
前言
在阿里七层流量入口接入层(Application Gateway)场景下, Nginx 官方的Smooth Weighted Round-Robin( SWRR )负载均衡算法已经无法再完美施展它的技能。 Tengine 通过实现新的负载均衡算法Virtual Node Smooth Weighted Round-Robin(VNSWRR )不仅优雅的解决了 SWRR 算法的缺陷,而且QPS处理能力相对于 Nginx 官方的 SWRR 算法提升了60%左右。
问题
接入层 Tengine 通过自研的动态 upstream 模块实现动态服务发现,即运行时动态感知后端应用机器扩缩容、权重调整和健康检查等信息。同时该功能可以做很多事情,比如用户可通过调整后端应用某台机器的权重从而达到线上真实引流压测目的。然而,这些操作在 Nginx 原生 SWRR 算法下却可能引起不可逆转的血案。
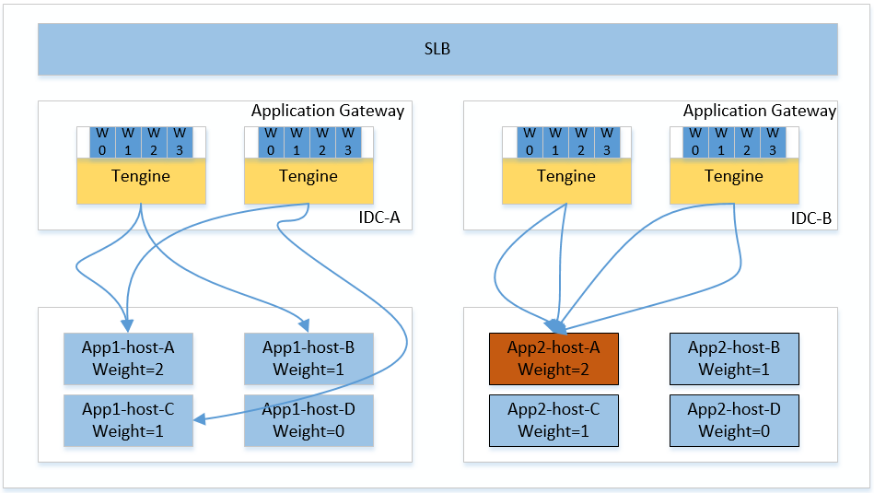
• 在接入层(Application Gateway)场景下, Nginx 的负载均衡算法 SWRR 会导致权重被调高机器的QPS瞬间暴涨,如上图App2-host-A机器当权重调整为2时,某一时刻流量会集中转发到该机器;
• Nginx 的 SWRR 算法的处理时间复杂度是O(N),在大规模后端场景下 Nginx 的处理能力将线性下降;
综上所述,对接入层 Tengine 的负载均衡转发策略的改造及性能优化已迫在眉睫。
原生 SWRR 算法分析
在介绍案列之前,我们先简单介绍下 Nginx 的负载均衡算法 SWRR 转发策略及特点:
SWRR 算法全称是Smooth Weighted Round-Robin Balancing,顾名思义该算法相比于其它加权轮询(WRR)算法多一个smooth(平滑)的特性。
下面我们就一个简单的列子来描述下该算法:
假设有3台机器A、B、C权重分别为5、1、1,其中数组s代表机器列表、n代表机器数量,每个机器的cw初始化为0、ew初始化为机器权重、tw代表本轮选择中所有机器的ew之和、best表示本轮被选中的机器。简单的描述就是每次选择机器列表中cw值最大的机器,被选中机器的cw将会减去tw,从而降低下次被选中的机会,简单的伪代码描述如下:
best = NULL;
tw = 0;
for(i = random() % n; i != i || falg; i = (i + 1) % n) {
flag = 0;
s[i].cw += s[i].ew;
