
子查询可以返回各种不同类型的信息
- 标量子查询返回一个值;(最严格的,适用范围也最大)
- 列子查询返回一个由一个值或多个值构成的列;
- 行子查询返回一个由一个值或多个值构成的行;
- 表子查询返回一个由一个行或多个行构成的表,而行则由一个或多个列构成。
带关系比较运算符的子查询
运算符:=、<>、>、>=、< 和 <= 。
-- 一般的子查询,有时候为了满足返回一个值的要求,可以使用 LIMIT 1 来限制
SELECT * FROM president
WHERE brith = (SELECT min(brith) FROM president);
-- 使用一个行构造器来实现一组值(即元组)与子查询结果的比较
-- ROW(city,state) 等价于 (city,state)
SELECT last_name,first_name,city,state FROM president
WHERE (city,state) = (
SELECT city,state FROM president WHERE last_name='Adam' AND first_name='John'
);
IN 和 NOT IN 子查询
-- 查询有缺勤记录的学生
SELECT * FROM student WHERE student_id
IN (SELECT student_id FROM absence);
-- 查询没有缺勤记录的学生
SELECT * FROM student WHERE student_id
NOT IN (SELECT student_id FROM absence);
-- 也可以使用行构造器来指定与各列进行比较
SELECT last_name,first_name,city,state FROM president
WHERE (city,state) IN (
SELECT city,state FROM president
WHERE last_name = 'Roosevelt'
);
ALL、ANY 和 SOME 子查询
IN 和 NOT IN 是 = ANY 和 <> ALL 的缩写
-- 检索最早出生的总统
SELECT last_name,first_name,brith FROM president
WHERE brith <= ALL (SELECT brith FROM president);
-- 行构造器
SELECT last_name,first_name,city,state FROM president
WHERE (city,state) = ANY (
SELECT city,state FROM president WHERE last_name = 'Roosevelt'
);
EXISTS 和 NOT EXISTS 子查询
-- 根据子查询是否返回了行来判断真假,并不关心行所包含的具体内容,所以使用 select 1
SELECT exists(SELECT 1 FROM absence);
SELECT NOT exists(SELECT 1 FROM absence);
相关子查询
-- 不相关的子查询不会引用外层查询里的值,因此它自己可以作为一条的单独查询命令去执行
SELECT j FROM t2 WHERE j IN (SELECT i FROM t1);
-- 相关子查询则引用了外层查询里的值,所以它也就依赖于外层查询。
-- 通常用在 EXISTS 和 NOT EXISTS 子查询里
SELECT j FROM t2 WHERE (SELECT i FROM t1 WHERE i = j);
FROM 子句里的子查询
-- 子查询可以用在 FROM 子句里,以生成某些值。
SELECT * FROM (SELECT 1,2) AS t1 INNER JOIN (SELECT 3,4) AS t2;
将子查询改写为连接
-- 改写用来查询匹配值的子查询
SELECT * FROM score
WHERE student_id IN (SELECT student_id FROM student WHERE sex='F');
-- 改写成
SELECT score.* FROM score INNER JOIN student
ON score.student_id = student.student_id WHERE student.sex = 'F';
-- 改写用来查询非匹配(缺失)值的子查询
SELECT * FROM student
WHERE student_id NOT IN (SELECT student_id FROM absence);
-- 改写成
SELECT student.*
FROM student LEFT JOIN absence ON student.student_id = absence.student_id
WHERE absence.student_id IS NULL ;
使用 UNION 实现多表检索
-- UNION 有以下几种特性:
-- ①、列名和数据类型:UNION 结果集里的列名来自于第一个 SELECT 里的列名
SELECT i1,c1 FROM t1 UNION SELECT i2,c2 FROM t2;
SELECT i1,c1 FROM t1 UNION SELECT c2,i2 FROM t2;
-- ②、重复行处理:默认情况下,UNION 会将结果集里的重复行剔除掉
SELECT * FROM t1 UNION SELECT * FROM t2;
-- 如果想保留重复的行,则需要把所有的 UNION 改为 UNION ALL
SELECT * FROM t1 UNION ALL SELECT * FROM t2;
-- ③、ORDER BY 和 LIMIT 处理
-- 注意:order by 只能引用第一个 select 语句里的列名
(SELECT i1,c1 FROM t1 LIMIT 1) UNION (SELECT i2,c2 FROM t2 LIMIT 2)
ORDER BY c1
LIMIT 2;
一、mysql查询的五种子句
where(条件查询)、having(筛选)、group by(分组)、order by(排序)、limit(限制结果数)
1、where常用运算符:
比较运算符:
> , < ,= , != (< >),>= ,<=
in(v1,v2..vn)
between v1 and v2 在v1至v2之间(包含v1,v2)
逻辑运算符:
not ( ! ) 逻辑非
or ( || ) 逻辑或
and ( && ) 逻辑与
where price>=3000 and price <= 5000 or price >=500 and price <=1000
取500-1000或者3000-5000的值
where price not between 3000 and 5000
不在3000与5000之间的值
模糊查询:
like
regexp
通配符:
% 任意字符
_ 单个字符
where goods_name like '诺基亚%'
where goods_name like '诺基亚N__'
2、group by 分组
一般情况下group需与统计函数(聚合函数)一起使用才有意义
如,表goods:

