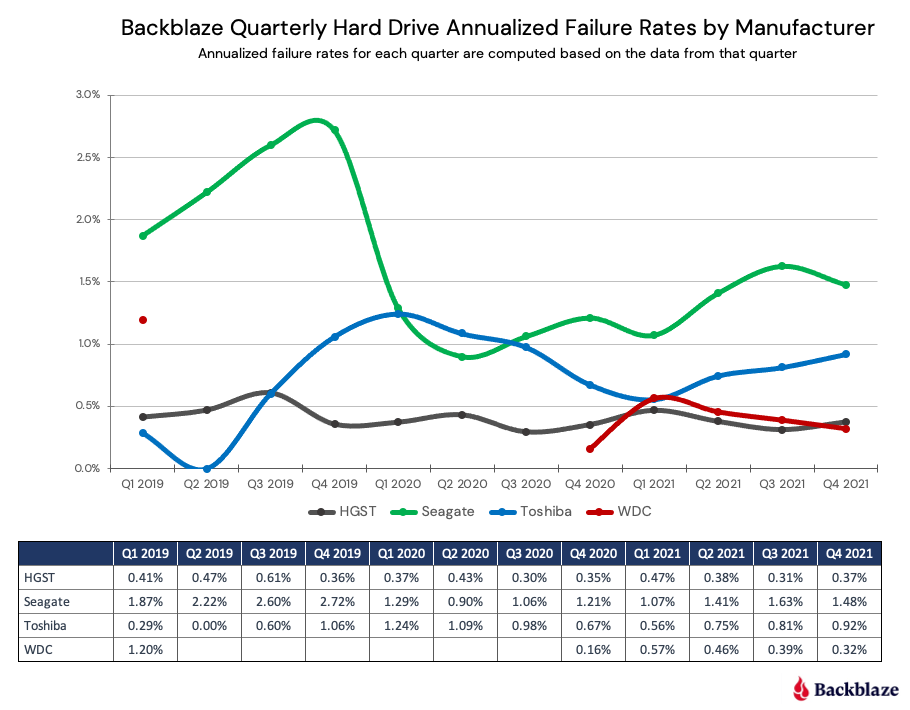
根据云存储服务商Backblaze发布的2021年硬盘“质量报告”,现有存储硬件设备的可靠性无法完全保证,我们需要在软件层面通过一些机制来实现可靠存储。一个分布式软件的常用设计原则就是面向失效的设计。作为当前广泛流行的分布式文件系统,HDFS需要解决的一个重要问题就是数据的可靠性问题。3.0以前版本的Hadoop在HDFS上只能采用多副本冗余的方式做数据备份
天翼云开发者社区
•
3年前
SPDK对接Ceph性能优化
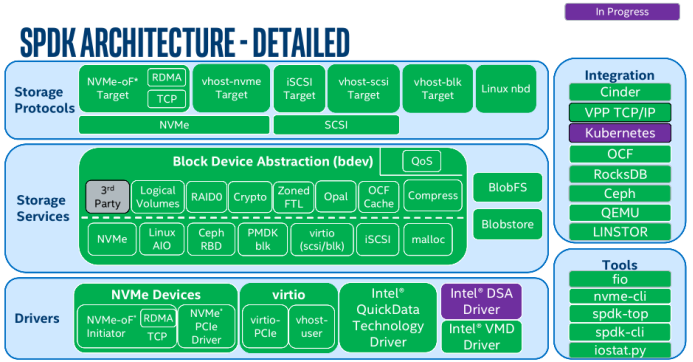
关键词:SPDK、NVMeOF、Ceph、CPU负载均衡SPDK是intel公司主导开发的一套存储高性能开发套件,提供了一组工具和库,用于编写高性能、可扩展和用户态存储应用。它通过使用一些关键技术实现了高性能:1.将所有必需的驱动程序移到用户空间,以避免系统调用并且支持零拷贝访问2.IO的完成通过轮询硬件而不是依赖中断,以降低时延3.使用消息传递,以避免IO
美味蟹黄堡
•
3年前
香港VPS的服务架构有哪些?
香港vps云服务器的服务架构有:1、IaaS,能构建所有其他类型的香港云计算解决方案;2、SaaS,客户可以在订购的基础上访问它,能有效地消除了盗版;3、DaaS,能消除因丢失IT硬件而丢失数据的风险;4、DRaaS,能在香港云端备份工作环境,在系统出现故障数据丢失时从中恢复,还可用于创建数据或应用程序的热插拔版本。测试环境是使用的3A网络的香港VPS,速度
新支点小星
•
2年前
CNAS中兴新支点——软件兼容测试从哪些方面判断
中兴新支点致力于第三方计算机软件测试服务的国家高新技术企业,公司成立于2004年02月,是经国家授权认可的,公正、权威的第三方软件检测机构,检测范围包含应用软件产品(全部检测项)、计算机网络系统、机房/计算机场地及综合布线系统。检测实验室涵盖了从软硬件产品
天翼云开发者社区
•
1年前
AI时代云动力:新一代弹性计算云主机开启智能计算新纪元!
为打造更加卓越的上云体验,天翼云不断升级弹性计算服务,自研第八代升级款弹性云主机,依托天翼云自研TeleCloudOS4.0架构,实现从底层硬件到IaaS云平台的融合优化,AI场景平均性能提升超过50%,计算增强型c8e实例性能提升高达15%,相同功耗下平均性能提升超过20%,带来更高的能源效率和更低的运营成本。
1
•••
36
37
38
•••
44