推荐
专栏
教程
课程
飞鹅
本次共找到63条
平行向量
相关的信息
不是海碗
•
2年前
【真正的ChatGPT】APISpace 可以免费快速体验GPT3.5-Turbo
ChatGPT3.5Turbo使用了一种叫做\"DREAM\"的技术,它能为文本语料库中的每个词生成具有向量表示的词嵌入,从而增强机器学习任务的精度。此外,ChatGPT3.5Turbo使用了多监督学习技术,这可以使模型学习更快,并在真实场景中取得更好的收敛效果。
Aidan075
•
4年前
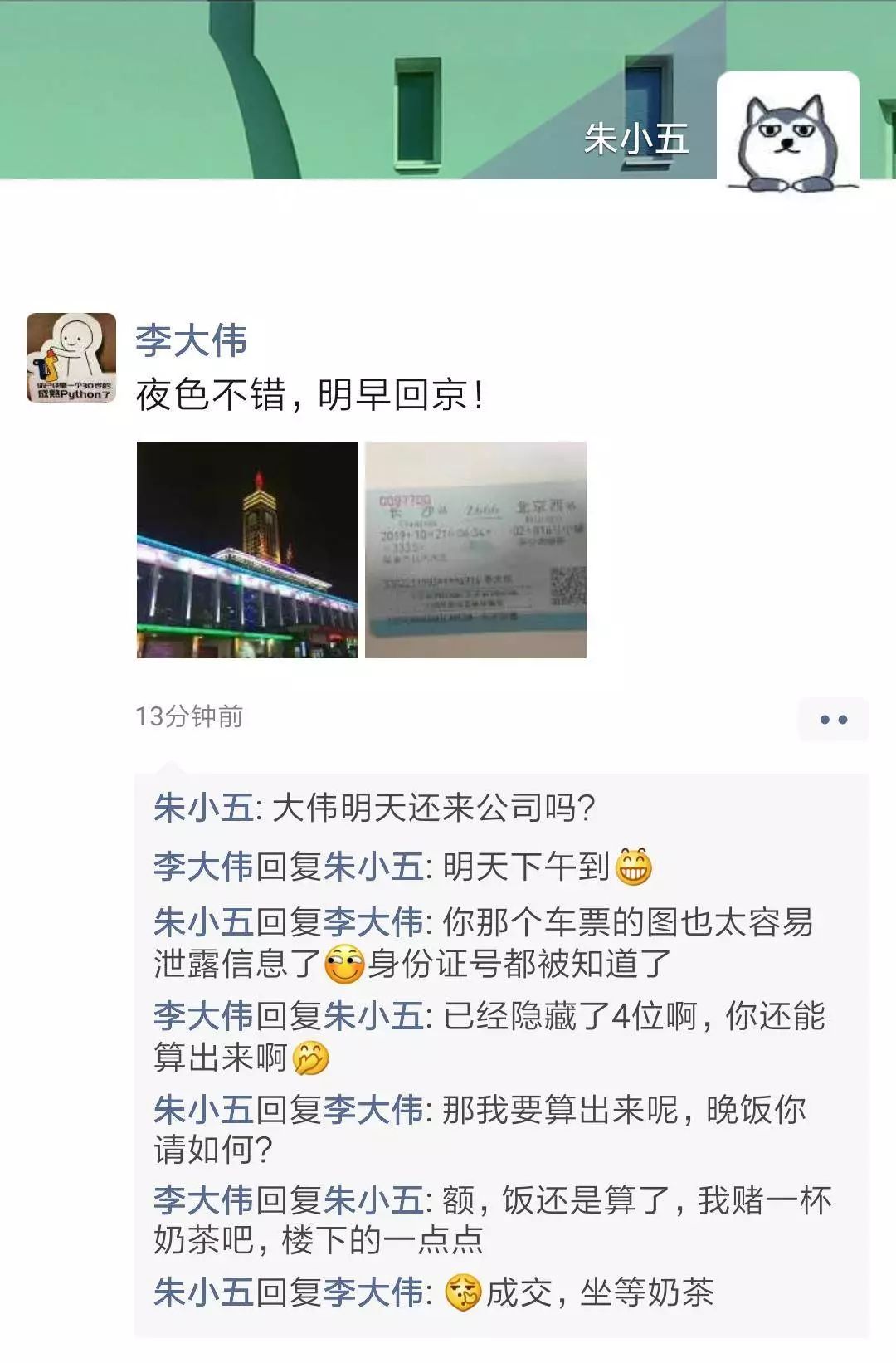
我用python算出了同事的身份证号码!