取出每个栏目下最高价格的商品:
select goods_id,goods_name,cat_id,max(shop_price) from goods group by cat_id;

这里取出来的结果中的goods_id,goods_name是错误的!因为shop_price使用了max函数,那么它是取最大的,而语句中使用了group by 分组,而goods_id,goods_name并没有使用聚合函数,它只是cat_id下的第一个商品,并不会因为shop_price改变而改变。
mysql中的五种统计函数:
(1)max:求最大值
select max(shop_price) from goods; 这里会取出最大的价格的值,只有值

例:查询每个栏目下价格最高(最贵)的商品
select * from goods where shop_price in(
select max(shop_price) from goods group by cat_id
); 因为max函数结合group by就能取出分组下的最大值

但是注意,上面不能写成:
select *,max(shop_price) from goods where shop_price in(select max(shop_price) from goods group by cat_id);
因为只会显示出价格为4999的记录,因为:
上句相当于select *,max(shop_price) from goods where shop_price in(4600,2800,588,4300,3300);
查询结果为:

意思是对in中的数据求最大值,并将其所有字段列出来。
而select * from goods where shop_price in(4600,2800,588,4300,3300);查询结果为:
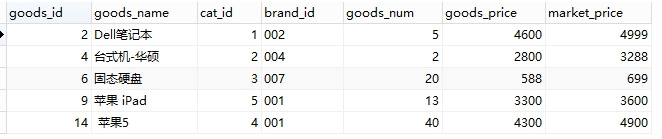
注意上面两句查询的区别。
还有一种方法,查询每个栏目下最贵的商品:
先对每个栏目下的商品按栏目升序、价格降序
select cat_id,goods_id,goods_name,goods_price from goods order by cat_id,goods_price desc;

上面的查询结果中每个栏目的第一行的商品就是最贵的商品,把上面的查询结果理解为一个临时表[存在于内存中]【子查询】,再从临时表中选出每个栏目最贵的商品
select * from (select cat_id,goods_id,goods_name,goods_price from goods order by cat_id,goods_price desc) as t group by cat_id;

这里使用group by cat_id是因为临时表中每个栏目的第一个商品就是最贵的商品,而group by前面没有使用聚合函数,所以默认就取每个分组的第一行数据,这里以cat_id分组。
(2)min:求最小值
(3)sum:求总数和
mysql> select sum(shop_price) from goods;
+-----------------+
| sum(shop_price) |
+-----------------+
| 16383.00 |
+-----------------+
(4)avg:求平均值
mysql> select cat_id,avg(shop_price) from goods group by cat_id;
求每个栏目的商品平均价格
+--------+-----------------+
| cat_id | avg(shop_price) |
+--------+-----------------+
| 1 | 4499.000000 |
| 2 | 2943.500000 |
| 3 | 549.500000 |
+--------+-----------------+
(5)count:求总行数
mysql> select cat_id,count(*) from goods group by cat_id;
求每个栏目下商品种类
+--------+----------+
| cat_id | count(*) |
+--------+----------+
| 1 | 2 |
| 2 | 2 |
| 3 | 2 |
+--------+----------+
要把每个字段名当成变量来理解,它可以进行运算
例:查询本店每个商品价格比市场价低多少;
select goods_id,goods_name,goods_price-market_price from goods;
例:查询每个栏目下面积压的货款
select cat_id,sum(goods_price*goods_number) from goods group by cat_id;
可以用as来给计算结果取个别名
mysql> select cat_id,sum(shop_price * cat_id) as hk from goods group by cat_id;
+--------+----------+
| cat_id | hk |
+--------+----------+
| 1 | 8998.00 |
| 2 | 11774.00 |
| 3 | 3297.00 |
+--------+----------+
不仅列名可以取别名,表单也可以取别名
3、having 与where 的异同点
where针对表中的列发挥作用,查询数据
having对查询结果中的列发挥作用,筛选数据
例:查询本店商品价格比市场价低多少钱,输出低200元以上的商品
select goods_id,goods_name,market_price - goods_price as s from goods having s>200 ;

