一、Innodb Buffer Pool 简介
==========================
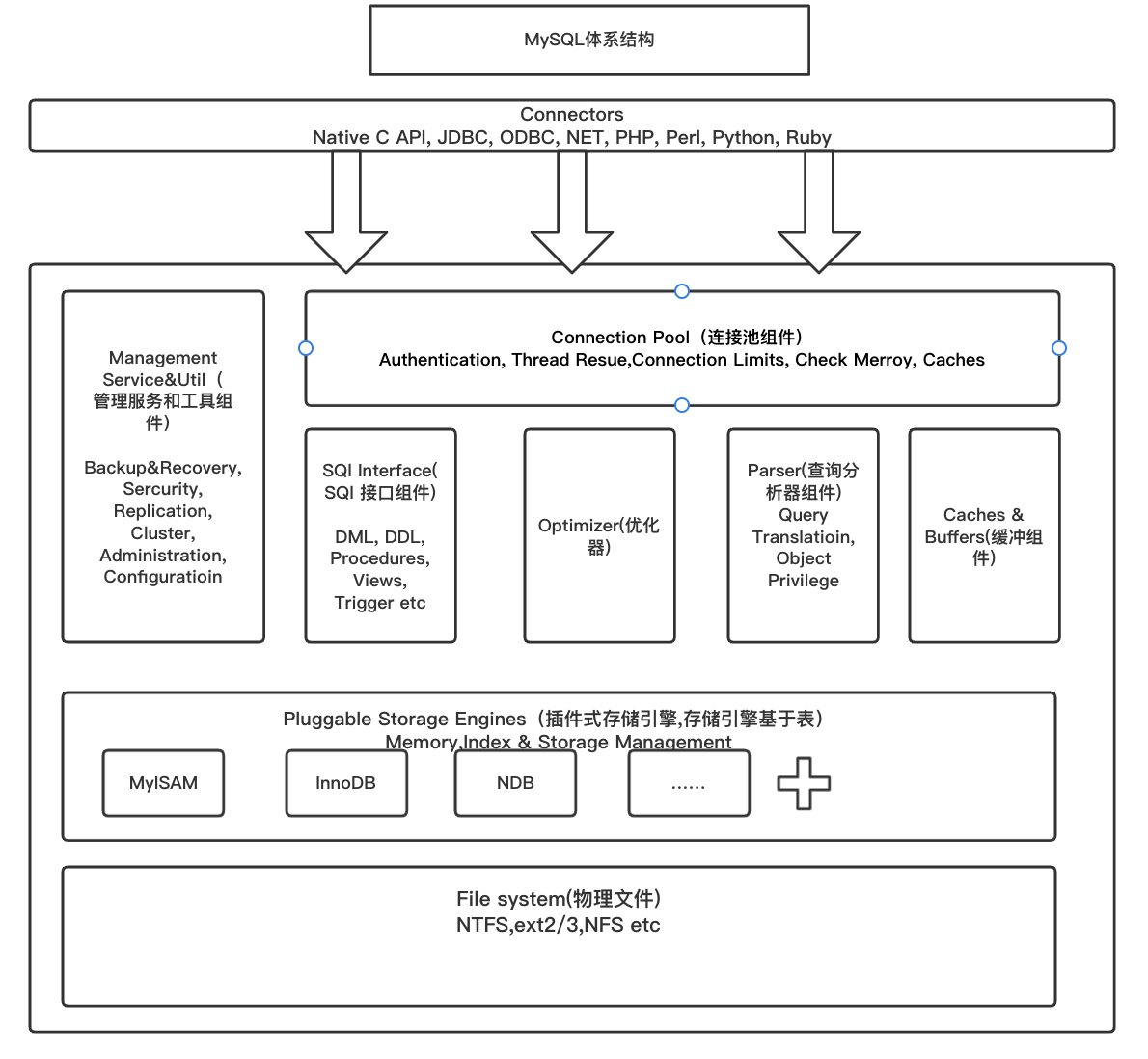
Buffer Pool 是Innodb 内存中的的一块占比较大的区域,用来缓存表和索引数据。众所周知,从内存访问会比从磁盘访问快很多。为了提高数据的读取速度,Buffer Pool 会通过三种Page 和链表来管理这些经常访问的数据,保证热数据不被置换出Buffer Pool。
本文只针对三种Page和链表展开讲解。
二、三种Page
Buffer Pool 是按照Page大小来分配,受innodb_page_size控制。
1. Free Page(空闲页)
此Page 未被使用,位于 Free 链表
2. Clean Page(干净页)
此Page 已被使用,但是页面未发生修改,位于LRU 链表。
3. Dirty Page(脏页)
此Page 已被使用,页面已经被修改,其数据和磁盘上的数据已经不一致。当脏页上的数据写入磁盘后,内存数据和磁盘数据一致,那么该Page 就变成了干净页。脏页 同时存在于LRU 链表和Flush 链表。
三、三种链表
1. LRU 链表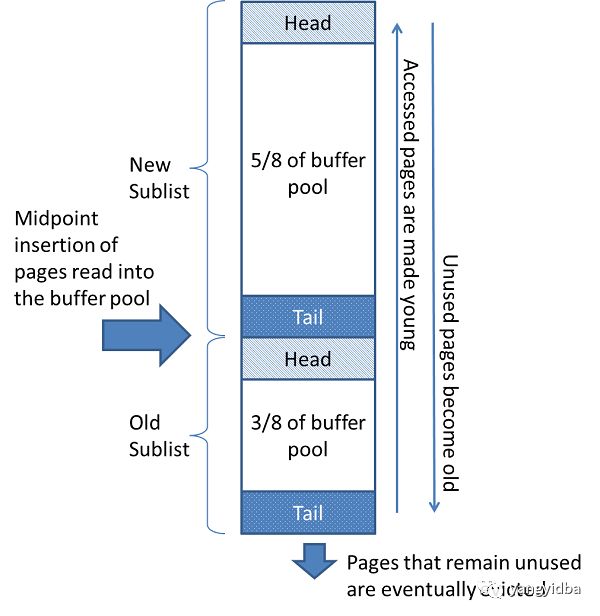
如上图所示,是Buffer Pool里面的LRU(least recently used)链表。LRU链表是被一种叫做最近最少使用的算法管理。
LRU链表被分成两部分,一部分是New Sublist(Young 链表),用来存放经常被读取的页的地址,另外一部分是Old Sublist(Old 链表),用来存放较少被使用的页面。每部分都有对应的头部 和尾部。
默认情况下
Old 链表占整个LRU 链表的比例是3/8。该比例由innodb_old_blocks_pct控制,默认值是37(3/8*100)。该值取值范围为5~95,为全局动态变量。
当新的页被读取到Buffer Pool里面的时候,和传统的LRU算法插入到LRU链表头部不同,Innodb LRU算法是将新的页面插入到Yong 链表的尾部和Old 链表的头部中间的位置,这个位置叫做Mid Point,如上图所示。
频繁访问一个Buffer Pool的页面,会促使页面往Young链表的头部移动。如果一个Page在被读到Buffer Pool后很快就被访问,那么该Page会往Young List的头部移动,但是如果一个页面是通过预读的方式读到Buffer Pool,且之后短时间内没有被访问,那么很可能在下次访问之前就被移动到Old List的尾部,而被驱逐了。
随着数据库的持续运行,新的页面被不断的插入到LRU链表的Mid Point,Old 链表里的页面会逐渐的被移动Old链表的尾部。同时,当经常被访问的页面移动到LRU链表头部的时候,那些没有被访问的页面会逐渐的被移动到链表的尾部。最终,位于Old 链表尾部的页面将被驱逐。