为了一杯奶茶。事情的经过是这样的:我的同事李大伟最近出差去了。昨晚睡觉前翻了翻朋友圈,就跟他愉快地互怼交流了起来。估计是他想起了我朱小五从不打无把握之赌,后面就怂了。一杯奶茶嘛,也可以接受,像杰伦一样快乐就好啦。开工。先看看李大伟的朋友圈中发的图片。(该火车票来自其他平行世界,扫描可能发生奇怪现象)车票中暴
Stella981
•
4年前
ClickHouse性能测试
对ClickHouse做个简单的性能测试。ClickHouse简介ClickHouse是战斗民族Yandex公司出品的OLAP开源数据库,简称CH,也有人简称CK,是目前市面上最快的OLAP数据库。性能远超Vertica、SybaseIQ等。CH具有以下几个特点:1.列式存储,因此数据压缩比高。2.向量计算
Stella981
•
4年前
OLAP新秀ClickHouse性能测试
对ClickHouse做个简单的性能测试。ClickHouse简介ClickHouse是战斗民族Yandex公司出品的OLAP开源数据库,简称CH,也有人简称CK,是目前市面上最快的OLAP数据库。性能远超Vertica、SybaseIQ等。CH具有以下几个特点:1.列式存储,因此数据压缩比高。2.向量计算,且
Wesley13
•
4年前
KNN分类算法原理分析及代码实现
1、分类与聚类的概念与区别分类:是从一组已知的训练样本中发现分类模型,并且使用这个分类模型来预测待分类样本。目前常用的分类算法主要有:朴素贝叶斯分类算法(NaïveBayes)、支持向量机分类算法(SupportVectorMachines)、KNN最近邻算法(kNearestNeighbors)、神经网络算法(NNet)以及决策树(De
Stella981
•
4年前
Python 操作 mongodb 亿级数据量使用 Bloomfilter 高效率判断唯一性 例子
工作需要使用python处理mongodb数据库两亿数据量去重复,需要在大数据量下快速判断数据是否存在参考资料:https://segmentfault.com/q/1010000000613729网上了解到BloomFilter,Bloomfilter是由HowardBloom在1970年提出的二进制向量数据结构,它具有
Wesley13
•
4年前
unet网络讲解,附代码
转:http://www.cnblogs.com/gujianhan/p/6030639.htmlkey1:FCN对图像进行像素级的分类,从而解决了语义级别的图像分割(semanticsegmentation)问题。与经典的CNN在卷积层之后使用全连接层得到固定长度的特征向量进行分类(全联接层+softmax输出)不同,FCN可以接受任意尺寸的
Stella981
•
4年前
Python+OpenCV图像处理(九)—— 模板匹配
百度百科:模板匹配是一种最原始、最基本的模式识别方法,研究某一特定对象物的图案位于图像的什么地方,进而识别对象物,这就是一个匹配问题。它是图像处理中最基本、最常用的匹配方法。模板匹配具有自身的局限性,主要表现在它只能进行平行移动,若原图像中的匹配目标发生旋转或大小变化,该算法无效。简单来说,模板匹配就是在整个图像区域发现与给定子图像匹配的小块区域。工
京东云开发者
•
2年前
非内积级联学习
1.首页推荐非内积召回现状非内积召回源是目前首页推荐最重要的召回源之一。同时非内积相比于向量化召回最终仅将user和item匹配程度表征为embeding内积,非内积召回仅保留itemembedding,不构造user显式表征,而是通过一个打分网络计算用户
京东云开发者
•
1年前
一种融合指代消解序列标注方法在中文人名识别上的应用(下)
二、使用了BERT模型和指代消解算法:加入BERT语言预处理模型,获取到高质量动态词向量。融入指代消解算法,根据指代词找出符合要求的子串/短语。【2】融入指代消解算法,根据指代词找出符合要求的子串/短语指代消解算法如图2所示,简单来说,就是考虑文档中子串/
1
2
3
4
5
6
7