
在双十一过程中投入同样的硬件资源,Kafka 搭建的日志集群单个Topic可以达到几百万的TPS,而使用RocketMQ组件的核心业务集群,集群TPS只能达到几十万TPS,这样的现象激发了我对两者性能方面的思考。
温馨提示:TPS只是众多性能指标中的一个,我们在做技术选型方面要从多方面考虑,本文并不打算就消息中间件选型方面投入太多笔墨,重点想尝试剖析两者在性能方面的设计思想。
1、文件布局
1.1 Kafka 文件布局
Kafka 文件在宏观上的布局如下图所示:

正如上图所示,Kafka 文件布局的主要特征如下:
文件的组织以 topic + 分区进行组织,每一个 topic 可以创建多个分区,每一个分区包含单独的文件夹,并且是多副本机制,即 topic 的每一个分区会有 Leader 与 Follow,并且 Kafka 内部有机制保证 topic 的某一个分区的 Leader 与 follow 不会存在在同一台机器,并且每一台 broker 会尽量均衡的承担各个分区的 Leader,当然在运行过程中如果不均衡,可以执行命令进行手动重平衡。Leader 节点承担一个分区的读写,follow 节点只负责数据备份。
Kafka 的负载均衡主要依靠分区 Leader 节点的分布情况。
分区的 Leader 节点负责读写,而从节点负责数据同步,如果Leader分区所在的Broker节点发生宕机,会触发主从节点的切换,会在剩下的 follow 节点中选举一个新的 Leader 节点,其数据的流入流程如下图所示:
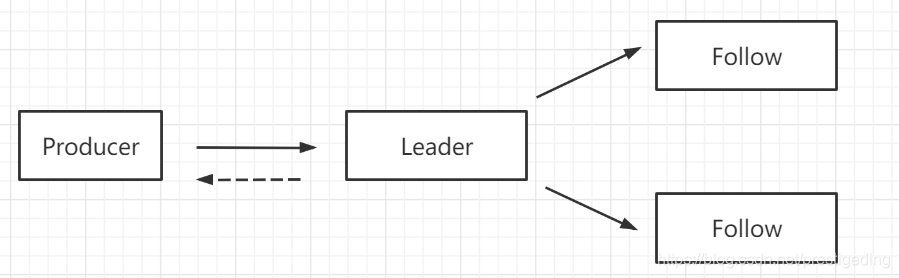