如果一个数据页已经处于Young 链表,当它再次被访问的时候,只有当其处于Young 链表长度的1/4(大约值)之后,才会被移动到Young 链表的头部。这样做的目的是减少对LRU 链表的修改,因为LRU 链表的目标是保证经常被访问的数据页不会被驱逐出去。
innodb_old_blocks_time 控制的Old 链表头部页面的转移策略。该Page需要在Old 链表停留超过innodb_old_blocks_time 时间,之后再次被访问,才会移动到Young 链表。这么操作是避免Young 链表被那些只在innodb_old_blocks_time时间间隔内频繁访问,之后就不被访问的页面塞满,从而有效的保护Young 链表。
在全表扫描或者全索引扫描的时候,Innodb会将大量的页面写入LRU 链表的Mid Point位置,并且只在短时间内访问几次之后就不再访问了。设置innodb_old_blocks_time的时间窗口可以有效的保护Young List,保证了真正的频繁访问的页面不被驱逐。
innodb_old_blocks_time 单位是毫秒,默认值是1000。调大该值提高了从Old链表移动到Young链表的难度,会促使更多页面被移动到Old 链表,老化,从而被驱逐。
当扫描的表很大,Buffer Pool都放不下时,可以将innodb_old_blocks_pct设置为较小的值,这样只读取一次的数据页就不会占据大部分的Buffer Pool。例如,设置innodb_old_blocks_pct = 5,会将仅读取一次的数据页在Buffer Pool的占用限制为5%。
当经常扫描一些小表时,这些页面在Buffer Pool移动的开销较小,我们可以适当的调大innodb_old_blocks_pct,例如设置innodb_old_blocks_pct = 50。
在SHOW ENGINE INNODB STATUS 里面提供了Buffer Pool一些监控指标,有几个我们需要关注一下:
youngs/s:该指标表示的是每秒访问Old 链表中页面,使其移动到Young链表的次数。如果MySQL实例都是一些小事务,没有大表全扫描,且该指标很小,就需要调大innodb_old_blocks_pct 或者减小innodb_old_blocks_time,这样会使得Old List 的长度更长,Old页面被移动到Old List 的尾部消耗的时间会更久,那么就提升了下一次访问到Old List里面的页面的可能性。如果该指标很大,可以调小innodb_old_blocks_pct,同时调大innodb_old_blocks_time,保护热数据。
non-youngs/s:该指标表示的是每秒访问Old 链表中页面,没有移动到Young链表的次数,因为其不符合innodb_old_blocks_time。如果该指标很大,一般情况下是MySQL存在大量的全表扫描。如果MySQL存在大量全表扫描,且这个指标又不大的时候,需要调大innodb_old_blocks_time,因为这个指标不大意味着全表扫描的页面被移动到Young 链表了,调大innodb_old_blocks_time时间会使得这些短时间频繁访问的页面保留在Old 链表里面。
