推荐
专栏
教程
课程
飞鹅
本次共找到2892条
td处理
相关的信息
helloworld_46188038
•
4年前
pid_max的分析和修改
pid\max内核源码处理分析以linux3.2.6为例子分析init/main.c:asmlinkagevoidinitstartkernel(void)kernel/pid.c:voidinitpidmapinit(void)voidinitpidmapinit(void)/bumpdefaultandmi
Wesley13
•
4年前
Java Lambda 常用案例
List类的Stream处理:List<StringlistnewArrayList<String();list.add("djk");list.add("djk1");list.add("djk12");//maplistlist.stream().ma
Stella981
•
4年前
OpenCV+Python 文字识别(重点图像透视变换)
1Author:WinterLiuiscoming!2importcv2ascv3importnumpyasnp4importpytesseract567预处理,高斯滤波(用处不大),4次开操作8过滤轮廓唯一
Wesley13
•
4年前
C++异常的几种捕获方式
捕获指定的类型这样的话可以对每种异常做出不同的处理,例如:include<iostreamusingnamespacestd;voidA(intn){inta1;floatb0.2;doublec0.3;
秋桐
•
2年前
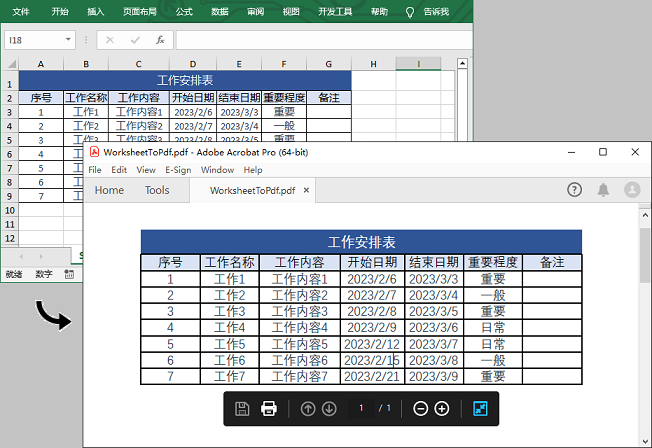
通过Java程序将Excel转换为PDF文档格式
Excel广泛应用于商业、教育等众多领域,具有丰富的数据处理和分析功能,包括计算、图表、排序、筛选、数据透视表等。在处理大型数据内容时,Excel绝对是最佳工具。但如果要将处理好的数据内容进行保存和传输的话,转换为PDF文档格式或许更加可靠。PDF文档的稳定布局可以避免数据内容被随意更改,即使是在多次传输后也能保证数据的准确性。将Excel转换为PDF的工具有很多。这里我将介绍如何通过编程的方法来实现该功能。以Java代码为例,使用到的产品是FreeSpire.XLSforJava(免费版)。下面是程序环境和示例代码。
天翼云开发者社区
•
1年前
一条数据包从收到发--交换芯片篇(一)
从程控交换设备的软处理到交换芯片的硬件pipeline,从基于dpdk的软件转发到可编程的pipeline硬转发,从Kbps带宽能力到Tbps能力,网络转发设备的发展带来大带宽能力的同时,其技术架构也是经历了软硬软硬的周期,可谓完美演绎了“十年河东十年河西”“各领风骚数年”的传奇。但对于底层网络而言,其七层架构、数据包结构、协议标准基本没有变化,即对于网络转发设备而言,数据报文处理架构可以做通用设计抽象,转发细节的差异与演进大多体现在报文处理逻辑的优化,内部报文高速传递的优化等。
贾蔷
•
6个月前
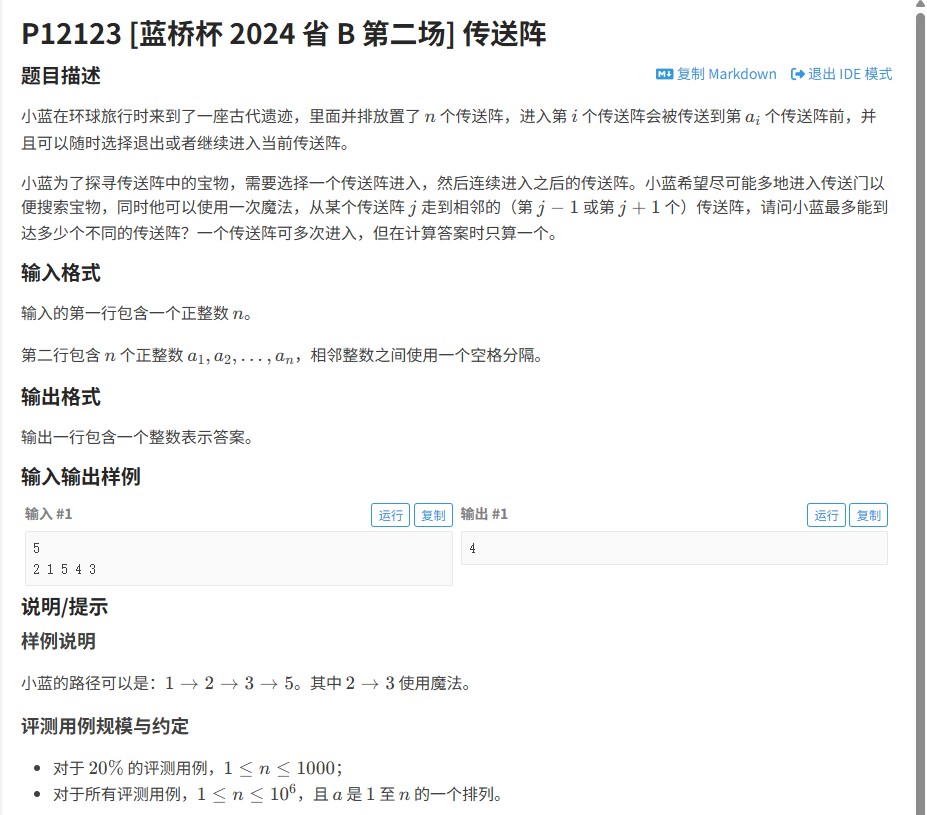
2024蓝桥杯省赛B组“传送阵”题解
一、题目解读2024年省B组“传送阵”题目要求处理一个包含n个节点的,节点间存在单向传输关系。每个节点i可传送至a中的最长路径问题,需考虑环的存在及节点间的连通性。二、解题思路1.预处理阶段使用标记法找出所有环,记录每个环的大小(即节点数)。2.统计最大环
LeeFJ
•
3年前
Foxnic-SQL (1) —— 快速入门(QuickStart)
<aname"k9Sn5"</aFoxnicSQL(1)——简介<aname"XffCP"</a概述FoxnicSQL是基于SpringJDBC开发的SQL语句执行与数据处理框架。她扩展
菜园前端
•
2年前
为什么要学习数据结构和算法?
原文链接:为什么要学习数据结构和算法?它对我们开发和程序有什么帮助?像我们平常都是使用框架和库进行开发的项目的,我们也不太可能去修改库和框架的内部代码,那我们应该如何优化我们的程序,要从哪方面入手呢?可以通过数据处理的操作进行优化,数据处理就会涉及到数据结
数据堂
•
2年前
语音识别技术发展的驱动力:语音数据的采集和处理
语音识别技术是一项基于人工智能的技术,通过计算机对人的语音进行分析和处理,将语音转化成文字,以此达到自动化处理的目的。语音识别技术的应用广泛,包括智能助手、语音导航、语音搜索、电话自动语音应答等等。但是要实现高质量的语音识别,一个非常重要的因素就是语音数据
1
•••
81
82
83
•••
290