tw += s[i].ew;
if (best == NULL || s[i].cw > best->cw) {
best = &s[i];
}
}
best->cw -= tw;
return best;
请求编号 选择前的权重值 被选中的server 选择后的权重值
0 {5,1,1} A {-2,1,1}
1 {3,2,2} A {-4,2,2}
2 {1,3,3} B {1,-4,3}
3 {6,-3,4} A {-1,-3,4}
4 {4,-2,5} C {4,-2,-2}
5 {9,-1,-1} A {2,-1,-1}
6 {7,0,0} A {0,0,0}
其 SWRR 算法选择的顺序为:{ A, A, B, A, C, A, A }
而普通WRR算法选择的顺序可能为:{ C, B, A, A, A, A, A }
SWRR 相比于普通的WRR算法特点:平滑、分散 。
调高权重引发的血案
从上面的描述来看, SWRR 算法似乎已经比较完美了,但是在某些场景下还是有一定的缺陷,下面我们就一个真实的案列来看看它都有哪些缺陷:
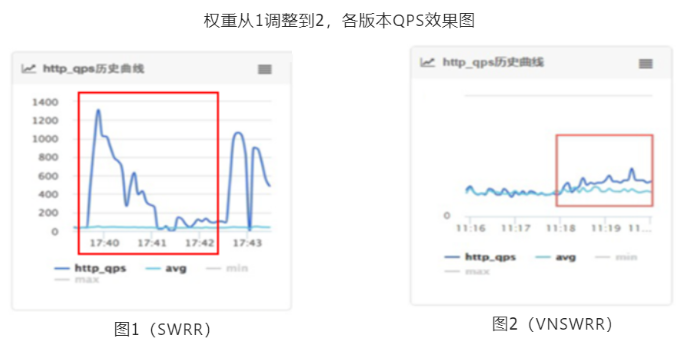
一天早上,流量调度的同学匆忙的跑到我的工位,当时看他神色是尤为的紧张,心想肯定是出啥问题了。果不其然:"为啥我把中心机房某台机器的权重从1调整为2的时候,接入层 Tengine 并不是按照这个权重比例转发流量恩?",当时被调高机器QPS变化趋势如下图所示:
注:其中深蓝色曲线表示权重被调高机器的QPS变化,浅绿色曲线表示该集群单机的平均QPS。

当时看到这个流量趋势变化图的时候也是一脸茫然,不过好在有图有数据,那就可以先分析一下这个图的几个特征数字;由于部分数据敏感,详细数据分析就不在此处展开。直接描述其现象和原因:
被调高权重的机器当时被分发到的流量基本上是该应用机房总流量的1/2,一段时间后该机器的流量才恢复到预期的权重比例。其原因就是由于接入层 Tengine 对后端机器信息的变化是动态感知热生效的,而 Nginx 官方的 SWRR 算法策略第一次会选择当前机器列表中权重最大的机器转发流量。从而进一步导致已感知到后端机器权重变化的接入层 Tengine 都会将第一个请求转发到权重被调高的机器上。
大规模下性能骤降
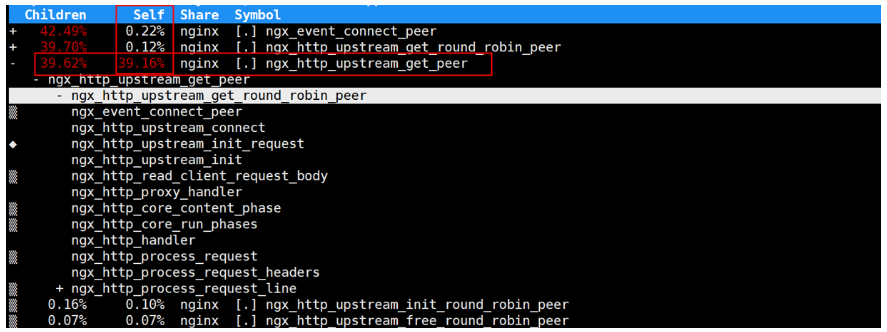