每隔1秒钟,Page Cleaner线程执行LRU List Flush的操作,来释放足够的Free Page。innodb_lru_scan_depth 变量控制每个Buffer Pool实例每次扫描LRU List的长度,来寻找对应的脏页,执行Flush操作。
2. Flush 链表
Flush 链表里面保存的都是脏页,也会存在于LRU 链表。
Flush 链表是按照oldest_modification排序,值大的在头部,值小的在尾部
当有页面访被修改的时候,使用mini-transaction,对应的page进入Flush 链表
如果当前页面已经是脏页,就不需要再次加入Flush list,否则是第一次修改,需要加入Flush 链表
当Page Cleaner线程执行flush操作的时候,从尾部开始scan,将一定的脏页写入磁盘,推进检查点,减少recover的时间
3. Free 链表
Free 链表 存放的是空闲页面,初始化的时候申请一定数量的页面
在执行SQL的过程中,每次成功load 页面到内存后,会判断Free 链表的页面是否够用。如果不够用的话,就flush LRU 链表和Flush 链表来释放空闲页。如果够用,就从Free 链表里面删除对应的页面,在LRU 链表增加页面,保持总数不变。
四. LRU 链表和Flush链表的区别
LRU 链表 flush,由用户线程触发(MySQL 5.6.2之前);而Flush 链表 flush由MySQL数据库InnoDB存储引擎后台srv_master线程处理。(在MySQL 5.6.2之后,都被迁移到Page Cleaner线程中)。
LRU 链表 flush,其目的是为了写出LRU 链表尾部的脏页,释放足够的空闲页,当Buffer Pool满的时候,用户可以立即获得空闲页面,而不需要长时间等待;Flush 链表 flush,其目的是推进Checkpoint LSN,使得InnoDB系统崩溃之后能够快速的恢复。
LRU 链表 flush,其写出的脏页,需要从LRU链表中删除,移动到Free 链表。Flush List flush,不需要移动page在LRU链表中的位置。
LRU 链表 flush,每次flush的脏页数量较少,基本固定,只要释放一定的空闲页即可;Flush 链表 flush,根据当前系统的更新繁忙程度,动态调整一次flush的脏页数量,量很大。
在Flush 链表上的页面一定在LRU 链表上,反之则不成立。
五. 触发刷脏页的条件
REDO日志快用满的时候。由于MySQL更新是先写REDO日志,后面再将数据Flush到磁盘,如果REDO日志对应脏数据还没有刷新到磁盘就被覆盖的话,万一发生Crash,数据就无法恢复了。此时会从Flush 链表里面选取脏页,进行Flush。
为了保证MySQL中的空闲页面的数量,Page Cleaner线程会从LRU 链表尾部淘汰一部分页面作为空闲页。如果对应的页面是脏页的话,就需要先将页面Flush到磁盘。
