推荐
专栏
教程
课程
飞鹅
本次共找到1269条
sql分组
相关的信息
九路
•
5年前
Gradle系列之三 Gradle概述以及生命周期
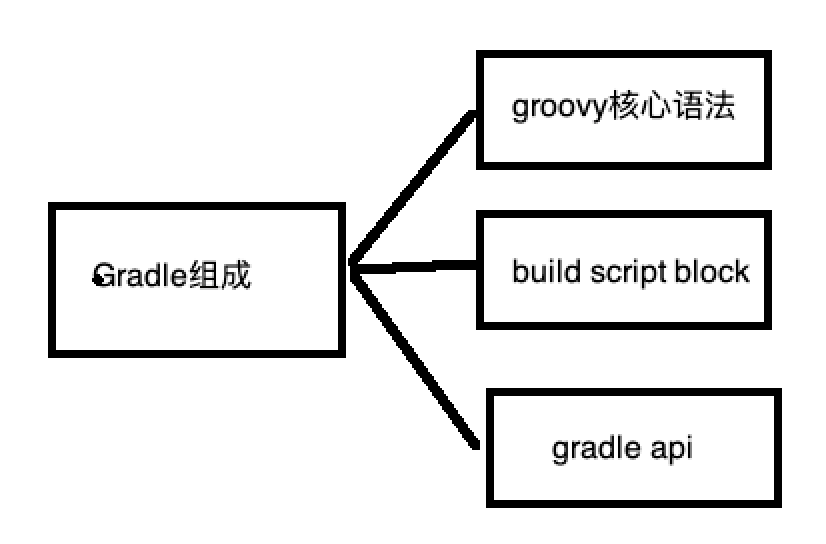
1Gradle是一种编程框架gradle主要由以下三部分组成1groovy核心语法2buildscriptblock3gradleapi注:本章所有的代码都在https://github.com/jiulu313/gradledemo.git如下图73485499237410.png(https://img
Wesley13
•
4年前
SQL 拼音搜索
【个人收藏】1.将汉字转拼音首字母自定义FunctiondropfunctionF_GET_PINYINCREATEORREPLACEFUNCTIONF_GET_PINYIN(P_NAMEINVARCHAR2)RETURNVARCHAR2ASV_COMPAREVARCHAR2(50);
Easter79
•
4年前
sql子查询
子查询可以返回各种不同类型的信息标量子查询返回一个值;(最严格的,适用范围也最大)列子查询返回一个由一个值或多个值构成的列;行子查询返回一个由一个值或多个值构成的行;表子查询返回一个由一个行或多个行构成的表,而行则由一个或多个列构成。带关
Stella981
•
4年前
SQL on Hadoop性能对比-Hive、Spark SQL、Impala
1三种语言、三套工具、三个架构不了解SQLonHadoop三驾马车-Hive、SparkSQL、Impala吗?听小编慢慢道来1HiveApacheHive数据仓库软件提供对存储在分布式中的大型数据集的查询和管理,它本
Wesley13
•
4年前
DruidParser
最近用阿里的Druid的SQLparser来解析SQL语句。在此记录下研究:调用它来解析出AST语意树一般这么写(针对MySQL):MySqlStatementParserparsernewMySqlStatementParser(sql);List<SQLStatementstatementListpars
Easter79
•
4年前
SQL on Hadoop性能对比-Hive、Spark SQL、Impala
1三种语言、三套工具、三个架构不了解SQLonHadoop三驾马车-Hive、SparkSQL、Impala吗?听小编慢慢道来1HiveApacheHive数据仓库软件提供对存储在分布式中的大型数据集的查询和管理,它本
Stella981
•
4年前
Spark 二次排序
遇到这样的场景,有一个文本里的字段是:日期,名字,数据。需要对名字和日期进行排序,大概的思路就是先将名字排序(其实准确来说是分组),再将日期排序。可以使用下面的方案。文本605370582021505150546051代码importorg.
Wesley13
•
4年前
ORACLE WITH AS 语法
一种SQL查询方法,颠覆日常以select开始的SQL查询写法createtablet(xnumber(10),ynumber(10));insertintotvalues(1,110);insertintotvalues(2,120);insertintotvalues(2,80);i
Wesley13
•
4年前
MySQL:如何查询出每个分组中的 top n 条记录?
问题描述!(https://oscimg.oschina.net/oscnet/34eb581c2f09dd6b3d0942cdf8428c671d6.jpg)需求:查询出每月order_amount(订单金额)排行前3的记录。例如对于201902,查询结果中就应该是这3条:!(https://os
LeeFJ
•
3年前
Foxnic-SQL (2) —— SQL表达式(Expr)
<aname"imPZx"</aFoxnicSQL(2)——SQL表达式(Expr)<aname"YN2qk"</a<aname"oZ9br"</a常规意义的表达式表达式
1
•••
15
16
17
•••
127