
从一条更新 SQL 的执行过程窥探 InnoDB 之 REDOLOG
1 前言
数据库为了取得更好的读写性能,InnoDB 会将数据缓存在内存中(InnoDB Buffer Pool),对磁盘数据的修改也会落后于内存,这时如果进程或机器崩溃,会导致内存数据丢失,为了保证数据库本身的一致性和持久性,InnoDB 维护了 REDO LOG。修改 Page 之前需要先将修改的内容记录到 REDO 中,并保证 REDO LOG 早于对应的 Page 落盘,也就是常说的 WAL,Write Ahead Log。当故障发生导致内存数据丢失后,InnoDB 会在重启时,通过重放 REDO,将 Page 恢复到崩溃前的状态。
2 MYSQL 更新语句的执行过程
2.1 MYSQL 的体系结构
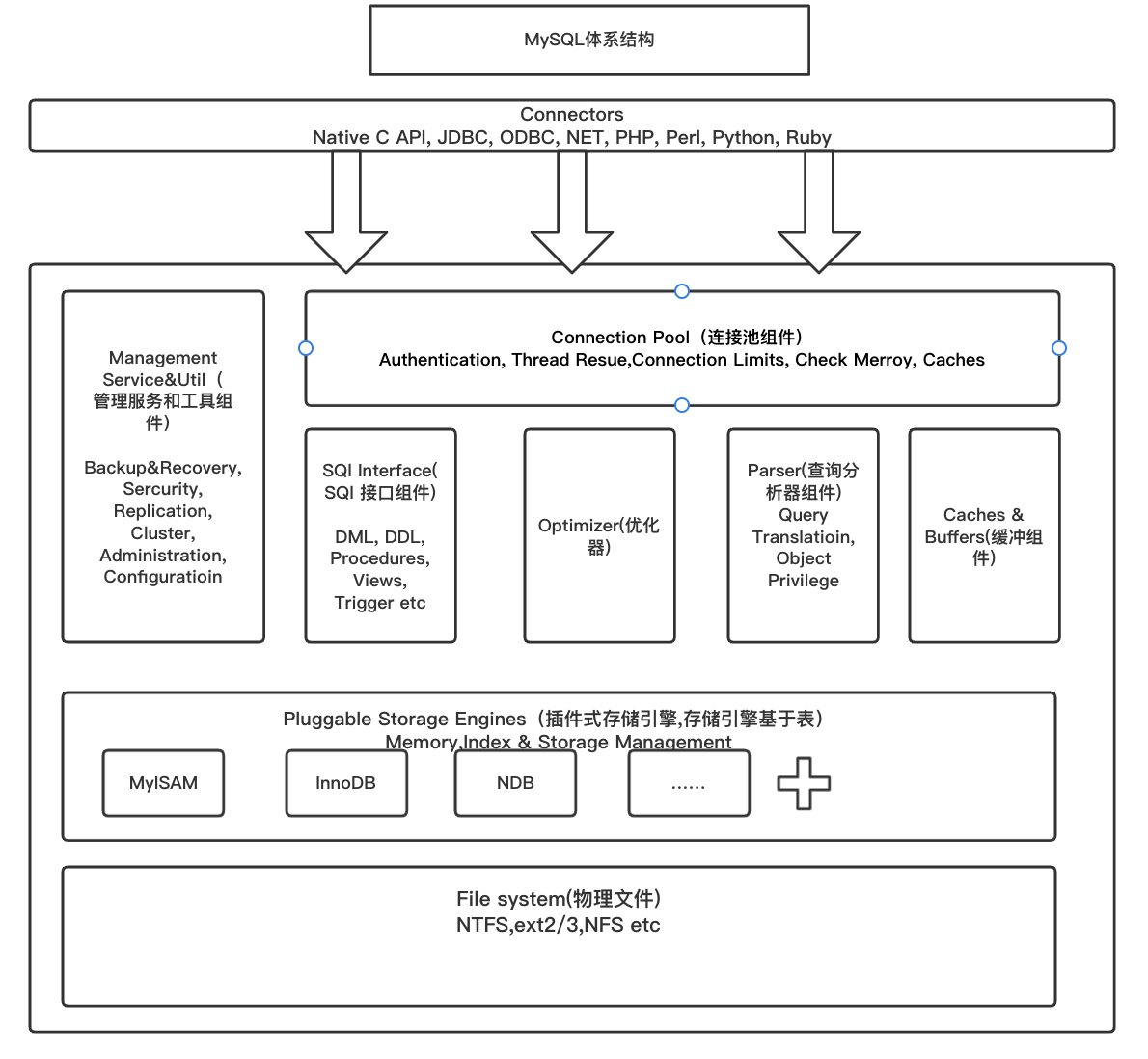
大体来说,MySQL 可以分为 客户端、Server 层和存储引擎层三大部分,如图所示。
Server 层包括连接器、查询缓存、分析器、优化器、执行器等,涵盖 MySQL 的大多数核心服务功能,以及所有的内置函数(如日期、时间、数学和加密函数等),所有跨存储引擎的功能都在这一层实现,比如存储过程、触发器、视图等。
存储引擎层负责数据的存储和提取。其架构模式是插件式的,支持 InnoDB、MyISAM、Memory 等多个存储引擎。现在最常用的存储引擎是 InnoDB,它从 MySQL 5.5.5 版本开始成为了默认存储引擎。
2.2 更新 SQL 的执行
当我们执行一条更新 SQL 时是如何执行的呢,下面执行一条简单的 SQL 更新语句 (默认存储引擎 InnoDB)
update T set c=c+1 where ID=2;
第一步:连接器 先通过连接器连接到这个数据库上。连接器负责跟客户端建立连接、校验用户名密码的正确性,同时获取该用户的权限放到缓存中、维持和管理连接
第二步:缓存 连接建立完成后,如果执行的是 SELECT 查询 语句会查询缓存中是否存在该 SQL 的结果集,如果存在结果则再校验用户表和数据的权限最终将查询到的结果返回。如果是 UPDATE,DELETE 等更新操作,那么跟这个表有关的查询缓存会置为失效,所以这条语句就会把表 T 上所有缓存结果都清空。
