
最近用阿里的Druid的SQL parser来解析SQL语句。在此记录下研究:
调用它来解析出AST语意树一般这么写(针对MySQL):
MySqlStatementParser parser = new MySqlStatementParser(sql);
List<SQLStatement> statementList = parser.parseStatementList();
for(SQLStatement statement:statementList){
MySqlSchemaStatVisitor visitor = new MySqlSchemaStatVisitor();
statemen.accept(visitor);
}
对于每一个SQL请求(可能包含多语句),需要先新建一个MySqlStatementParser。注意,MySqlStatementParser 不是线程安全的,所以一种做法是针对每个session的请求,需要新建一个MySqlStatementParser。
那么这个初始化过程究竟是怎样的呢?涉及到哪些类?
涉及到的类如下所示: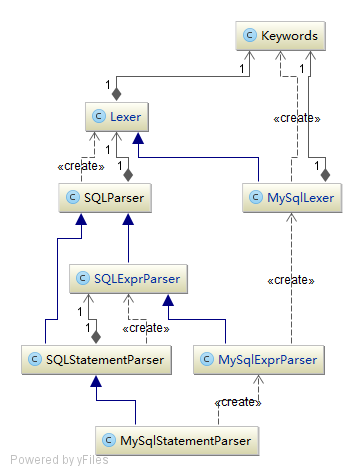
SQL解析可以分为三层:语句解析->表达式解析->词法解析。对应的主要类分别是MySqlStatementParser,MySqlExprParser,MySqlLexer。可以说,MySqlLexer是解析出每个词的词义,表达式由词组成,MySqlExprParser用来解析出不同表达式的含义。多个表达式和词组成完整的语句,这个由MySqlStatementParser解析。
首先看MySqlStatementParser的结构: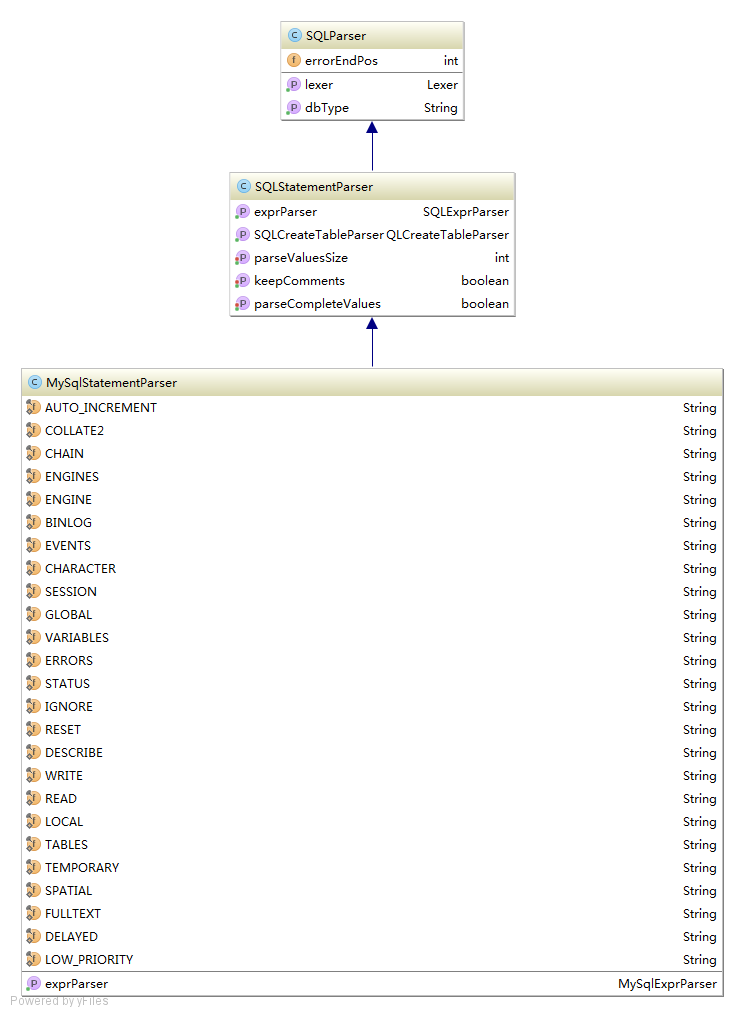
- SQLParser.java
- errorEndPos :解析出错记录位置
- lexer:词法解析
- dbType:数据库类型
- SQLStatement.java
- exprParser:表达式解析类
- SQLCreateTableParser:建表语句解析类,因为建表语句比较复杂,所以单拿出来。其他DDL语句都在本类SQLStatement中解析
- parseValuesSize:记录解析结果集大小
- keepComments:是否保留注释
- parseCompleteValues:是否全部解析完成
- MySqlStatementParser.java:
- 静态关键词:比如auto increment,collate等,对于DDL语句或者DCL语句
- exprParser:针对MySQL语句的parser
接着是MySqlStatementParser的MySqlExprParser的结构: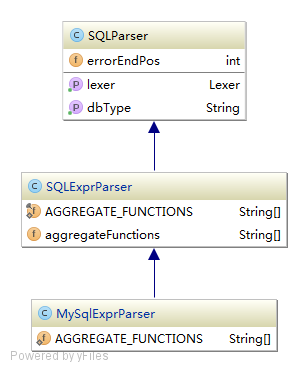
- SQLExprParser:
- AGGREGATE_FUNCTIONS:一些统计函数的关键词
- aggregateFunctions:保存统计函数的关键词
- MySqlSQLExprParser:
- AGGREGATE_FUNCTIONS:针对MySql统计函数的关键词
最后是MySqlLexer: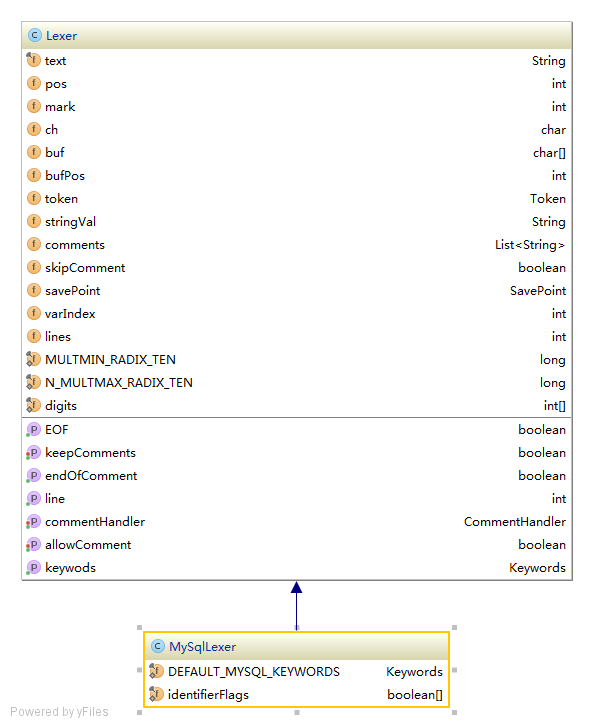
- Lexer:
- text:保存目前的整个SQL语句
- pos:当前处理位置
- mark:当前处理词的开始位置
- ch:当前处理字符
- buf:当前缓存的处理词
- bufPos:用于取出词的标记,当前从text中取出的词应该为从mark位置开始,mark+bufPos结束的词
- token:当前位于的关键词
- stringVal:当前处理词
- comments:注释
- skipComment:是否跳过注释
- savePoint:保存点
- varIndex:针对?表达式
- lines:总行数
- digits:数字ASCII码
- EOF:是否结尾
- keepComments:是否保留注释
- endOfComment:是否注释结尾
- line:当前处理行数
- commentHandler:注释处理器
- allowComment:是否允许注释