这里不能用where因为s是查询结果,而where只能对表中的字段名筛选,如果用where的话则是:
select goods_id,goods_name from goods where market_price - goods_price > 200;

同时使用where与having:
select cat_id,goods_name,market_price - goods_price as s from goods where cat_id = 2 having s > 500;

例:查询积压货款超过2万元的栏目,以及该栏目积压的货款
mysql> select cat_id,sum(goods_price * goods_num) as s from goods group by cat_id having s > 20000;
+--------+----------+
| cat_id | s |
+--------+----------+
| 1 | 57500.00 |
| 2 | 29600.00 |
+--------+----------+
例:查询两门及两门以上科目不及格的学生的平均分
先建表、添加数据
mysql> select * from stuscore;
+----+------+---------+-------+
| id | name | subject | score |
+----+------+---------+-------+
| 1 | 张静 | 语文 | 45 |
| 2 | 张静 | 数学 | 67 |
| 3 | 张静 | 英语 | 87 |
| 4 | 张静 | 物理 | 76 |
| 5 | 张静 | 化学 | 87 |
| 6 | 王壮 | 语文 | 67 |
| 7 | 王壮 | 数学 | 89 |
| 8 | 王壮 | 英语 | 78 |
| 9 | 王壮 | 物理 | 98 |
| 10 | 王壮 | 化学 | 87 |
| 11 | 刘都 | 语文 | 88 |
| 12 | 刘都 | 数学 | 43 |
| 13 | 刘都 | 英语 | 56 |
| 14 | 刘都 | 物理 | 43 |
| 15 | 刘都 | 化学 | 57 |
| 16 | 周灵 | 语文 | 59 |
| 17 | 周灵 | 数学 | 54 |
| 18 | 周灵 | 英语 | 98 |
| 19 | 周灵 | 物理 | 60 |
| 20 | 周灵 | 化学 | 69 |
| 21 | 李歌 | 语文 | 90 |
| 22 | 李歌 | 数学 | 73 |
| 23 | 李歌 | 英语 | 59 |
| 24 | 李歌 | 物理 | 71 |
| 25 | 李歌 | 化学 | 69 |
+----+------+---------+-------+
-- 每个学生的平均分
mysql> select name,avg(score) as avgScore from stuscore group by name;
+------+----------+
| name | avgScore |
+------+----------+
| 刘都 | 57.4 |
| 周灵 | 68 |
| 张静 | 72.4 |
| 李歌 | 72.4 |
| 王壮 | 83.8 |
+------+----------+
-- 查出所有学生的挂科情况
mysql> select name,score<60 from stuscore;
+------+----------+
| name | score<60 |
+------+----------+
| 张静 | 1 |
| 张静 | 0 |
| 张静 | 0 |
| 张静 | 0 |
| 张静 | 0 |
| 王壮 | 0 |
| 王壮 | 0 |
| 王壮 | 0 |
| 王壮 | 0 |
| 王壮 | 0 |
| 刘都 | 0 |
| 刘都 | 1 |
| 刘都 | 1 |
| 刘都 | 1 |
| 刘都 | 1 |
| 周灵 | 1 |
| 周灵 | 1 |
| 周灵 | 0 |
| 周灵 | 0 |
| 周灵 | 0 |
| 李歌 | 0 |
| 李歌 | 0 |
| 李歌 | 1 |
| 李歌 | 0 |
| 李歌 | 0 |
+------+----------+
-- 查出两门及两门以上不及格的学生
mysql> select name,sum(score<60) as gk from stuscore group by name having gk > 1;
+------+------+
| name | gk |
+------+------+
| 刘都 | 4 |
| 周灵 | 2 |
+------+------+
-- 综合结果
mysql> select name,sum(score<60) as gk,avg(score) as pj from stuscore group by name having gk >1;
+------+------+------+
| name | gk | pj |
+------+------+------+
| 刘都 | 4 | 57.4 |
| 周灵 | 2 | 68 |
+------+------+------+
4、order by
(1)order by price,order by price asc //默认升序排列
(2)order by price desc //降序排列
(3)order by rand() //随机排列,效率不高
例:按栏目号升序排列,每个栏目下的商品价格降序排列
select * from goods where cat_id !=2 order by cat_id,goods_price desc;