第三步:分析器 如果没有命中查询缓存,就要开始真正执行语句了。首先,MySQL 需要知道你要做什么,因此需要对 SQL 语句做解析。 分析器先会做 “词法分析”。你输入的是由多个字符串和空格组成的一条 SQL 语句,MySQL 需要识别出里面的字符串分别是什么,代表什么。例如该语句中 c 列在表 T 中是否存在等。 做完了这些识别以后,就要做 “语法分析”。根据词法分析的结果,语法分析器会根据语法规则,判断你输入的这个 SQL 语句是否满足 MySQL 语法。该 SQL 语句中的 update、where 等是否符合 SQL 语法
第四步:优化器 经过了分析器,MySQL 就知道你要做什么了。在开始执行之前,还要先经过优化器的处理。优化器是在表里面有多个索引的时候,决定使用哪个索引;或者在一个语句有多表关联(join)的时候,决定各个表的连接顺序;优化器决定要使用 ID 这个索引。指定索引也就指定了后面的执行器需要调用存储引擎的哪个接口进行执行。
第五步:执行器 MySQL 通过分析器知道了你要做什么,通过优化器知道了该怎么做,于是就进入了执行器阶段,开始执行语句。开始执行的时候,要先判断一下你对这个表 T 有没有执行查询的权限,如果没有,就会返回没有权限的错误。执行器负责具体执行,找到这一行,然后更新。

2.3 InnoDB 存储引擎引入 REDOLOG
Mysql 本身有自己的日志记录 binlog (归档日志:分为 row,statement,mix 三种模式),但是只依靠 binlog 是没有 crash-safe 能力的,所以在存储引擎层 InnoDB 使用另外一套日志系统 redolog 来实现 crash-safe 能力。同时为了取得更好的读写性能,InnoDB 会将数据缓存在内存中(InnoDB Buffer Pool),对磁盘数据的修改也会落后于内存,这时如果进程或机器崩溃,会导致内存数据丢失,从而保证数据库本身的一致性和持久性。修改 Page 之前需要先将修改的内容记录到 REDO 中,并保证 REDO LOG 早于对应的 Page 落盘,也就是常说的 WAL,Write Ahead Log。当故障发生导致内存数据丢失后,InnoDB 会在重启时,通过重放 REDO,将 Page 恢复到崩溃前的状态。
那么我们需要什么样的 REDO 呢?