如下是在upstream里面配置2000个后端,在反向代理场景下压测 Nginx 的函数热点图如下所示。其中ngx_http_upstream_get_peer函数CPU消耗占比高达39%,其原因是因为 SWRR 算法的选取机器的时间复杂度为O(N) (其中N代表后端机器数量),这就相当于每个请求都要执行接近2000次循环才能找到对应本次转发的后端机器。
• 压测环境
CPU型号: Intel(R) Xeon(R) CPU E5-2682 v4 @ 2.50GHz
压测工具:./wrk -t25 -d5m -c500 'http://ip/t2000'
Tengine 核心配置:配置2个worker进程,压力源 --长连接--> Tengine / Nginx --短连接--> 后端
下面我们做个试验,控制变量是 upstream 里面配置的 server 数量,观察不同场景下 Nginx 的 QPS 处理能力以及响应时间RT变化情况。从图中可以发现当后端 upstream 里面的 server 数量每增加500台则 Nginx 的 QPS 处理能力下降 10% 左右,响应RT增长 1ms 左右。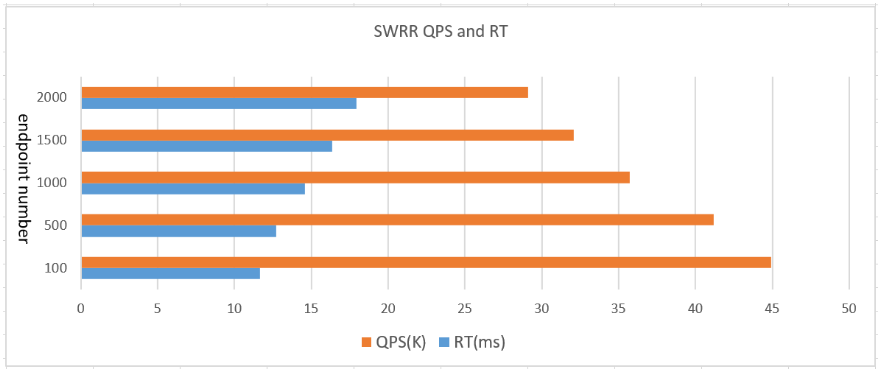
从上面的分析基本上已经确认是 SWRR 算法存在如上两个缺陷,下面就开始解决;
改进的 VNSWRR 算法
虽然经典的WRR算法(如随机数方式实现)可以在时间复杂度上达到 O(1) ,而且也可以避免 SWRR 算法调高权重的选取缺陷。但是在某些场景下(如小流量)可能造成后端的流量不均等问题,尤其是在流量瞬间暴涨的场景下有太多不可确定性。于是就构思是否有一种算法即能拥有 SWRR 算法的平滑、分散特点,又能具备 O(1) 的时间复杂度。所以就有了Virtual Node Smooth Weighted Round-Robin( VNSWRR )算法。
此处拿个列子来说明此算法:3台机器A、B、C权重分别为1、2、3,N代表后端机器数 、TW代表后端机器权重总和。
算法关键点
o 虚拟节点初始化顺序严格按照 SWRR 算法选取,保证初始化列表里的机器能够分布足够散列;
o 虚拟节点运行时分批初始化,避免密集型计算集中。每批次虚拟节点使用完后再进行下一批次虚拟节点列表初始化,每次只初始化min(n, max)个虚拟节点;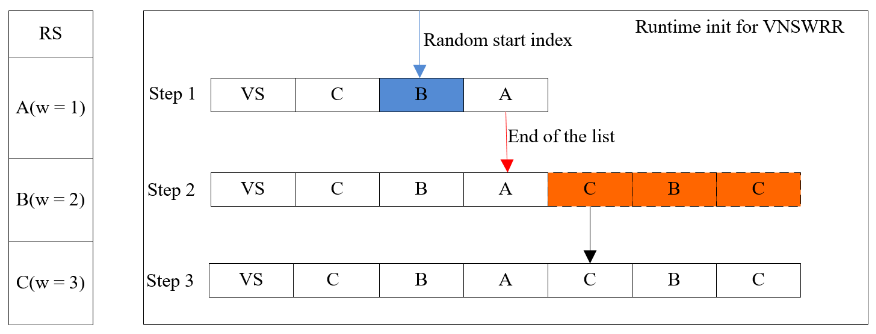
算法描述
o Tengine 程序启动或者运行时感知后端机器信息变化时,则构建TW个虚拟节点且第一次只初始化N个节点(注:TW代表后端机器权重之和,N代表后端机器数);