分区 Leader 收到客户端的消息发送请求时,是写入到 Leader 节点后就返回还是要等到它的从节点全部写入后再返回,这里非常关键,会直接影响消息发送端的时延,故 Kafka 提供了 ack 这个参数来进行策略选择:
ack = 0
不等broker端确认就直接返回,即客户端将消息发送到网络中就返回发送成功。
ack = 1
Leader 节点接受并存储后向客户端返回成功。
ack = -1
Leader节点和所有的Follow节点接受并成功存储再向客户端返回成功。
1.2 RocketMQ 文件布局
RocketMQ 的文件布局如下图所示:
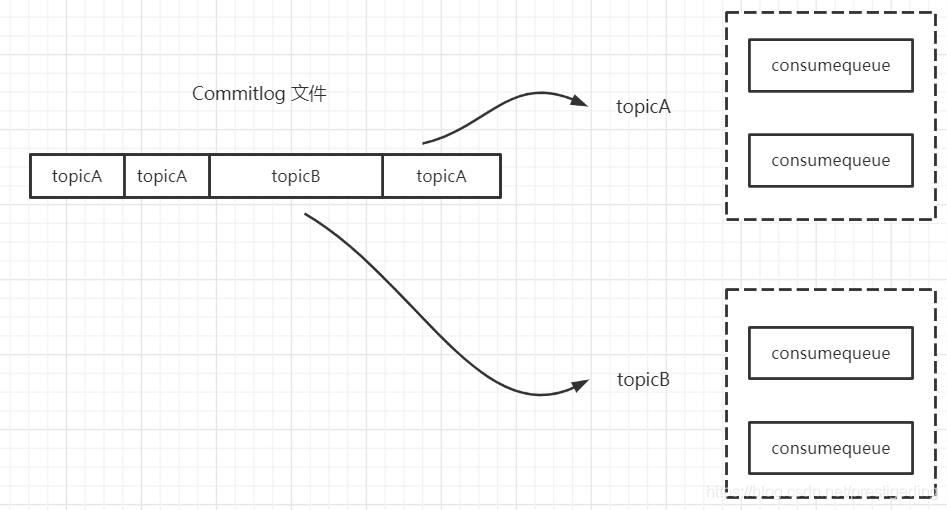
RocketMQ 所有主题的消息都会写入到 commitlog 文件中,然后基于 commitlog 文件构建消息消费队列文件(Consumequeue),消息消费队列的组织结构按照 /topic/{queue} 进行组织。 从集群的视角来看如下图所示:
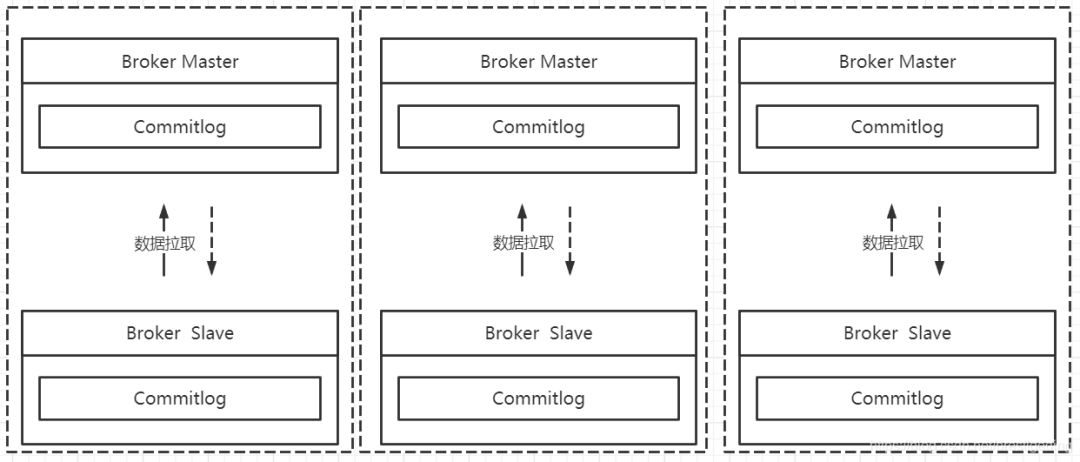 RocketMQ 默认采取的是主从同步,当然从RocketMQ4.5引入了多副本机制,但其 副本的粒度为 Commitlog 文件 ,上图中不同 master 节点之间的数据完成不一样(数据分片),而主从节点节点数据一致。
RocketMQ 默认采取的是主从同步,当然从RocketMQ4.5引入了多副本机制,但其 副本的粒度为 Commitlog 文件 ,上图中不同 master 节点之间的数据完成不一样(数据分片),而主从节点节点数据一致。
1.3 文件布局对比