5、limit
limit [offset,] N
offset 偏移量,可选,不写则相当于limit 0,N
N 取出条目
例:取价格第4-6条的商品
select goods_id,goods_name,goods_price from goods order by goods_price desc;

select goods_id,goods_name,goods_price from goods order by goods_price desc limit 3,3;

良好的理解模型:
1、where后面的表达式,把表达式放在每一行中,看是否成立
2、字段(列),理解为变量,可以进行运算(算术运算和逻辑运算)
3、 取出结果可以理解成一张临时表
二、mysql子查询
1、where型子查询(把内层查询结果当作外层查询的比较条件)
例:查询最新的商品mysql> select goods_id,goods_name from goods where goods_id = (select max(goods_id) from goods);
+----------+------------+
| goods_id | goods_name |
+----------+------------+
| 6 | 固态硬盘 |
+----------+------------+
例:查询每个栏目下最新的产品(goods_id唯一)
mysql> select cat_id,goods_id,goods_name from goods where goods_id in(select max(goods_id) from goods group by cat_id);
+--------+----------+-------------+
| cat_id | goods_id | goods_name |
+--------+----------+-------------+
| 1 | 2 | Dell笔记本 |
| 2 | 4 | 台式机-华硕 |
| 3 | 6 | 固态硬盘 |
+--------+----------+-------------+
2、from型子查询(把内层的查询结果供外层再次查询)
例:用子查询查出挂科两门及以上的同学的平均成绩
-- 先查出哪些同学挂科两门以上
mysql> select name,count(*) as gk from stuscore where score < 60 group by name having gk >=2; -- group by语句不能放在where语句前面
+------+----+
| name | gk |
+------+----+
| 刘都 | 4 |
| 周灵 | 2 |
+------+----+
-- 以上查询结果,我们只要名字就可以了,所以再取一次名字
mysql> select name from (select name,count(*) as gk from stuscore where score < 60 group by name having gk >=2) as t;
+------+
| name |
+------+
| 刘都 |
| 周灵 |
+------+
-- 找出这些同学了,那么再计算他们的平均分
mysql> select name,avg(score) from stuscore where name in (
select name from (select name,count(*) as gk from stuscore where score < 60
group by name having gk >=2) as t
) group by name;
+------+------------+
| name | avg(score) |
+------+------------+
| 刘都 | 57.4 |
| 周灵 | 68 |
+------+------------+
3、exists型子查询(把外层查询结果拿到内层,看内层的查询是否成立)
例:查询哪些栏目下有商品,栏目表category,商品表goods
mysql> select cat_id,cat_name from category where exists(select * from goods where goods.cat_id = category.cat_id);
+--------+----------+
| cat_id | cat_name |
+--------+----------+
| 1 | 笔记本 |
| 2 | 台式机 |
| 3 | 硬盘 |
+--------+----------+
三、union的用法
把两次或多次的查询结果合并起来,要求查询的列数一致,推荐查询的对应的列类型一致,可以查询多张表,多次查询语句时如果列名不一样,则取第一次的列名!如果不同的语句中取出的行的每个列的值都一样,那么结果将自动会去重复,如果不想去重复则要加all来声明,即union all。
现有表a如下:
id num
a 5
b 10
c 15
d 10
表b如下:
id num
b 5
c 10
d 20
e 99
例:求两个表中id相同的和
mysql> select * from a union select * from b;
+----+------+
| id | num |
+----+------+
| a | 5 |
| b | 10 |
| c | 15 |
| d | 10 |
| b | 5 |
| c | 10 |
| d | 20 |
| e | 99 |
+----+------+
mysql> select id,sum(num) from (select * from a union select * from b) as tmp group by id;
+----+----------+
| id | sum(num) |
+----+----------+
| a | 5 |
| b | 15 |
| c | 25 |
| d | 30 |
| e | 99 |
+----+----------+