- KeyWords:所有关键词集合
新建MySqlStatementParser
初始化MySqlStatementParser:
MySqlStateMentParser.java:
public MySqlStatementParser(String sql){
super(new MySqlExprParser(sql));
}
会新建MySqlExprParser:
MySqlExprParser.java
public MySqlExprParser(String sql){
this(new MySqlLexer(sql));
//读取第一个有效词
this.lexer.nextToken();
}
会新建MySqlLexer:
MySqlLexer.java
public MySqlLexer(String input){
super(input);
//初始化MySQL关键词
super.keywods = DEFAULT_MYSQL_KEYWORDS;
}
Lexer.java
public Lexer(String input){
this(input, null);
}
/** * @param input 输入SQL语句 * @param commentHandler 注释处理器 */
public Lexer(String input, CommentHandler commentHandler){
this(input, true);
this.commentHandler = commentHandler;
}
/** * * @param input * @param skipComment 是否跳过注释 */
public Lexer(String input, boolean skipComment){
this.skipComment = skipComment;
this.text = input;
this.pos = -1;
//读取第一个字符
scanChar();
}
protected final void scanChar() {
ch = charAt(++pos);
}
初始化Lexer之后,回到MySqlExprParser的构造器,初始化KeyWords集合:
public final static Keywords DEFAULT_MYSQL_KEYWORDS;
static {
//MySQL关键词
Map<String, Token> map = new HashMap<String, Token>();
map.putAll(Keywords.DEFAULT_KEYWORDS.getKeywords());
map.put("DUAL", Token.DUAL);
map.put("FALSE", Token.FALSE);
map.put("IDENTIFIED", Token.IDENTIFIED);
map.put("IF", Token.IF);
map.put("KILL", Token.KILL);
map.put("LIMIT", Token.LIMIT);
map.put("TRUE", Token.TRUE);
map.put("BINARY", Token.BINARY);
map.put("SHOW", Token.SHOW);
map.put("CACHE", Token.CACHE);
map.put("ANALYZE", Token.ANALYZE);
map.put("OPTIMIZE", Token.OPTIMIZE);
map.put("ROW", Token.ROW);
map.put("BEGIN", Token.BEGIN);
map.put("END", Token.END);
// for oceanbase & mysql 5.7
map.put("PARTITION", Token.PARTITION);
map.put("CONTINUE", Token.CONTINUE);
map.put("UNDO", Token.UNDO);
map.put("SQLSTATE", Token.SQLSTATE);
map.put("CONDITION", Token.CONDITION);
DEFAULT_MYSQL_KEYWORDS = new Keywords(map);