MySQL中脏页太多的时候。innodb_max_dirty_pages_pct 表示的是Buffer Pool最大的脏页比例,默认值是75%,当脏页比例大于这个值时会强制进行刷脏页,保证系统有足够可用的Free Page。innodb_max_dirty_pages_pct_lwm参数控制的是脏页比例的低水位,当达到该参数设定的时候,会进行preflush,避免比例达到innodb_max_dirty_pages_pct 来强制Flush,对MySQL实例产生影响。
MySQL实例正常关闭的时候,也会触发MySQL把内存里面的脏页全部刷新到磁盘。
Innodb 的策略是在运行过程中尽可能的多占用内存,因此未被使用的页面会很少。当我们读取的数据不在Buffer Pool里面时,就需要申请一个空闲页来存放。如果没有足够的空闲页时,就必须从LRU 链表的尾部淘汰页面。如果该页面是干净的,可以直接拿来用,如果是脏页,就需要进行刷脏操作,将内存数据Flush到磁盘。
所以,如果出现以下情况,是很容易影响MySQL实例的性能:
一个SQL查询的数据页需要淘汰的页面过多
实例是个写多型的MySQL,checkpoint跟不上日志产生量,会导致更新全部堵塞,TPS跌0。
innodb_io_capacity 参数定义了Innodb 后台任务的IO能力,例如刷脏操作还有Change Buffer的merge操作等。
六、 总结
Innodb 的三种Page和链表的设计,保证了我们需要的热数据常驻在内存,及时淘汰不需要的数据,提升了我们的查询速度,同时不同的刷脏策略也提高了我们的恢复速度,保证了数据安全。
参考文章:
http://www.zhdba.com/mysqlops/2012/06/11/mysql-innodb-buffer-pool-flush-list/
https://dev.mysql.com/doc/refman/5.7/en/innodb-buffer-pool.html
https://dev.mysql.com/doc/refman/5.7/en/innodb-buffer-pool-flushing.html
https://www.xaprb.com/blog/2011/01/29/how-innodb-performs-a-checkpoint/
推荐阅读
技术分享|delete 语句引发大量 sql 被kill 问题分析
本文发布于 《深入理解MySQL 主从原理32讲》

-The End-
本公众号长期关注于数据库技术以及性能优化,故障案例分析,数据库运维技术知识分享,个人成长和自我管理等主题,欢迎扫码关注。


扫码加入MySQL技术Q群
(群号:****650149401)

点“在看”给我一朵小黄花

本文分享自微信公众号 - 老叶茶馆(iMySQL_WX)。
如有侵权,请联系 support@oschina.cn 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。