以上查询结果在本例中的确能正确输出结果,但是,如果把表b中的b的值改为10后查询结果的b的值就是10了,因为表a中的b也是10,所以union后会被过滤掉一个重复的结果,这时就要用union all
mysql> select * from a union all select * from b;
+----+------+
| id | num |
+----+------+
| a | 5 |
| b | 10 |
| c | 15 |
| d | 10 |
| b | 10 |
| c | 10 |
| d | 20 |
| e | 99 |
+----+------+
mysql> select id,sum(num) from (select * from a union all select * from b)
as tmp group by id;
+----+----------+
| id | sum(num) |
+----+----------+
| a | 5 |
| b | 20 |
| c | 25 |
| d | 30 |
| e | 99 |
+----+----------+
例:取第4、5栏目的商品,按栏目升序排列,每个栏目的商品价格降序排列,用union完成
mysql> select goods_id,goods_name,cat_id,goods_price from goods where cat_id=4 union
select goods_id,goods_name,cat_id,goods_price from goods where cat_id=5
order by cat_id,goods_price desc;
+----------+----------------+--------+-------------+
| goods_id | goods_name | cat_id | goods_price |
+----------+----------------+--------+-------------+
| 7 | 诺基亚1520 | 4 | 4000.00 |
| 8 | 诺基亚920 | 4 | 2400.00 |
| 9 | 苹果 iPad | 5 | 3300.00 |
| 10 | 微软 Surface 2 | 5 | 3100.00 |
+----------+----------------+--------+-------------+
如果不用union,则更简单:
select goods_id,goods_name,cat_id,goods_price from goods where cat_id=4 or cat_id=5 order by cat_id,goods_price desc;
【如果子句中有order by 需要用( ) 包起来,但是推荐在最后使用order by,即对最终合并后的结果来排序】
例:取第3、4个栏目,每个栏目价格最高的前3个商品,结果按价格降序排列
mysql> (select goods_id,goods_name,cat_id,goods_price from goods where cat_id=3 order by goods_price desc limit 3) union
-> (select goods_id,goods_name,cat_id,goods_price from goods where cat_id=4 order by goods_price desc limit 3)
-> order by goods_price desc;
+----------+------------+--------+-------------+
| goods_id | goods_name | cat_id | goods_price |
+----------+------------+--------+-------------+
| 14 | 苹果5 | 4 | 4300.00 |
| 7 | 诺基亚1520 | 4 | 4000.00 |
| 13 | 苹果4S | 4 | 3000.00 |
| 6 | 固态硬盘 | 3 | 588.00 |
| 5 | 移动硬盘 | 3 | 320.00 |
| 12 | U盘-16G | 3 | 70.00 |
+----------+------------+--------+-------------+
四、左连接,右连接,内连接
现有表a有4条数据,表b有4条数据,那么表a与表b的笛尔卡积是多少?
mysql> select * from a,b; 输出结果为4*4=16条
+----+------+----+------+
| id | num | id | num |
+----+------+----+------+
| a | 5 | b | 10 |
| b | 10 | b | 10 |
| c | 15 | b | 10 |
| d | 10 | b | 10 |
| a | 5 | c | 10 |
| b | 10 | c | 10 |
| c | 15 | c | 10 |
| d | 10 | c | 10 |
| a | 5 | d | 20 |
| b | 10 | d | 20 |
| c | 15 | d | 20 |
| d | 10 | d | 20 |
| a | 5 | e | 99 |
| b | 10 | e | 99 |
| c | 15 | e | 99 |
| d | 10 | e | 99 |
+----+------+----+------+
1、左连接
以左表为准,去右表找数据,如果没有匹配的数据,则以null补空位,所以输出结果数>=左表原数据数
语法:select n1,n2,n3 from ta left join tb on a.n1= b.n2 [这里on后面的表达式,不一定为=,也可以>,<等算术、逻辑运算符]【连接完成后,可以当成一张新表来看待,运用where等查询】
例:取出价格最高的五个商品,并显示商品的分类名称
现在的goods表如下,已将goods_price按降序排列:

mysql> select goods_id,goods_name,goods.cat_id,cat_name,goods_price from goods left join category
-> on goods.cat_id = category.cat_id order by goods_price desc limit 5;
+----------+------------+--------+----------+-------------+
| goods_id | goods_name | cat_id | cat_name | goods_price |
+----------+------------+--------+----------+-------------+
| 2 | Dell笔记本 | 1 | 笔记本 | 4600.00 |
| 14 | 苹果5 | 4 | 手机 | 4300.00 |
| 7 | 诺基亚1520 | 4 | 手机 | 4000.00 |
| 1 | 联想笔记本 | 1 | 笔记本 | 3450.00 |
| 9 | 苹果 iPad | 5 | 平板电脑 | 3300.00 |
+----------+------------+--------+----------+-------------+
2、右连接
a left join b 等价于 b right join a
推荐使用左连接代替右连接
语法:select n1,n2,n3 from a right join b on a.n1= b.n2
3、内连接
查询结果是左右连接的交集,【即左右连接的结果去除null项后的并集(去除了重复项)】
mysql目前还不支持外连接(即左右连接结果的并集,不去除null项)
语法:select n1,n2,n3 from a inner join b on a.n1= b.n2
例:现有表a
+----+------+
| id | num |
+----+------+
| a | 12 |
| b | 10 |
| c | 15 |
+----+------+
表b:
+----+------+
| id | num |
+----+------+
| d | 12 |
| e | 10 |
| f | 10 |
| g | 8 |
+----+------+
例:表a左连接表b,查询num相同的数据
mysql> select a.*,b.* from a left join b on a.num = b.num;
+----+------+------+------+
| id | num | id | num |
+----+------+------+------+
| a | 12 | d | 12 |
| b | 10 | e | 10 |
| b | 10 | f | 10 |
| c | 15 | NULL | NULL |
+----+------+------+------+
从上面可以看出,查询结果表a的列都存在,表b的数据只显示符合条件的项目
例:表b左连接表a,查询num相同的数据;a右连接表b,查询num相同的数据----这两种查询结果相同:
mysql> select a.*,b.* from b left join a on a.num = b.num;
mysql> select a.*,b.* from a right join b on a.num = b.num;
+------+------+----+------+
| id | num | id | num |
+------+------+----+------+
| a | 12 | d | 12 |
| b | 10 | e | 10 |
| b | 10 | f | 10 |
| NULL | NULL | g | 8 |
+------+------+----+------+
例:查询商品的名称,所属分类,所属品牌
先查看更改后的表结构:
表goods:

表category:

表brand:

select goods_id,goods_name,goods.cat_id,goods.brand_id,category.cat_name,brand.brand_name from goods left join category
on goods.cat_id = category.cat_id left join brand on goods.brand_id = brand.brand_id limit 5;

理解:每一次连接之后的结果都可以看作是一张新表
例:创建两张表,表m记录比赛信息,表t记录球队信息
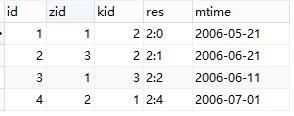
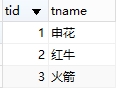
要求查询出2006-0601至2006-07-01期间的比赛结果:
select m.*,t.* from m left join t on m.zid = t.tid;

select zid,t1.tname as t1name,res,kid,t2.tname as t2name,mtime from m left join t as t1 on m.zid = t1.tid
left join t as t2 on m.kid = t2.tid;

select zid,t1.tname as t1name,res,kid,t2.tname as t2name,mtime from m left join t as t1 on m.zid = t1.tid
left join t as t2 on m.kid = t2.tid where mtime between '2006-06-01' and '2006-07-01';