Kafka 中文件的布局是以 Topic/partition ,每一个分区一个物理文件夹,在分区文件级别实现文件顺序写,如果一个Kafka集群中拥有成百上千个主题,每一个主题拥有上百个分区,消息在高并发写入时,其IO操作就会显得零散,其操作相当于随机IO,即 Kafka 在消息写入时的IO性能会随着 topic 、分区数量的增长,其写入性能会先上升,然后下降。
而 RocketMQ在消息写入时追求极致的顺序写,所有的消息不分主题一律顺序写入 commitlog 文件,并不会随着 topic 和 分区数量的增加而影响其顺序性。但通过笔者的实践来看一台物理机并使用SSD盘,但一个文件无法充分利用磁盘IO的性能。
两者文件组织方式,除了在磁盘的顺序写方面有所区别后,由于其粒度的问题,Kafka 的 topic 扩容分区会涉及分区在各个 Broker 的移动,其扩容操作比较重,而 RocketMQ 数据存储是基于 commitlog 文件的,扩容时不会产生数据移动,只会对新的数据产生影响,RocketMQ 的运维成本对 Kafka 更低。
最后 Kafka 的 ack 参数可以类比 RocketMQ 的同步复制、异步复制。
Kafka 的 ack 参数为 1 时,对比 RocketMQ 的异步复制;-1 对标 RocketMQ 的 同步复制,而 -1 则对标 RocketMQ 消息发送方式的 oneway 模式。
2、数据写入方式
2.1 Kafka 消息写入方式
Kafka 的消息写入使用的是 FileChannel,其代码截图如下:
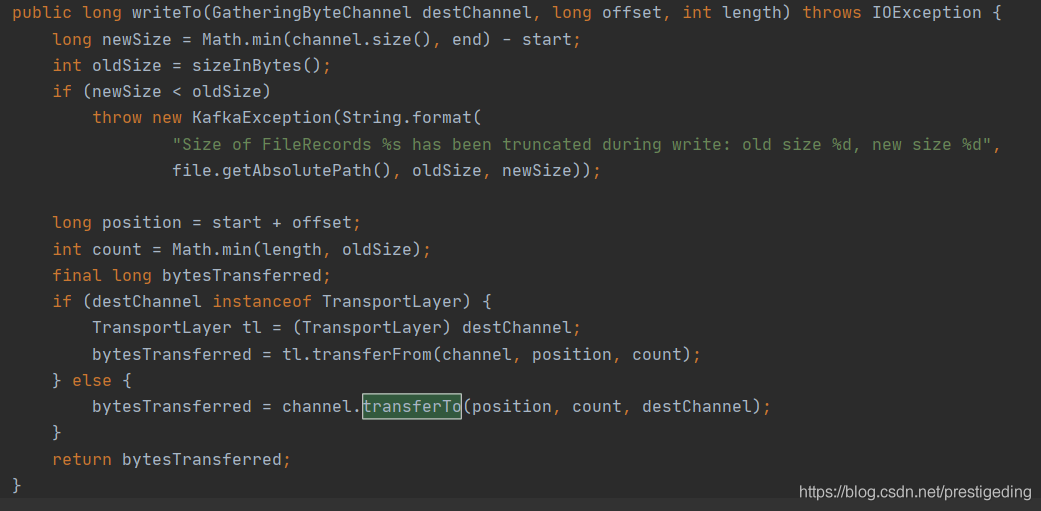
并且在消息写入时使用了 transferTo 方法,根据网上的资料说 NIO 中网络读写真正是零拷贝的就是需要调用 FileChannel 的 transferTo或者 transferFrom 方法,其内部机制是利用了 sendfile 系统调用。