首先,REDO 的维护增加了一份写盘数据,同时为了保证数据正确,事务只有在他的 REDO 全部落盘才能返回用户成功,REDO 的写盘时间会直接影响系统吞吐,显而易见,REDO 的数据量要尽量少。其次,系统崩溃总是发生在始料未及的时候,当重启重放 REDO 时,系统并不知道哪些 REDO 对应的 Page 已经落盘,因此 REDO 的重放必须可重入,即 REDO 操作要保证幂等。最后,为了便于通过并发重放的方式加快重启恢复速度,REDO 应该是基于 Page 的,即一个 REDO 只涉及一个 Page 的修改。 数据量小是 Logical Logging 的优点,而幂等以及基于 Page 正是 Physical Logging 的优点。InnoDB 采取了一种称为 Physiological Logging 的方式,来兼得二者的优势。所谓 Physiological Logging,就是以 Page 为单位,但在 Page 内以逻辑的方式记录。举个例子,一种作用于 Page 类型的 REDOLOG 中记录了对 Page 中一个 Record 的修改,方法如下:
(Page ID,Record Offset,(Filed 1, Value 1) … (Filed i, Value i) … )
其中,PageID 指定要操作的 Page 页,Record Offset 记录了 Record 在 Page 内的偏移位置,后面的 Field 数组,记录了需要修改的 Field 以及修改后的 Value。
2.4 REDOLOG 的记录内容
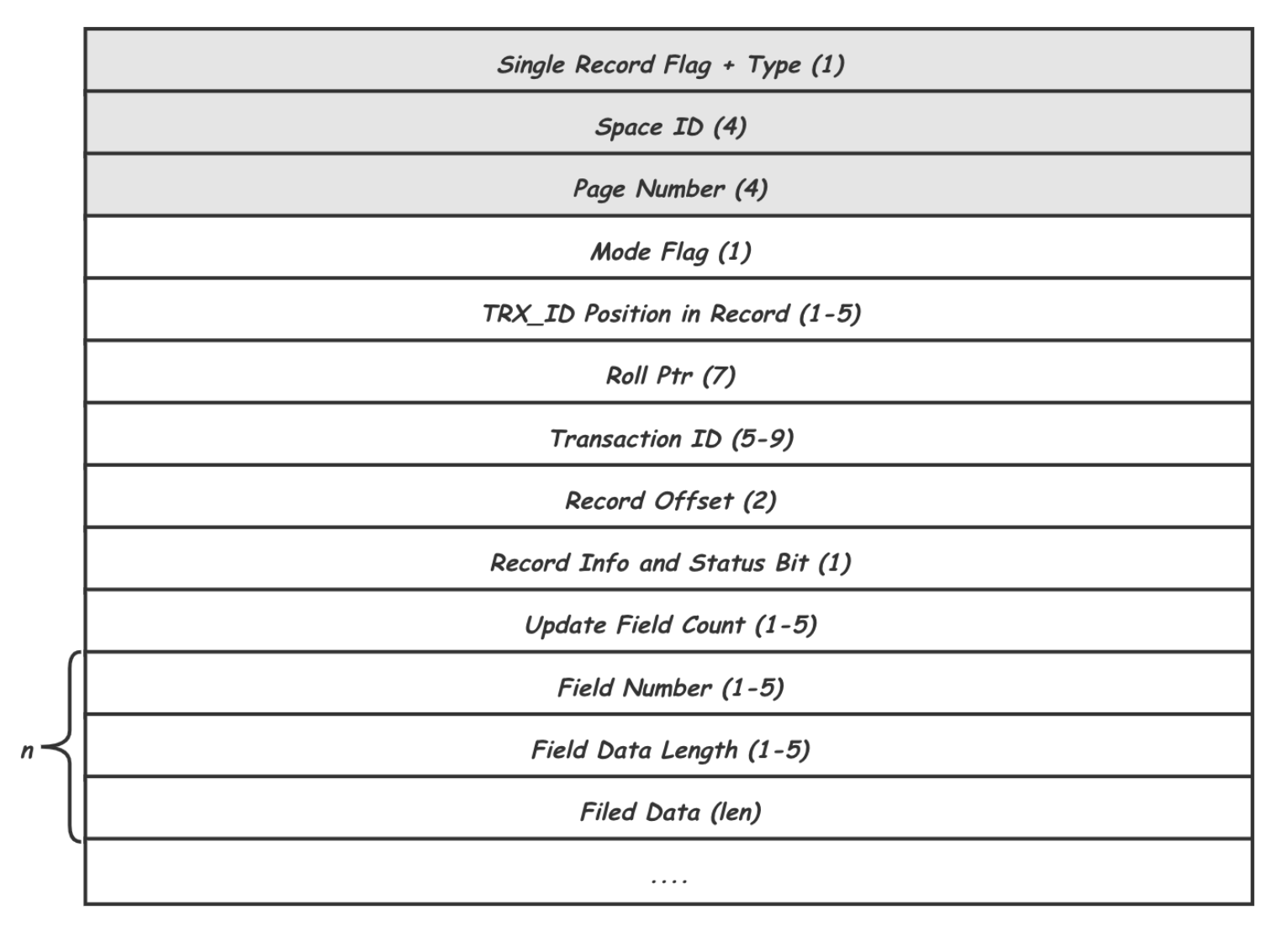
其中 Type 就是记录的作用对象 (根据 REDO 记录不同的作用对象,可划分为三个大类:作用于 Page,作用于 Space 以及提供额外信息的 Logic 类型),Space ID 和 Page Number 唯一标识一个 Page 页,这三项是所有 REDO 记录都需要有的头信息。
后面的是 MLOG_REC_UPDATE_IN_PLACE 类型 (作用于 Page) 独有的,其中 Record Offset 用给出要修改的记录在 Page 中的位置偏移,Update Field Count 说明记录里有几个 Field 要修改,紧接着对每个 Field 给出了 Field 编号 (Field Number),数据长度(Field Data Length)以及数据(Filed Data)
3 总结
通过对一个更新 SQl 语句执行过程的跟踪,了解熟悉 Mysql 的执行过程,了解 REDOLOG 的数据的内容格式,从根本上理解 REDOLOG 的设计的思路和原理,为以后的应用系统的开发和设计提供思想上的借鉴和实践,感兴趣的可以在3A的服务器上部署一套自己尝试练习一下。