总结:可以对同一张表连接多次,以分别取多次数据
1、Oracle的子查询的概述
什么是子查询?
子查询是指嵌入在其他SQL语句中的SELECT语句,也称之为嵌套查询。
可以使用子查询的位置:where、select列表、having、from。
a、在where子句中使用子查询
示例:查询出和FORD是相同职位的员工:select * from emp where job = (select job from emp where ename='FORD');
SQL> select * from emp where job = (select job from emp where ename='FORD'); EMPNO ENAME JOB MGR HIREDATE SAL COMM DEPTNO 7951 EASON ANALYST 7566 01-12月-17 3000 20 7788 SCOTT ANALYST 7566 19-4月 -87 3000 20 7902 FORD ANALYST 7566 03-12月-81 3000 20b、在select子句中使用子查询
示例:查询出每个部门的编号、名称、位置和部门人数。示例:select deptno, dname, loc, (select count(empno) from emp where emp.deptno = dept.deptno) count from dept;
SQL> select deptno, dname, loc, (select count(empno) from emp where emp.deptno = dept.deptno) count from dept; DEPTNO DNAME LOC COUNT 10 ACCOUNTING NEW YORK 3 20 RESEARCH DALLAS 6 30 SALES CHICAGO 6 40 OPERATIONS BOSTON 0c、在having子句中使用子查询
举例:查询员工信息表,按照部门编号进行分组,要求显示员工的部门编号、平均工资,查询条件时平均工资大于30号部门的最高工资。
SQL> select deptno, avg(sal) from emp group by deptno having avg(sal) > (select max(sal) from emp where deptno = 30); DEPTNO AVG(SAL) 10 2916.66667d、在from子句中使用子查询
把子查询的结果看成一张新的表。示例:查询并显示高于部门平均工资的雇员信息。
SQL> select ename, job, sal from emp, (select deptno, avg(sal) avgsal from emp group by deptno) dept where emp.deptno = dept.deptno and sal > avgsal; ENAME JOB SAL EASON ANALYST 3000 ALLEN SALESMAN 1600 JONES MANAGER 2975 BLAKE MANAGER 2850 SCOTT ANALYST 3000 KING PRESIDENT 5000 FORD ANALYST 3000 已选择7行。2、Oracle的主查询和子查询
什么是主查询和子查询?
a、一个主查询可以有多个子查询
举例:显示职位和7521的职位相同并工资大于7934这个员工工资的员工信息。
SQL> select * from emp where job = (select job from emp where empno = 7521) and sal > (select sal from emp where empno = 7934); EMPNO ENAME JOB MGR HIREDATE SAL COMM DEPTNO 7499 ALLEN SALESMAN 7698 20-2月 -81 1600 300 30 7844 TURNER SALESMAN 7698 08-9月 -81 1500 0 30b、子查询的执行顺序
一般先执行子查询,再执行主查询,但相关子查询例外。
举例:查询员工表中小于平均工资的员工信息。
SQL> select empno, ename, sal from emp where sal < (select avg(sal) from emp); EMPNO ENAME SAL 7369 G_EASON 800 7499 ALLEN 1600 7521 WARD 1250 7654 MARTIN 1250 7844 TURNER 1500 7876 ADAMS 1100 7900 JAMES 950 7934 MILLER 1300 已选择8行。c、相关子查询
当子查询需要引用主查询的表列时,Oracle会执行相关查询。
相关子查询是先执行主查询,在执行子查询。
示例:查询工资高于部门平均工资的雇员名、工资和部门号:
SQL> select ename, sal, deptno from emp e where sal > (select avg(sal) from emp where deptno = e.deptno); ENAME SAL DEPTNO EASON 3000 20 ALLEN 1600 30 JONES 2975 20 BLAKE 2850 30 SCOTT 3000 20 KING 5000 10 FORD 3000 20 已选择7行。d、主查询和子查询可以不是同一张表
主查询和子查询可以查询的不是同一张表。
示例:查询部门名称时ACCOUNTING的员工信息。
SQL> select * from emp where deptno = (select deptno from dept where dname='ACCOUNTING'); EMPNO ENAME JOB MGR HIREDATE SAL COMM DEPTNO 7782 CLARK MANAGER 7839 09-6月 -81 2450 10 7839 KING PRESIDENT 17-11月-81 5000 10 7934 MILLER CLERK 7782 23-1月 -82 1300 103、Oracle的子查询:单行子查询
子查询的类型:单行子查询和多行子查询。
单行子查询:只返回一行数据的子查询语句。
使用单行比较操作符:
操作符
含义
=
等于
>
大于
>=
大于等于
<
小于
<=
小于等于
<>
不等于
a、使用单行子查询
示例1:显示与JAMES同部门的所有其他的员工姓名、工资、部门号。
SQL> select ename, sal, deptno from emp where deptno = (select deptno from emp where ename='JAMES') AND ename <> 'JAMES'; ENAME SAL DEPTNO- ALLEN 1600 30 WARD 1250 30 MARTIN 1250 30 BLAKE 2850 30示例2:查询大于等于公司平均工资的员工的姓名、职位、工资。
