推荐
专栏
教程
课程
飞鹅
本次共找到765条
流量统计
相关的信息
C_N_Candy
•
4年前
关于WIFI密码破解——握手包(详细图文教程)
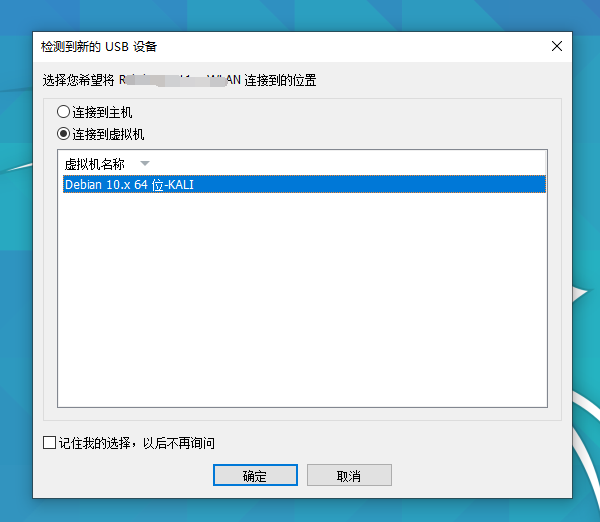
前言:新搬的地方还没有安装WIFI,流量手机流量快烧完了,看着附近的WIFI,很是心动。于是上网搜索了一下教程进行试验,试验过程和结果,仅作为学习记录。试验环境:1.台式机2.Kali虚拟机3.无线网卡4.菜鸡一只试验过程:一、无线网卡安排1.主机USB接口直接怼入无线网卡,Kali虚拟机弹窗提示,选择连接到虚拟机,选中Kali,点击确定。(看
飞在秋天的蝴蝶
•
3年前
小白初学JavaScript,遇得到一个关于document.write输出的问题,求教
题目如下:统计在这些单词:“America”、“Greece”、“Britain”、“Canada”、“China”、“Egypt”中包含“a”或“A”的字符串的个数。下面是我写的代码:languageDocumentvarziMunewArray("America","Greece
Stella981
•
4年前
QPS 提升60%,揭秘阿里巴巴轻量级开源 Web 服务器 Tengine 负载均衡算法
前言在阿里七层流量入口接入层(ApplicationGateway)场景下,Nginx官方的SmoothWeightedRoundRobin(SWRR)负载均衡算法已经无法再完美施展它的技能。Tengine通过实现新的负载均衡算法VirtualNodeSmoothWeightedRoundRobin(VNSWRR)不
Stella981
•
4年前
APICloud的发展和应用
前言随着近几年互联网进入下沉期,C端app产品告别了早期的抢占市场阶段,进入寡头时代。微信、支付宝、头条等超级app们希望建立起自有生态主导流量分发,纷纷推出了各自的小程序开发技术,允许用户在其app内运行一个“小app”,分享超级app的流量红利。App作为移动互联网时代企业业务非常重要的载体之一,如果企业没有技术团队怎么办?技术团队实力不强
Wesley13
•
4年前
mysql中count()函数的用法
数量查询时,有如下几种方式:1.下面三种方式,在多数情况下效率是基本相同的,但问题在于,很多情况下,我们数据库可能有脏数据,比如重复数据,或者某条数据重要字段是null的,那下面的这几种,会把这种脏数据也统计上,本质都是统计满足条件的行数的:selectcount()fromuserselectcount(1)f
Wesley13
•
4年前
DDOS防护原理
1.常见DDoS攻击分类DDoS粗略分类为流量型攻击和CC攻击。流量型攻击主要是通过发送报文侵占正常业务带宽,甚至堵塞整个数据中心的出口,导致正常用户访问无法达到业务服务器。CC攻击主要是针对某些业务服务进行频繁访问,重点在于通过精心选择访问的服务,激发大量消耗资源的数据库查询、文件IO等,导致业务服务器CPU、内存或者IO出现瓶颈,无法正常提供服务。比
helloworld_01824035
•
3年前
【统计、图形和样本量软件】上海道宁为您提高强大的统计分析、图形和样本量工具
NCSS是一个强大的统计和图形程序用于从医学调查和商业分析到工程、质量控制和学术研究的各种行业
京东云开发者
•
2年前
浅谈Redis - 热点key问题 | 京东云技术团队
热key问题就是突然有几十万的请求去访问redis上的某个特定key,那么这样会造成流量过于集中,达到物理网卡上限,从而导致这台redis服务器直接宕机。
京东云开发者
•
2年前
Java服务总在半夜挂,背后的真相竟然是... | 京东云技术团队
最近有用户反馈测试环境Java服务总在凌晨00:00左右挂掉,用户反馈Java服务没有定时任务,也没有流量突增的情况,Jvm配置也合理,莫名其妙就挂了
天翼云开发者社区
•
1年前
基础带宽产品怎么选?手把手教学
基础带宽产品有弹性IP、共享带宽和共享流量包,我们既想访问公网,又想节省资金,怎么能快速选择适合的带宽产品呢?我们需要先从这几个产品的基本构成开始了解。
1
•••
17
18
19
•••
77