}
Keywords.java:
public final static Keywords DEFAULT_KEYWORDS;
static {
Map<String, Token> map = new HashMap<String, Token>();
map.put("ALL", Token.ALL);
map.put("ALTER", Token.ALTER);
map.put("AND", Token.AND);
map.put("ANY", Token.ANY);
map.put("AS", Token.AS);
map.put("ENABLE", Token.ENABLE);
map.put("DISABLE", Token.DISABLE);
map.put("ASC", Token.ASC);
map.put("BETWEEN", Token.BETWEEN);
map.put("BY", Token.BY);
map.put("CASE", Token.CASE);
map.put("CAST", Token.CAST);
map.put("CHECK", Token.CHECK);
map.put("CONSTRAINT", Token.CONSTRAINT);
map.put("CREATE", Token.CREATE);
map.put("DATABASE", Token.DATABASE);
map.put("DEFAULT", Token.DEFAULT);
map.put("COLUMN", Token.COLUMN);
map.put("TABLESPACE", Token.TABLESPACE);
map.put("PROCEDURE", Token.PROCEDURE);
map.put("FUNCTION", Token.FUNCTION);
map.put("DELETE", Token.DELETE);
map.put("DESC", Token.DESC);
map.put("DISTINCT", Token.DISTINCT);
map.put("DROP", Token.DROP);
map.put("ELSE", Token.ELSE);
map.put("EXPLAIN", Token.EXPLAIN);
map.put("EXCEPT", Token.EXCEPT);
map.put("END", Token.END);
map.put("ESCAPE", Token.ESCAPE);
map.put("EXISTS", Token.EXISTS);
map.put("FOR", Token.FOR);
map.put("FOREIGN", Token.FOREIGN);
map.put("FROM", Token.FROM);
map.put("FULL", Token.FULL);
map.put("GROUP", Token.GROUP);
map.put("HAVING", Token.HAVING);
map.put("IN", Token.IN);
map.put("INDEX", Token.INDEX);
map.put("INNER", Token.INNER);
map.put("INSERT", Token.INSERT);
map.put("INTERSECT", Token.INTERSECT);
map.put("INTERVAL", Token.INTERVAL);
map.put("INTO", Token.INTO);
map.put("IS", Token.IS);
map.put("JOIN", Token.JOIN);
map.put("KEY", Token.KEY);
map.put("LEFT", Token.LEFT);
map.put("LIKE", Token.LIKE);
map.put("LOCK", Token.LOCK);
map.put("MINUS", Token.MINUS);
map.put("NOT", Token.NOT);
map.put("NULL", Token.NULL);
map.put("ON", Token.ON);
map.put("OR", Token.OR);