2.2 RocketMQ 消息写入方式
RocketMQ 的消息写入支持 内存映射 与 FileChannel 写入两种方式, 示例如下图所示:
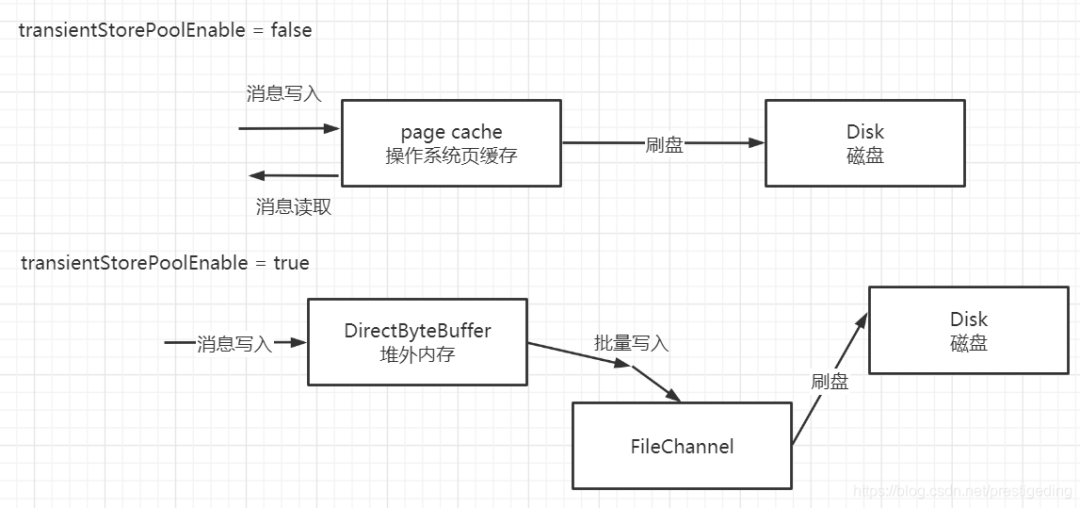
2.3 消息写入方式对比
尽管 RocketMQ 与 Kafka 都支持 FileChannel 方式写入,但 RocketMQ 基于 FileChannel 写入时调用的 API 却并不是 transferTo,而是先调用 writer,然后定时 flush 刷写到磁盘,其代码截图如下:
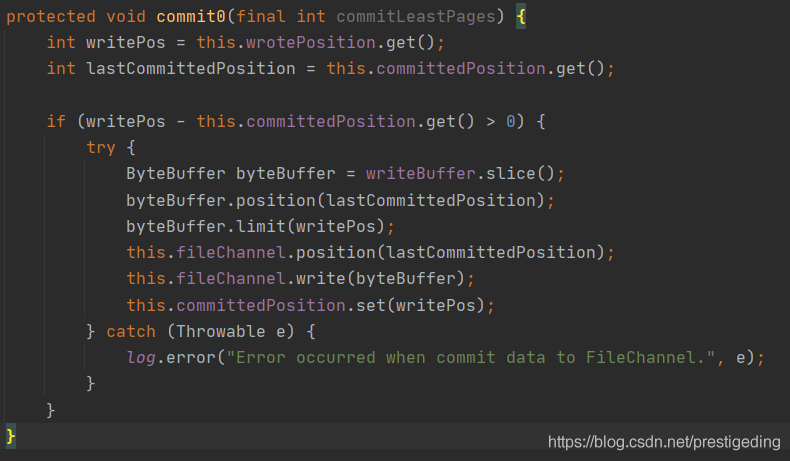
为什么 RocketMQ 不调用 transerTo 方法呢,个人觉得和 RocketMQ 需要在 Broker 组装 MQ 消息格式有关,需要从网络中解码请求,传输到堆内存,然后对消息进行加工,最终持久化到磁盘相关。
从网上查询资料中大概倾向于这样一个 观点:sendfile 系统调用相比内存映射多了一次从用户缓存区拷贝到内核缓存区,但对于超过64K的内存写入时往往 sendfile 的性能更高,可能是由于 sendfile 是基于块内存的。
3、消息发送方式
3.1 Kafka 消息发送机制
Kafka 在消息发送客户端采用了一个双端队列,引入了批处理思想,其消息发送机制如下图所示:
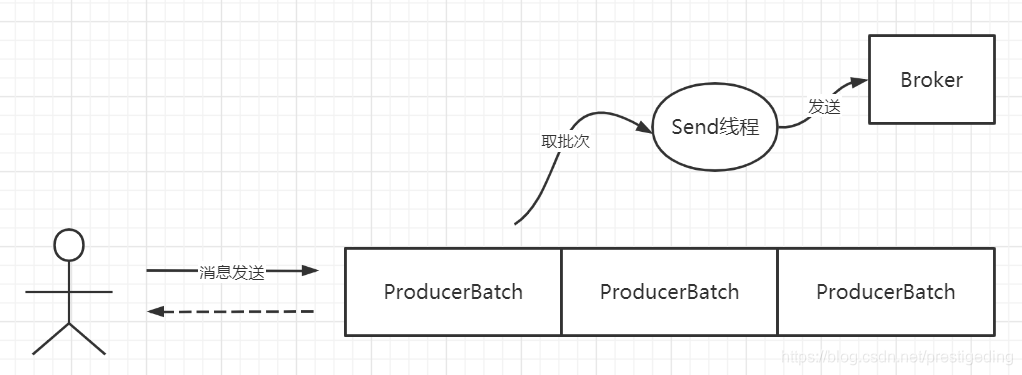 客户端通过调用 kafka 的消息发送者发送消息时,消息会首先存入到一个双端队列中,双端队列中单个元素为 ProducerBatch,表示一个发送批次,其最大大小受参数 batch.size 控制,默认为 16K。 然后会单独开一个 Send 线程,从双端队列中获取一个发送批次,将消息按批发送到 Kafka集群中,这里引入了 linger.ms 参数来控制 Send 线程的发送行为。