SQL> select ename, job, sal from emp where sal >= (select avg(sal) from emp); ENAME JOB SAL EASON ANALYST 3000 JONES MANAGER 2975 BLAKE MANAGER 2850 CLARK MANAGER 2450 SCOTT ANALYST 3000 KING PRESIDENT 5000 FORD ANALYST 3000 已选择7行。示例3:查询部门名称不是‘SAVE’的员工。
SQL> select * from emp where deptno <> (select deptno from dept where dname= 'SALES'); EMPNO ENAME JOB MGR HIREDATE SAL COMM DEPTNO 7951 EASON ANALYST 7566 01-12月-17 3000 20 ...... 7902 FORD ANALYST 7566 03-12月-81 3000 20 7934 MILLER CLERK 7782 23-1月 -82 1300 10 已选择9行。b、非法使用单行子查询
示例:select ename, job, sal from emp where sal = (select max(sal) from emp group by deptno);
SQL> select ename, job, sal from emp where sal = (select max(sal) from emp group by deptno); select ename, job, sal from emp where sal = (select max(sal) from emp group by deptno) 第 1 行出现错误: ORA-01427: 单行子查询返回多个行select max(sal) from emp group by deptno;sql语句返回多行数据。
SQL> select max(sal) from emp group by deptno; MAX(SAL) 2850 3000 50004、Oracle的子查询:多行子查询
多行子查询是指返回多行数据的子查询语句。
使用多行比较操作符:(使用多行子查询时必须使用多行比较操作符。)
运算符
含义
IN
等于列表中的任何一个
ALL
和子查询返回的所有值进行比较
ANY
和子查询返回的任一值进行比较
a、在多行子查询中使用IN操作符
示例:查询工作地点在NEW YORK和CHICAGO的部门所对应的员工信息。
SQL> select * from emp where deptno in (select deptno from dept where loc='NEW YORK' or loc = 'CHICAGO'); EMPNO ENAME JOB MGR HIREDATE SAL COMM DEPTNO 7934 MILLER CLERK 7782 23-1月 -82 1300 10 ...... 7698 BLAKE MANAGER 7839 01-5月 -81 2850 30 7654 MARTIN SALESMAN 7698 28-9月 -81 1250 1400 30 已选择9行。b、在多行子查询中使用ALL操作符
示例:查询高于30号部门所有员工工资的员工名、工资和部门号。
SQL> select ename, sal, deptno from emp where sal > all(select sal from emp where deptno = 30); ENAME SAL DEPTNO JONES 2975 20 EASON 3000 20 FORD 3000 20 SCOTT 3000 20 KING 5000 10c、在多行子查询中使用ANY操作符
示例:查询高于10号部门任意一个员工工资的员工名、工资和部门号。
SQL> select ename, sal, deptno from emp where sal > any (select sal from emp where deptno = 10); ENAME SAL DEPTNO KING 5000 10 EASON 3000 20 ...... ALLEN 1600 30 TURNER 1500 30 已选择9行。5、Oracle的子查询需要注意的问题
a、不可以在group by子句中使用子查询。
示例:select avg(sal) from emp group by (select deptno from emp);
SQL> select avg(sal) from emp group by (select deptno from emp); select avg(sal) from emp group by (select deptno from emp) 第 1 行出现错误: ORA-22818: 这里不允许出现子查询表达式b、在TOP-N分析问题中,需对子查询排序
示例:显示员工信息表中工资最高的前五名员工。
SQL> select rownum, empno, ename, sal from (select * from emp order by sal desc) where rownum <= 5; ROWNUM EMPNO ENAME SAL 1 7839 KING 5000 2 7951 EASON 3000 3 7902 FORD 3000 4 7788 SCOTT 3000 5 7566 JONES 2975c、单行子查询的空值问题
示例:select ename, job, from emp where job = (select job from emp wehre ename = 'Ruby');
SQL> select ename, job from emp where job = (select job from emp where ename = 'Ruby'); 未选定行如果子查询返回到的是一个空值,那么主查询将不会查询到任何结果。
d、多行子查询的空值问题
示例:select * from emp where empno not in (select mgr from emp);
SQL> select mgr from emp; MGR 7566 null ...... 7839 7566 7698 已选择15行。 SQL> select * from emp where empno not in (select mgr from emp); 未选定行多行子查询中如果出现空值,则主查询将不会查询到任何结果。
SQL> select * from emp where empno not in (select mgr from emp where mgr is not null); EMPNO ENAME JOB MGR HIREDATE SAL COMM DEPTNO 7844 TURNER SALESMAN 7698 08-9月 -81 1500 0 30 7951 EASON ANALYST 7566 01-12月-17 3000 20 ...... 7934 MILLER CLERK 7782 23-1月 -82 1300 10 7900 JAMES CLERK 7698 03-12月-81 950 30 已选择9行。