o 各个进程设置随机起点轮询位置,如上图的Step 1对应的列表其起点位置指向B;
o 当请求到达后从设置的随机起点B位置轮询虚拟节点列表,若轮询到已经初始化的虚拟节点数组的末尾(如上图的Step2红色箭头指向的位置),则初始化第二批虚拟节点(如上图Step2对应的红色节点),当所有虚拟节点初始化完后将不再做初始化工作(如上图的Step3对应的状态);
此方案不仅将算法时间复杂度从 O(N) 优化到 O(1) ,而且也避免了权重调高场景下带来的问题。如下图所示后端某台机器权重从1调整为2后,其QPS平滑的增长到预期比列。
算法效果比较
在同等压测环境下(wrk压测工具、500并发、长连接场景、upstream配置2000个server), Nginx 官方的 SWRR 算法CPU消耗占比高达39%(ngx_http_upstream_get_peer函数)。而 VNSWRR 算法在同等条件下CPU消耗占比只有0.27%左右(ngx_http_upstream_get_ VNSWRR 函数),显而易见 SWRR CPU消耗要高出一个数量级。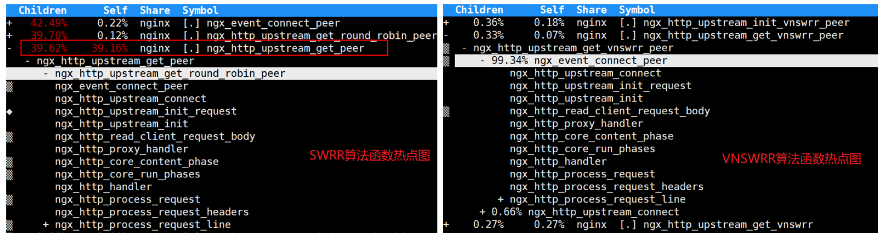
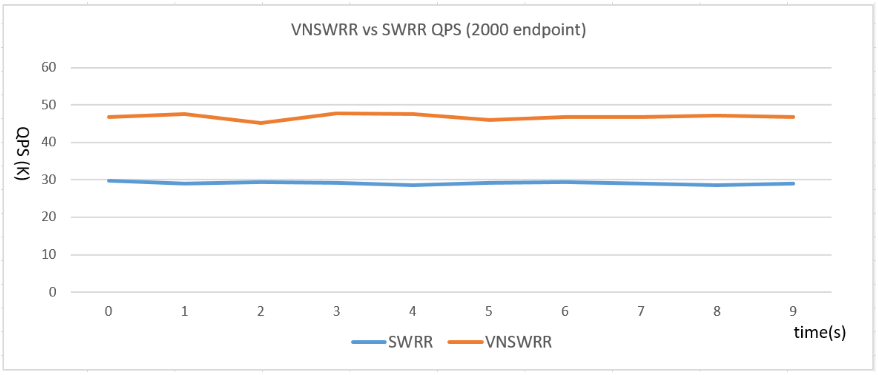
在上述压测环境下, Nginx 官方的 SWRR 和改进的 VNSWRR 算法下的QPS处理能力如下图所示:其中 VNSWRR 的QPS处理能力相对于 SWRR 算法提升60%左右。
下面我们来做个试验,在 upstream 里配置 server 数量变化的场景下,对比 VNSWRR 和 SWRR 算法观察 Nginx 的 QPS 处理能力以及响应时间RT变化。

从图中可以发现在 SWRR 算法下当 upstream 里面的 server 数量每增加500台,则 Nginx 的 QPS 处理能力下降10%左右、响应RT增长1ms左右,而在 VNSWRR 算法下 Tengine 的 QPS 处理能力及RT基本上变化不大。
总结
正是这种大流量场景下才暴露出 Nginx 的一些问题,所谓业务与技术相辅相成,业务可促使新的技术诞生、新的技术赋能创造新的业务。 VNSWRR 算法即拥有 SWRR 算法的平滑、分散特点,也避免了其缺陷。同时在新算法下时间复杂度也从 O(N) 调整为 O(1) ,在大规模场景下 VNSWRR 的QPS处理能力相对于 Nginx 官方的 SWRR 算法提升60%左右。
原文链接
本文为云栖社区原创内容,未经允许不得转载。