客户端通过调用 kafka 的消息发送者发送消息时,消息会首先存入到一个双端队列中,双端队列中单个元素为 ProducerBatch,表示一个发送批次,其最大大小受参数 batch.size 控制,默认为 16K。 然后会单独开一个 Send 线程,从双端队列中获取一个发送批次,将消息按批发送到 Kafka集群中,这里引入了 linger.ms 参数来控制 Send 线程的发送行为。
为了提高 kafka 消息发送的高吞吐量,即控制在缓存区中未积满 batch.size 时来控制消息发送线程的行为,是立即发送还是等待一定时间,如果linger.ms 设置为 0表示立即发送,如果设置为大于0,则消息发送线程会等待这个值后才会向broker发送。**linger.ms 参数者会增加响应时间,但有利于增加吞吐量。有点类似于 TCP 领域的 Nagle 算法**。
Kafka 的消息发送,在写入 ProducerBatch 时会按照消息存储协议组织好数据,在服务端可以直接写入到文件中。
3.2 RocketMQ 消息发送机制
RocketMQ 消息发送在客户端主要是根据路由选择算法选择一个队列,然后将消息发送到服务端,消息会在服务端按照消息的存储格式进行组织,然后进行持久化等操作。
3.3 消息发送对比
Kafka 在消息发送方面比 RokcetMQ 有一个显著的优势就是消息格式的组织是发生在客户端,这样会有一个大的优势节约了 Broker 端的CPU压力,客户端“分布式”的承接了其优势,其架构方式有点类似 shardingjdbc 与 MyCat 的区别。