map.put("ORDER", Token.ORDER);
map.put("OUTER", Token.OUTER);
map.put("PRIMARY", Token.PRIMARY);
map.put("REFERENCES", Token.REFERENCES);
map.put("RIGHT", Token.RIGHT);
map.put("SCHEMA", Token.SCHEMA);
map.put("SELECT", Token.SELECT);
map.put("SET", Token.SET);
map.put("SOME", Token.SOME);
map.put("TABLE", Token.TABLE);
map.put("THEN", Token.THEN);
map.put("TRUNCATE", Token.TRUNCATE);
map.put("UNION", Token.UNION);
map.put("UNIQUE", Token.UNIQUE);
map.put("UPDATE", Token.UPDATE);
map.put("VALUES", Token.VALUES);
map.put("VIEW", Token.VIEW);
map.put("SEQUENCE", Token.SEQUENCE);
map.put("TRIGGER", Token.TRIGGER);
map.put("USER", Token.USER);
map.put("WHEN", Token.WHEN);
map.put("WHERE", Token.WHERE);
map.put("XOR", Token.XOR);
map.put("OVER", Token.OVER);
map.put("TO", Token.TO);
map.put("USE", Token.USE);
map.put("REPLACE", Token.REPLACE);
map.put("COMMENT", Token.COMMENT);
map.put("COMPUTE", Token.COMPUTE);
map.put("WITH", Token.WITH);
map.put("GRANT", Token.GRANT);
map.put("REVOKE", Token.REVOKE);
// MySql procedure: add by zz
map.put("WHILE", Token.WHILE);
map.put("DO", Token.DO);
map.put("DECLARE", Token.DECLARE);
map.put("LOOP", Token.LOOP);
map.put("LEAVE", Token.LEAVE);
map.put("ITERATE", Token.ITERATE);
map.put("REPEAT", Token.REPEAT);
map.put("UNTIL", Token.UNTIL);
map.put("OPEN", Token.OPEN);
map.put("CLOSE", Token.CLOSE);
map.put("CURSOR", Token.CURSOR);
map.put("FETCH", Token.FETCH);
map.put("OUT", Token.OUT);
map.put("INOUT", Token.INOUT);
DEFAULT_KEYWORDS = new Keywords(map);
}
之后,回到构造MySqlStatementParser:
调用父类方法初始化:
SQLStatementParser.java
public SQLStatementParser(SQLExprParser exprParser){
super(exprParser.getLexer(), exprParser.getDbType());
this.exprParser = exprParser;
}
SQLParser.java
public SQLParser(Lexer lexer, String dbType){
this.lexer = lexer;
this.dbType = dbType;
}
至此,初始化完成