Kafka 在消息发送端另外一个特点是引入了双端缓存队列,Kafka 无处不在追求批处理,这样显著的特点是能提高消息发送的吞吐量,但与之带来的是增大消息的响应时间,并且带来了消息丢失的可能性,因为 Kafka 追加到消息缓存后会返回成功,如果消息发送方异常退出,会带来消息丢失。
Kafka 中的 linger.ms = 0 可类比 RocketMQ 消息发送的效果。
但 Kafka 通过提供 batch.size 与 linger.ms 两个参数按照场景进行定制化,比 RocketMQ 灵活。
例如日志集群,通常会调大 batch.size 与 linger.ms 参数,重复发挥消息批量发送机制,提高其吞吐量;但如果对一些响应时间比较敏感的话,可以适当减少 linger.ms 的值。
4、总结
从上面的对比来看,Kafka 在性能上综合表现确实要比 RocketMQ 更加的优秀,但在消息选型过程中,我们不仅仅要参考其性能,还有从功能性上来考虑,例如 RocketMQ 提供了丰富的消息检索功能、事务消息、消息消费重试、定时消息等。
笔者个人认为通常在大数据、流式处理场景基本选用 Kafka,业务处理相关选择 RocketMQ。
文章首发『中间件兴趣圈』公众号,

目前已覆盖的知识体系如下图所示: 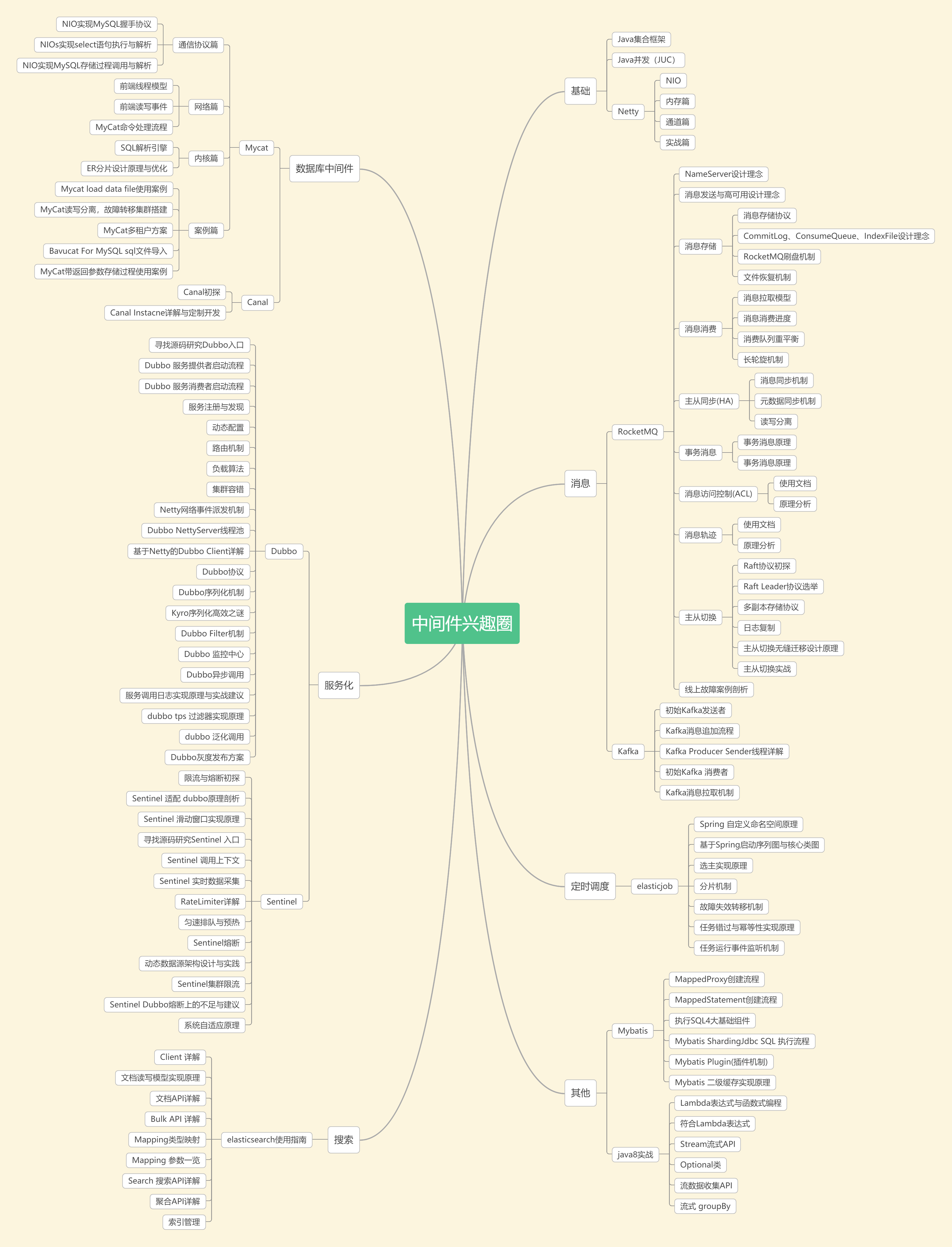
本文分享自微信公众号 - 中间件兴趣圈(dingwpmz_zjj)。
如有侵权,请联系 support@oschina.cn 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。











